目录
- 一、元组和列表
- 1.元组和列表的性能分析
- 2.为什么列表在 Python 中是最常用的呢?
- 3.timeit 里面有个 Timer 类
- 4.timeit 里面还有个直接用的 timeit 的方法,timeit.timeit()
- 5.这 2 个方法有啥区别?
- 二、命名元组
- 三、命名元组有什么特点?
一、元组和列表

元组vs列表
1.元组和列表的性能分析
元组和列表用来存储数据,在元组和列表里面查询的时候,到底哪个更快呢?
计算创建元组和列表所需的时间:ipython 中使用timeit这个命令。
计算时间模块介绍:
import timeit
#timeit.timeit
- 1.
- 2.
可以用这个模块来测试函数的性能。
安装 ipython:pip install ipython
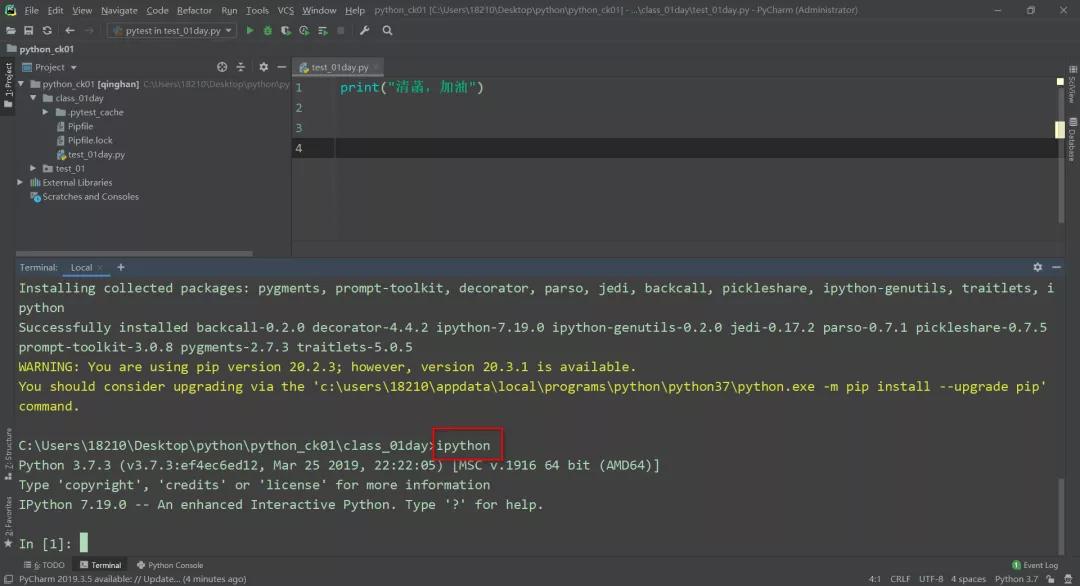
ipython 是个交互环境,就跟我们输入 Python 进去是一样的。只不过它外面做了一层封装,比 Python 交互环境更好用一点。
ipython 里面有一个命令叫做timeit,后面可以跟一个 Python 表达式。
例如定义一个列表在后面:
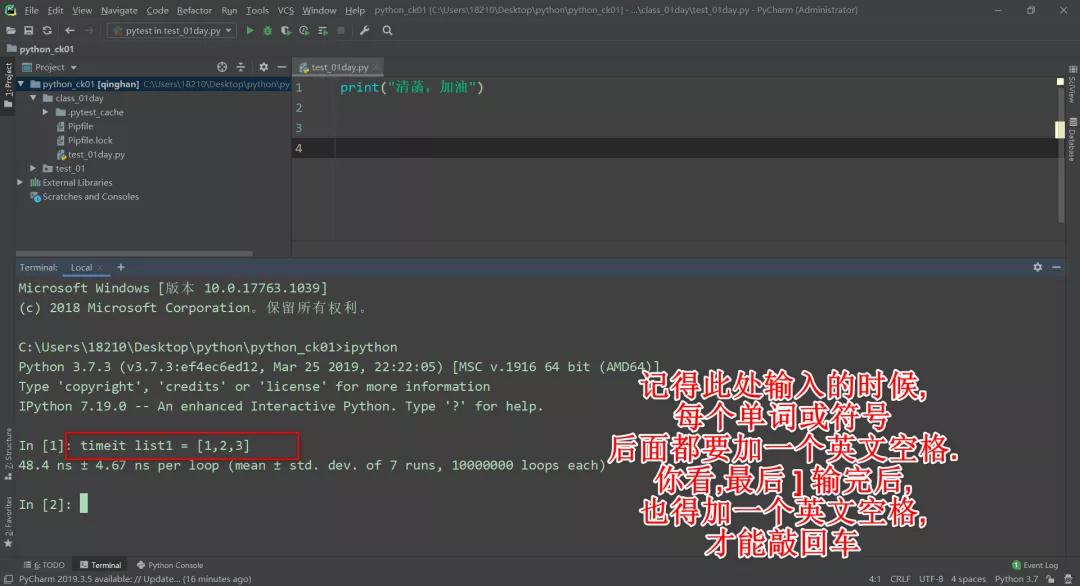
敲完这行命令,返回了一行时间。这个是在内存中初始化一个列表,如图可以看到创建了一千万次,时间是 48.4ns
