我在去年写的两篇专栏文章中已经介绍过多线程(threading)和异步IO(asyncio),并向大家举例讲解了网工要如何将它们应用在我们平常的网络运维中来提升Python脚本的工作效率。这篇文章来介绍下另外一个可以实现并发编程的Python标准库:concurrent.futures。
基本概念
网工在自学Python的时候肯定或多或少听说过同步(Synchronous)、异步(Asynchronous)、单线程(Single Threaded)、多线程(Multi Threaded)、多进程(Multiprocessing)、多任务(Multitasking) 、并发(Concurrent)、并行(Parallesim)、协程(Coroutine)、I/O密集型(I/O-bound)、CPU密集型(CPU-bound)等术语,如何区分它们对学习Python的网工来说是一个难点,开篇讲concurrent.futures之前先把上述这些术语之间的关系和区别给大家大致捋一下:
1. 同步(Synchronous) VS 异步(Asynchronous)
所谓同步,可以理解为每当系统执行完一段代码或者函数后,系统将一直等待该段代码或函数返回的值或消息,直到系统接收到返回的值或消息后才继续往下执行下一段代码或者函数,在等待返回值或消息的期间,程序处于阻塞状态,系统将不做任何事情。而异步则恰恰相反,系统在执行完一段代码或者函数后,不用阻塞性地等待返回的值或消息,而是继续执行下一段代码或函数,在同一时间段里执行多个任务(而不是傻傻地等着一件事情做完并且直到结果出来了以后才去做下件事情),将多个任务并发(注意不是并行),从而提高程序的执行效率。如果你有读过数学家华罗庚的《统筹方法》,一定不会对其中所举的例子感到陌生:同样是沏茶的步骤,因为烧水需要一段时间,你不用等水煮沸了过后才来洗茶杯、倒茶叶(类似“同步”),而是在等待烧水的过程中就把茶杯洗好,把茶叶倒好,等水烧开了就能直接泡茶喝了,这里烧水、洗茶杯、倒茶叶三个任务是在同一个时间段内并发完成的,这就是一种典型的“异步”。对我们网工来说,paramiko, netmiko, telnetlib, pexpect, ciscolib等第三方模块默认都是基于同步的,基于异步的模块有asyncio, asyncping, netdev等等(pexpect也支持异步,但是必须手动调,默认状态下是同步)。
2. 线程(Thread) VS 进程(Process)
所谓线程是指操作系统能够进行运算调度的最小单位。线程依托于进程存在,是进程中的实际运作单位,一个进程可以有多个线程,每条线程可以并发执行不同的任务。
3. 单线程(Single Threaded) VS 多线程 (Multi Threaded)
我们也可以引用同样的例子来说明单线程和多线程的区别。在上面讲到的华罗庚《统筹方法》里沏茶的这个例子中,如果只有一个人来完成烧水、洗茶杯、倒茶叶三项任务的话,因为此时只有一个劳动力,我们就可以把它看成是单线程(同步、异步IO都是基于单线程的)。假设我们能找来三个人分别负责烧水、洗茶杯、倒茶叶,那我们就可以把它看成是多线程,每一个劳动力代表一个线程,但是由于多线程的Global Interpreter Lock机制(俗称的GIL全局锁)的存在,实际上这三个劳动力并不是同时开工的,从并发的性能和效率的角度来看,多线程实际上是弱于基于单线程的异步IO的,这点我们已经在之前的两篇文章里通过实验验证了。
讲到单线程和多线程,还需要讲下异步IO和多线程之间的区别:
- 异步IO是单线程,而多线程顾名思义就是多线程。
- 异步IO和多线程的区别在于它们的机制不一样,多线程使用的是抢占式多任务处理(Pre-emptive Multitasking) 。在这种抢占式环境下,操作系统本身具有掌控所有任务(也就是程序)的能力,能随心所欲地剥夺每个任务的时间片来提供给其他任务,也就是有一个幕后大boss掌控一切。而异步IO的机制为协作式多任务处理(Cooperative Multitasking), 这种机制没有幕后大boss,在协作式环境下,每个任务被调度的前提是当前任务主动放弃时间片。
- 异步IO的核心是协程(Coroutine),这个是多线程不具备的。协程是一种轻量级线程,它是一种特殊的生成器函数,它可以在return语句被执行前停止该函数当前正在执行的任务,并且能在一段时间内间接地将执行权交给另外一个协程函数。协程强调的是合作,而不是多线程强调的抢占,asyncio是Python中唯一支持协程的标准库。
4. 并发(Concurrent) VS 并行 (Parallesim)
并发是一个笼统的概念,在Python里,在逻辑上同时发生的任务有多种称谓:多线程,异步IO(多任务),多进程,它们都是并发的一种。深入地说,只有调用多核CPU的多进程(Multiprocessing)是用来处理在物理上同时发生的任务的,这个叫并行。基于单核CPU的多线程和异步IO(多任务)同一时间内只能处理一件事件(但是它们有自己独特的机制来加快处理不同事件的能力),这个叫做并发。
借用某知乎网友举的例子来说明同步、并发、并行三者之间的区别。
当你吃饭的时候突然有人给你打电话,如果此时你:
- 不接听电话,继续吃饭,等把饭吃完过后再来回电话,这个叫做同步。
- 接听电话后放下筷子停止进食,等通话完毕后再接着吃,这个叫做并发。
