












本文转载自微信公众号「jinjunzhu」,作者jinjunzhu。转载本文请联系jinjunzhu公众号。
在单体数据库时代,数据库本身就支持ACID事务,开发人员甚至只要在方法上加一个@Transactional注解就可以搞定事务了,非常简单。但是到了分库分表和分布式数据库时代,传统数据库的ACID属性只能在单节点上起作用,全局事务需要一个全局的事务管理器来维护,复杂性很高。
而在分布式事务领域,全局事务使用的最多的指导方案就是2PC,也叫两阶段提交,但是2PC也有一些缺陷,今天我们就来看看分布式数据库是怎么对这些缺陷做优化的。
两阶段提交(2PC)
两阶段提交协议主要有2种,一种是应用层的TCC,比如阿里巴巴的seata就实现了TCC模式,这种模式的特点是每个服务都需要提供try/confirm/cancel这3个实现,这3个实现需要在业务代码中实现,对业务侵入高。
今天我分享的是面向资源的2PC协议,最早由Jim Gray提出,整个事务分为2个阶段,prepare阶段和commit阶段,这2个阶段由协调节点和DB资源管理器协作完成。
这里我们还是以经典的电商系统为例,整个系统分为订单、账户和库存3个服务,我们收到客户的购买请求后,协调节点需要协调订单服务生成订单,账户服务扣减商品款,库存服务扣减商品库存,假如这3个服务的数据库在不同切片上,这个协调过程具体如下:
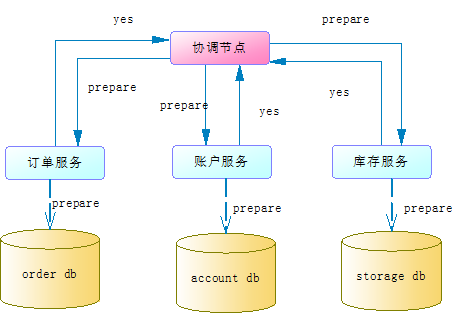
1.prepare阶段
协调节点向所有服务发送prepare请求,每个服务收到prepare请求后会尝试执行本地事务,但不会真正提交本地事务。这个尝试执行的过程会检查到是否具备执行事务的条件,比如资源是否被锁定等,当所有服务都尝试执行成功后会给协调节点返回一个yes,如下图:
2.commit/rollback阶段
如果prepare阶段所有服务有返回了yes,那么协调节点就会通知各个服务执行commit操作,这时各个服务就会真正的提交本地事务。如下图:
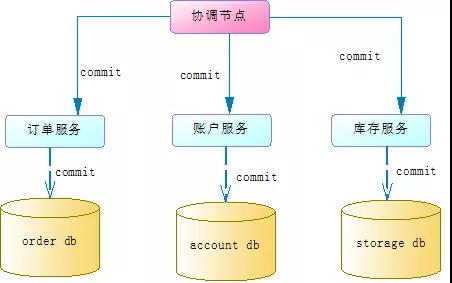
如果prepare阶段有服务返回了no,协调节点就需要通知所有服务进行本地事务回滚。
2PC存在问题
上面我们简单地分析了2PC协议的执行过程,那么2PC有什么问题呢?
1.性能问题
本地事务在prepare阶段锁定资源,比如账户服务要扣减xiaoming这个账户的金额100元,那必须把xiaoming这个账户先锁定。这样如果有其他事务也要修改xiaoming这个账户,就必须等待前面的事务完成。这样就造成了延迟和性能下降。
2.协调节点单点故障
协调节点是单节点的,如果发生故障,整个事务会一直阻塞。比如第一个阶段prepare成功了,但是第二个阶段协调节点发出commit指令之前宕机了,所有服务的数据资源处于锁定状态,后面的事务只能等待。
3.数据不一致
如果第一阶段prepare成功了,但是第二阶段commit的时候,如果协调节点通知库存服务失败了,这样就相当于生成了订单,扣减了账户,但是没有扣减库存。这导致了数据的不一致。
Percolator模型
主流的NewSQL数据库,比如TiDB,是用Percolator模型来解决的。如下官网链接:
https://pingcap.com/blog-cn/percolator-and-txn/
- 1.
Percolator模型来自于Google论文:
《Large-scale Incremental Processing Using Distributed Transactions and Notifications》
- 1.
原文可以看下面连接,网上也有好多翻译版的:
https://www.cs.princeton.edu/courses/archive/fall10/cos597B/papers/percolator-osdi10.pdf
- 1.
Percolator的前提是本地事务的数据库支持多版本并发控制协议,也就是mvcc。现在主流数据库比如mysql、oracle都是支持的。
a)初始阶段
还是看上面我们提到的经典电商案例,初始阶段,我们假设订单数量是0,账户服务是1000,库存服务是100,客户下了1个订单后,订单服务增加1个订单,账户服务扣除金额100,库存服务扣除商品数量1。各个切片的初始数据如下表:

