最近,我在翻阅两本比较新的 Python 书籍时,发现它们都犯了一个严重的低级错误!
这两本书分别是《Python编程:从入门到实践》和《父与子的编程之旅》,它们都是畅销书,都在 2020 年 10 月出了新版本,都使用 Python3.7+ 版本的语法。

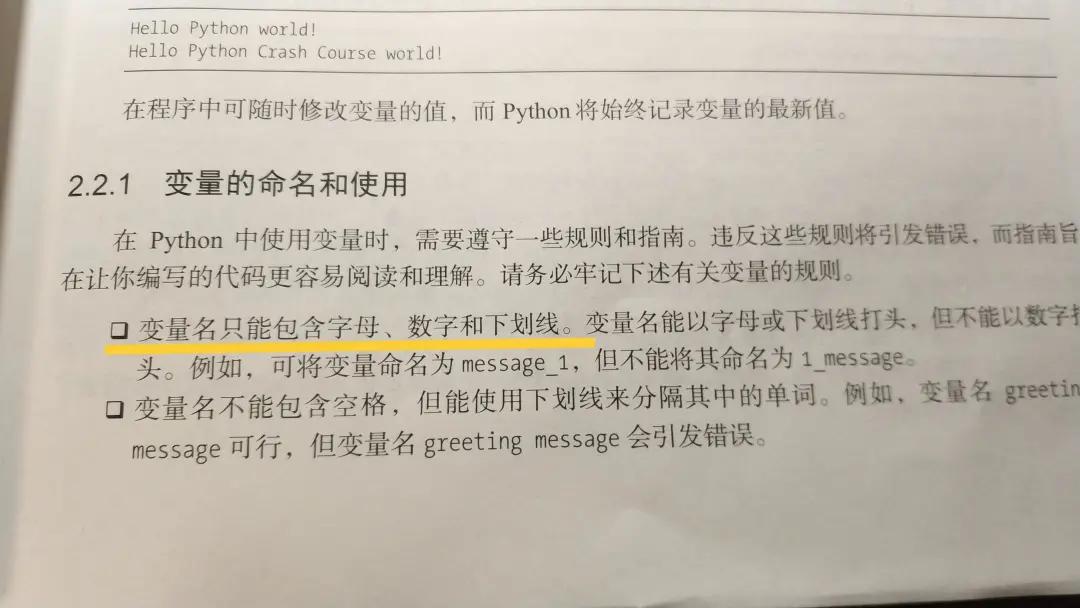
然而,在关于变量的命名规则部分,它们犯下了一样的错误,即还在使用 Python2 时代的那套说辞,误以为命名仅仅支持“字母、数字和下划线”的组合。
事实上,Python3.x 已经支持全面 Unicode 编码,比如支持使用中文作为变量名。
- >>> 姓名 ="Python猫"
- >>> print(f"我是{姓名},欢迎关注!")
- 我是Python猫,欢迎关注!
由于我手头上没有其它样本,所以,我不确定有多少新版的书籍还在使用老的规则。但是,翻译类的书籍大概率都会有这样的问题,另外,有些不严谨的国内书籍,也可能因为借鉴了过时的材料而犯错。
如此一来,恐怕有些新接触 Python 的同学,就会形成错误的认识。虽然这可能不会造成严重的问题,但是它终归是一个应该避免而且很容易就能避免的问题。
因此,我觉得这个话题值得聊一聊。
在编程语言中有一个很常见的概念,即标识符(identifier),通常又会称之为名字(name),用于标识出变量、常量、函数、类、符号等实体的名字。
在定义标识符时,有一些必须要考虑的基本规则:
- 它可以由哪些字符组成?