- 接听电话的同时继续进食,这个叫做并行。
综上,并行是并发的一种,但是并发并不等于并行。
5. I/O密集型(I/O bound) VS CPU密集型(CPU bound)
I/O密集型(I/O bound) 是指不会特别消耗 CPU 资源,但是I/O比较频繁的任务和操作,比如文件的读写、网络通信、数据库访问等等。
CPU密集型(CPU bound)是指需要大量耗费CPU资源的任务和操作,比如计算、解压缩、加密解密等等。
异步和多线程适合I/O密集型场景, 多进程适合CPU密集型场景。
上述内容可以归纳总结成下表:
- 并发类型切换机制CPU数量适用场景代表Python库多线程(抢占式多任务处理)操作系统决定何时切换任务1个I/O密集型_thread(已淘汰), threading,
- cocurrent.futures, nornir异步(协作式多任务处理)任务本身决定何时切换1个I/O密集型asyncio, netdev, aiohttp, aioping, gevent,
- tornado, twisted多进程 (并行)所有任务同时运行多个CPU密集型multiprocessing
好了,说了那么多下面进入本篇正文:concurrent.futures。
什么是Concurrent.futures
Concurrent.futures是Python中的一个标准库,顾名思义它是并发编程的一种,根据Python官方的定义,concurrent.futures是一种高级接口,它同时融合了多线程和多进程的特点,并将两者简化。Concurrent.futures从Python3.2中被引入,它的诞生时间晚于threading和multiprocessing两个标准库,但是早于诞生于Python3.4的asyncio标准库。
Future对象
在concurrent.futures中引入了future这个对象,关于future的中文翻译目前为止我听说过未来、期程等,但还没有一个统一的说法(Python中文官方文档上也没有说明),所以这里我们还是用future来讲。
主线程(或进程)可以通过future对象获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值。
执行器对象
Concurrent.futures中还有一个重要的对象叫做执行器(Executor),分为ThreadPoolExecutor和ProcessPoolExecutor两种,你基本可以把它俩看成是multiprocessing库中的线程池和进程池(支持多进程的multiprocessing标准库以前没讲过,我准备下篇文章中再讲),前面提到了,concurrent.futures相较于multiprocessing以及threading两个库来说它的优势在于其语法更简单,学习成本更低。
理论的东西先讲到这里,接下来直接做实验说明concurrent.futures怎么用,为了做对比,我会用单线程同步、threading、concurrent.futures分别举三个例子。首先来看最原始的单线程同步:
1. 单线程同步实验:
- import time
- def do_something():
- print ('休眠1秒')
- time.sleep(1)
- start_time = time.perf_counter()
- do_something()
- do_something()
- end_time = time.perf_counter()-start_time
- print (f'总共耗时{round(end_time, 2)}秒')
这里我们自定义一个叫做do_something()的函数,它的任务很简单,就是打印出内容“休眠1秒”,然后使用time.sleep(1)来让程序休眠1秒。然后我们调用两次do_something()函数,打印出耗时,因为是单线程同步,所以两次执行do_something()的总耗时为2.01秒。
2. Threading实验
- import threading
- import time
- def do_something():
- time.sleep(1)
- start_time = time.perf_counter()
- threads = []
- for i in range(1,11):
- t = threading.Thread(target=do_something, name=f'线程{str(i)}')
- print (f'{t.name}开始运行')
- print ('休眠1秒')
- t.start()
- threads.append(t)
- for thread in threads:
- thread.join()
- end_time = time.perf_counter()-start_time
- print (f'总共耗时{round(end_time, 2)}秒')
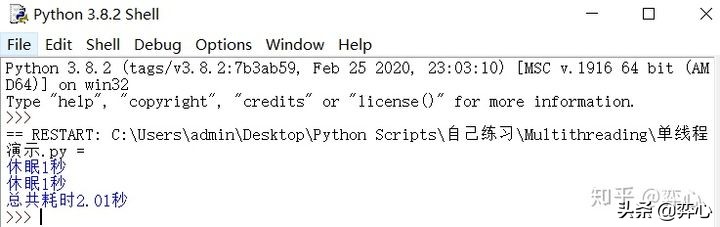
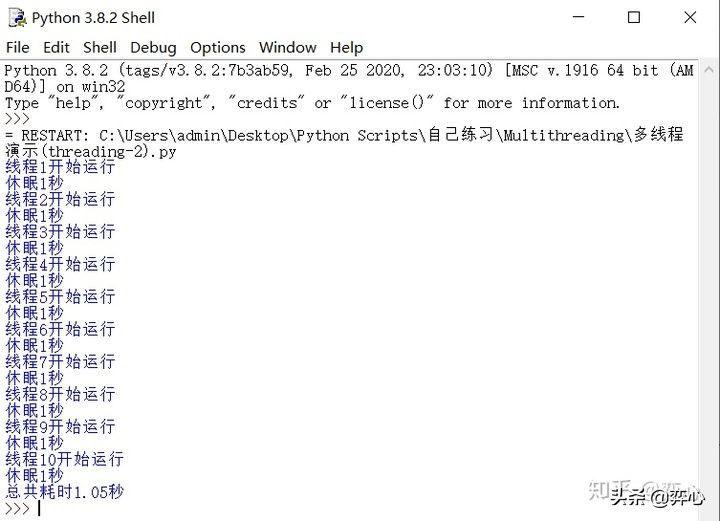