":"前面的是时间戳或者数据版本,后面是数据值。这3张表中,第一条记录不保存真正的数据,而是保存了指向真正数据的指针,比如订单表中,6这个版本的数据指向了5个版本的数据,订单数量是0。
b)prepare阶段
在prepare阶段,协调节点向每个服务发送了prepare命令,这3张表分别进入了prepare阶段。在prepare阶段,Percolator定义了主锁的概念,每个分布式事务只能有一个服务获得主锁,比如本案例的订单服务,其他服务的锁指向这个主锁的指针,如下表:
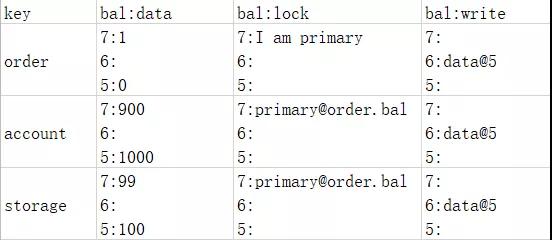
prepare阶段,每个服务会写日志,并且根据时间戳记录事务的私有版本,这样其他事务就不能操作这三条数据了。
c)commit阶段
在commit阶段,协调节点只需要跟订单服务通信,因为订单服务拥有primary lock,也就是说协调节点只跟拥有primary lock的切片通信。这时数据如下表:

这时我们注意到除了order服务的锁没有了,而且增加了版本8指向版本7,说明订单服务已经没有私有版本了,但是账户服务和库存服务的私有版本还在。Percolator的独特之处就是在这里,它会启动异步线程来更新账户服务和库存服务。最终数据如下表:
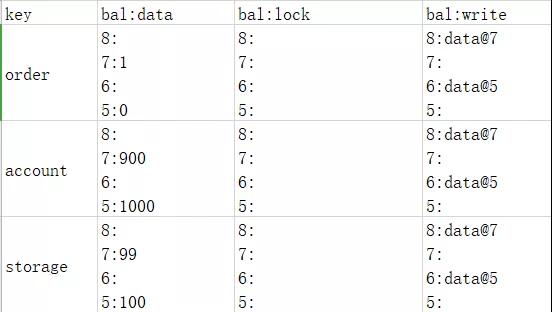
因为协调节点只需要跟获取primary lock的切片进行通信,要么成功要么失败这样就避免了commit时节点不能全部成功导致的数据不一致问题。
而prepare阶段记录了日志,如果某个切片commit失败,可以根据日志进行再次commit,这样就保证了数据最终一致。
如果协调节点宕机了,异步线程可以做资源的释放工作,避免了因单点故障通信失败造成的资源不能释放。
这里我们要注意2点:
- primary lock的选择是随机的,比如本例中并不一定会选择订单服务
- 协调节点发送commit后订单服务先提交成功,这时如果其他事务要读取账户服务和库存服务的2条数据,虽然2条数据上面还有lock,但是查找primary@order.bal发现已提交,所以是可以读取的。
总结
2PC协议有3个问题,性能问题、单点故障和数据不一致。
Percolator模型简化了协调节点和切片的通信流程,让协调节点只跟其中一个primary切片通信,一方面,减少了通信开销,另一方面,避免了因为单点故障,commit阶段部分节点通信失败导致的数据不一致问题。
Percolator在prepare阶段记录了日志,这样即使协调节点故障了,恢复后也可以根据日志来做事务恢复。
Percolator使用异步线程来做资源的释放工作,这样即使协调节点故障了,也不用担心资源得不到释放。
知名的NewSQL数据库TiDB就是参照Percolator模型来对2PC协议进行优化的。
但是我们要知道,2PC的性能问题还是存在的,好在主流的分布式数据库都做了优化,性能损耗只会越来越小。



