- 它是否区分大小写?(即大小写敏感)
- 它是否允许出现某些特殊的单词?(即关键字/保留字)
对于第一个问题,大多数的编程语言在早期版本都遵循这条规则:标识符由字母、数字和下划线组成,并且不能以数字为开头。 少数的编程语言有例外,还支持使用$、@、%等特殊符号(例如PHP、Ruby、Perl等等)。
Python 的早期版本,确切地说是 3.0 之前的版本,就遵循以上的命名规则。下面是官方文档中的描述:
- identifier ::= (letter|"_") (letter | digit | "_")*
- letter ::= lowercase | uppercase
- lowercase ::= "a"..."z"
- uppercase ::= "A"..."Z"
- digit ::= "0"..."9"
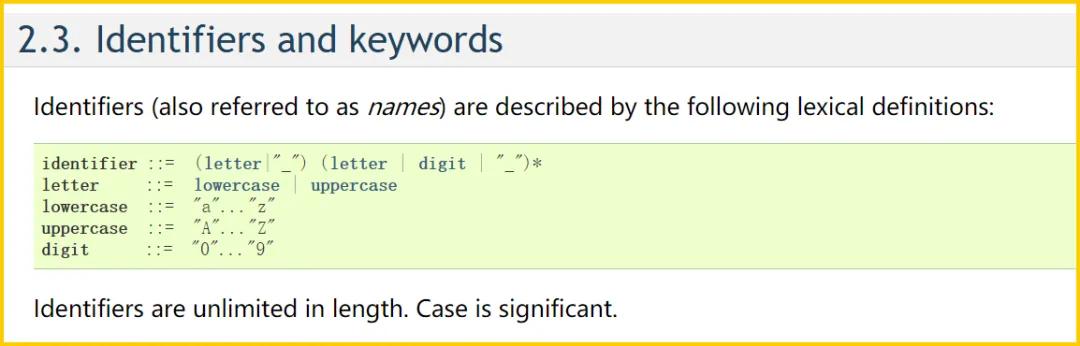
出处:https://docs.python.org/2.7/reference/lexical_analysis.html#identifiers
但是,这条规则从 3.0 版本起,就被打破了。最新的官方文档已经变成了这样:
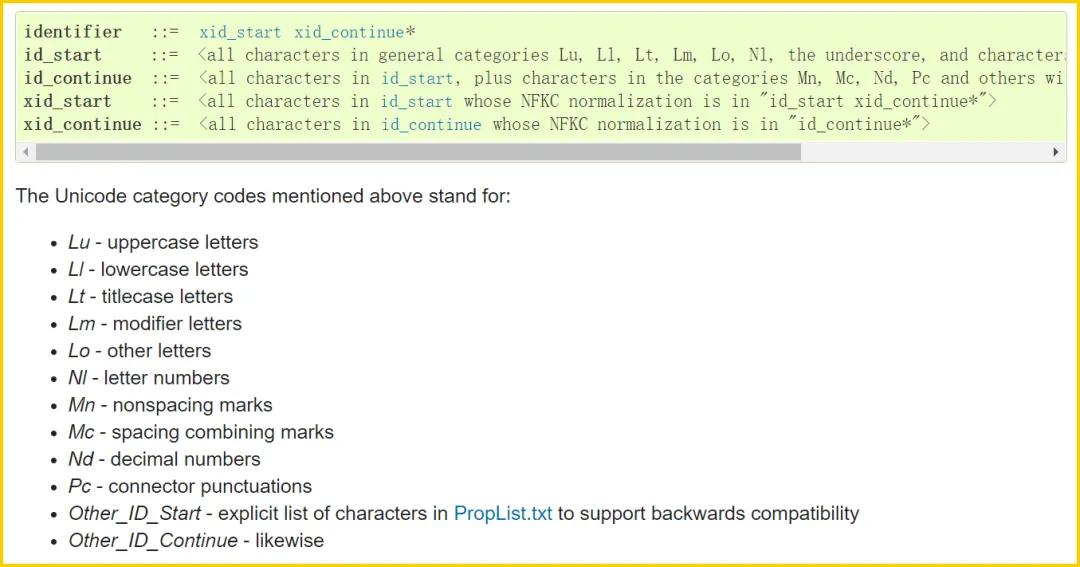
出处:https://docs.python.org/3/reference/lexical_analysis.html#identifiers
随着互联网的普及,各国语言进入了国际化的语境中,编程语言也与时俱进地增长了对国际化的诉求。
Unicode(译作统一码、万国码)编码标准在 1994 年发布,随后逐步被主流的编程语言所接纳。到目前为止,至少有 73 种编程语言支持 Unicode 变量名(数据依据:https://rosettacode.org/wiki/Unicode_variable_names)。
2007 年,当 Python 正在设计划时代的 3.0 版本时,官方也考虑了对 Unicode 编码的支持,于是,诞生了重要的《PEP 3131 -- Supporting Non-ASCII Identifiers》。

出处:https://www.python.org/dev/peps/pep-3131
事实上,除了我们最关心的中文,Unicode 字符集还包含非常非常多的内容。
在对变量命名时,下面这些用法都是可行的(谨慎使用,如若被打,本猫概不负责……):
- >>> ψ = 1
- >>> Δ = 1
- >>> ಠ_ಠ = "hello"
综上所述,某些 Python 书籍中关于变量命名规则的内容已经过时了,不应该被其所误导!
Python 3 作为一门面向现代化/国际化的语言,对于 Unicode 编码有很好的支持。至于该不该在项目中使用中文给标识符命名,那就是另外的问题啦……
本文转载自微信公众号「 Python猫」,可以通过以下二维码关注。转载本文请联系 Python猫公众号。