这里我们用threading来总共执行10次do_something(),如果按单线程同步的方法的话,总计会耗费10秒+才能完成,而通过threading模块我们使用多线程让这10次do_something()并发执行,所以仅仅只用到了1.05秒便宣告完成。
3. Concurrent.futures实验(分为三种代码)
因为涉及到不同的知识点,Concurrent.futures实验的代码我将分三种来写,首先来看第一段代码:
- from concurrent.futures import ThreadPoolExecutor
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完毕'
- start_time = time.perf_counter()
- executor = ThreadPoolExecutor()
- f1 = executor.submit(do_something, 1)
- f2 = executor.submit(do_something, 1)
- print (f1.result())
- print (f2.result())
- print (f'task1是否完成: {f1.done()}')
- print (f'task2是否完成: {f1.done()}')
- end_time = time.perf_counter()-start_time
- print (f'总共耗时{round(end_time,2)}秒')
代码讲解(只讲和concurrent.futures有关的知识点):
这里我们使用from concurrent.futures import ThreadPoolExecutor来调用concurrent.futures的线程池处理器对象
- from concurrent.futures import ThreadPoolExecutor
这里注意我们在do_something()函数后面加了参数seconds,并在最后面加了一个return '休眠完毕',它们的作用等会儿会讲到:
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完毕'
在concurent.futures中,ThreadPoolExecutor是Executor下面的两个子类之一(另一个是ProcessPoolExecutor),它使用线程池来执行异步调用,这里我们将ThreadPoolExecutor()赋值给一个叫做executor的变量。
- executor = ThreadPoolExecutor()
然后我们使用ThreadPoolExecutor下面的submit()函数来创建线程,submit()函数中包含了要调用的任务,即do_something(),以及该函数要调用的参数(也就是dosmeting()里面的seconds),这里我们放1,表示休眠一秒钟,所以写成submit(do_something, 1),因为submit()函数返回的值为future类型的对象,所以这里我们把future简写为f, 分别赋值给f1和f2两个变量,表示并发执行两次do_something()函数。
- f1 = executor.submit(do_something, 1)
- f2 = executor.submit(do_something, 1)
前面讲到了,future对象的作用是帮助主线程(或进程)获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值,为了向大家演示,这里我对f1和f2两个future对象分别调用了result()和done()两个函数并将它们的结果打印出来。
- print (f1.result())
- print (f2.result())
- print (f'task1是否完成: {f1.done()}')
- print (f'task2是否完成: {f1.done()}')
在future中,result()的作用是告知你任务走到了哪一步,是否有异常,如果任务没有异常正常完成的话,那么result()会返回自定义函数下面return的内容(也就是我们do_someting()最下面的return'休眠完毕'),如果任务执行过程中遇到异常 ,那么result()则会返回异常的具体内容。 done()则返回一个布尔值,来告诉你任务是否完成,如果完成,则返回True,反之则返回False。
接下来看脚本运行效果:
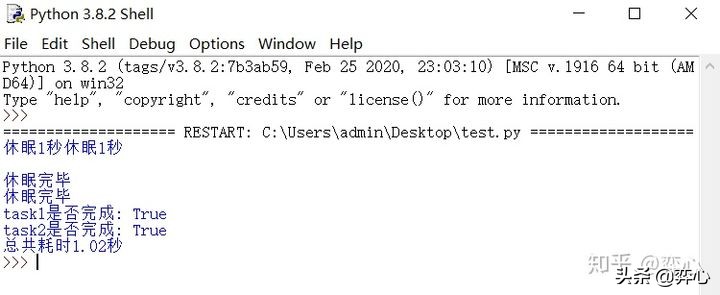
可以看到同步需要2秒+完成的两次任务通过concurrent.futures缩短为1.02秒完成(这个时间不定,如果你多跑脚本几次,你会看到1.01秒,1.02秒,1.03秒,1.04秒等几种,这个和当前电脑的性能有关系)。注意这里的两个“休眠完毕”是print (f1.result()) 和print (f2.result())打印出来的, “task1是否完成: True”和“task2是否完成: True”是 print (f'task1是否完成: {f1.done()}')和print (f'task2是否完成: {f1.done()}')打印出来的。
接下来我们再看concurrent.futures的第二段实验代码:
- from concurrent.futures import ThreadPoolExecutor, as_completed
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完毕'
- start_time = time.perf_counter()
- executor=ThreadPoolExecutor()
- results = [executor.submit(do_something, 1) for i in range(10)]
- for f in as_completed(results):
- print (f.result())
- end_time = time.perf_counter()-start_time
- print (f'总共耗时{round(end_time,2)}秒')
代码讲解(只讲和concurrent.futures有关的知识点):
这里我们从concurrent.futures中新导入了一个函数叫做as_completed,它的作用后面会讲到。
- from concurrent.futures import ThreadPoolExecutor, as_completed
第一段代码缺乏灵活性,因为我们是通过手动的方式创建了f1和f2两个线程,如果我们要并发运行do_something()这个任务100次,显然我们不可能去手动创建f1, f2, f3......f100这100个变量。这里我们可以用list comprehension的方式创建一个列表,让do_something()这个函数并发运行10次。
- results = [executor.submit(do_something, 1) for i in range(10)]
在concurrent.futures中,as_completed(fs)函数的作用是针对给定的 future 迭代器 fs,在其完成后,返回完成后的迭代器(类型仍然为future)。这里的fs即为我们创建的列表results。因为concurrent.futures.as_completed(results)返回的值是迭代器,因此我们可以使用for循环来遍历它,然后对其中的元素(均为future类型)调用前面讲到的result()函数并打印
- for f in as_completed(results):
- print (f.result())
执行代码看效果,可以看到10次do_something()任务1.06秒便完成了。

concurrent.futures的第三段实验代码:
- from concurrent.futures import ThreadPoolExecutor
- import time
- def do_something(seconds):
- print (f'休眠{seconds}秒')
- time.sleep(seconds)
- return '休眠完毕'
- start_time = time.perf_counter()
- executor=ThreadPoolExecutor()
- sec = [5,4,3,2,1]
- results = executor.map(do_something, sec)
- for result in results:
- print (result)
- end_time = time.perf_counter()-start_time
- print (f'总共耗时{round(end_time,2)}秒')
代码讲解(只讲和concurrent.futures有关的知识点):
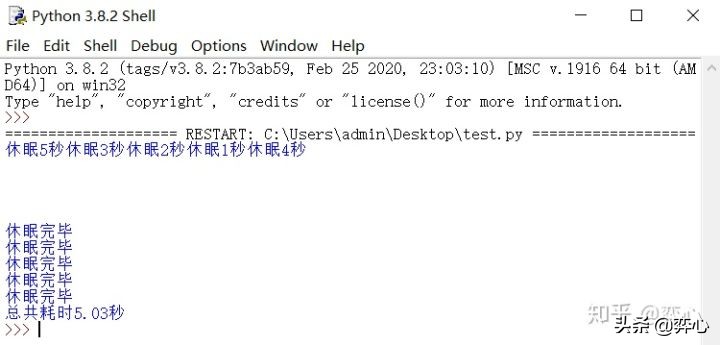
- 除了通过list comprehension来指定N次并发运行do_something(seconds)外,我们还可以通过concurrent.futures.ThreadPoolExecutor()下面的map()函数来达到目的,map()函数和submit()函数的用法类似,都可以用来创建线程,然后并发执行任务并返回future对象,但是它比submit()函数更灵活。它们的区别是:map()函数传入的第二个参数为一个可遍历的对象,这个可遍历的对象里的元素可以用来作为函数的参数。比如说这里我们定义了sec = [5,4,3,2,1]这个列表,该列表作为map()函数的第二个参数被传入(executor.map(do_something, sec)),因为该列表总共有5个元素,因此我们这里创建并且并发了5个线程来分5次执行do_something(seconds),第一次列表中的元素5作为参数被传入do_something(seconds), 也就是第一个线程执行后将休眠5秒,第二次列表中的元素4作为参数被传入do_something(seconds), 也就是第二个线程执行后将休眠4秒,以此类推。
- executor=ThreadPoolExecutor()
- sec = [5,4,3,2,1]
- results = executor.map(do_something, sec)
接下来看脚本运行效果:因为5次任务是并发执行的,所以程序消耗了5秒,4秒,3秒,2秒,1秒中的最大值,总共耗时5.03秒完成。