可以看出,创建一个元组比创建一个列表要快得多。
元组的速度比列表要快 3 倍多。在内存里,当我们创建一个列表的时候,会划分一块区域出来,拿一块区域给列表来储存值。例如初始化,里面给它留了 20 个位置在这个列表里面储存值。
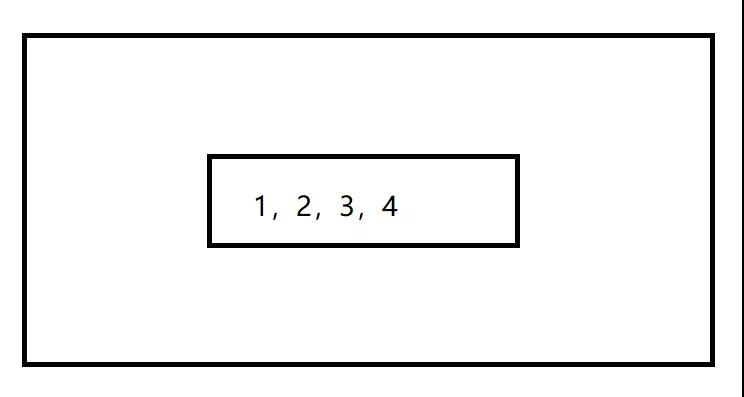
列表占用内存如图
当储存到一定程度,Python 解释器检测到列表快要盛满了的时候,它会对列表做一个扩容。
给扩容到 200,当存储到 150 的时候,发现又快存储满了,又会给你继续扩容。
随着数据的增多,底层会不断给这个列表扩容。
初始化一个元组,同样也是一千万次,只需 12.8ns
元组是一个不可变的类型。
比如定义的元组里面有 3 个元素,Python 解释器在给它分内存的时候,就给它分了 3 个格子。
这里面只能存 3 条数据,就这么大,所以元组占用的内存比列表要少。
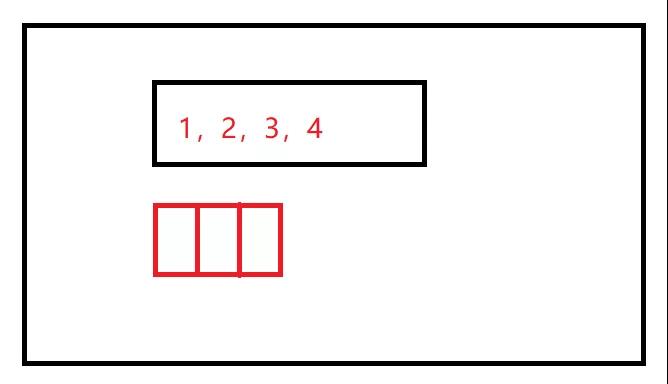
元组和列表内存占用对比图
用一个列表存储 50 条数据和用一个元组存储 50 条数据,那么元组占用的内存要比列表小得多。
2.为什么列表在 Python 中是最常用的呢?
因为列表比较灵活,用列表的话,可以往里面不断得添加元素。如果元素固定的,那就用元组。
3.timeit 里面有个 Timer 类。
来看看这个类的源码:
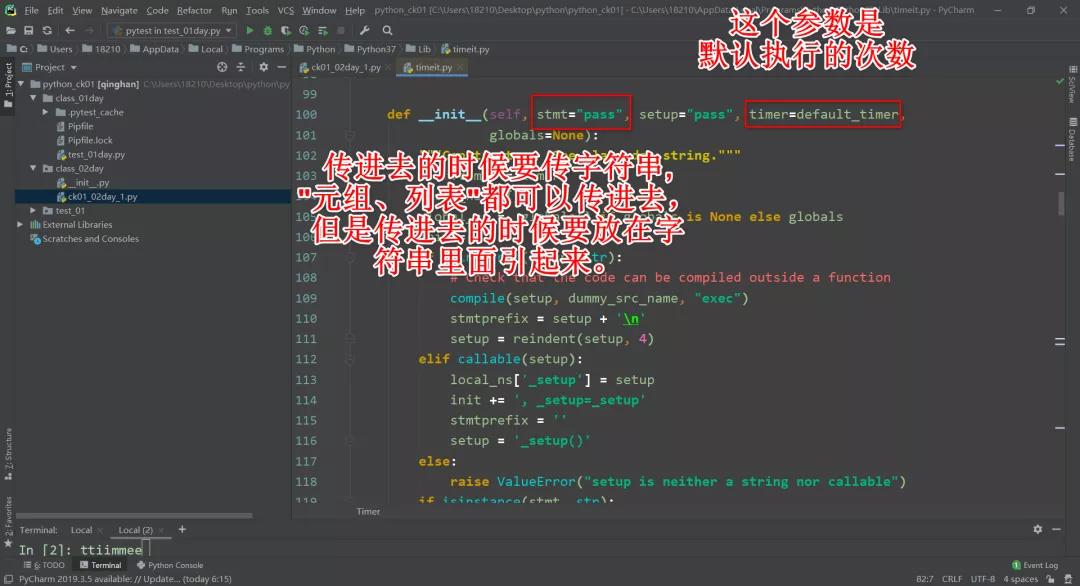
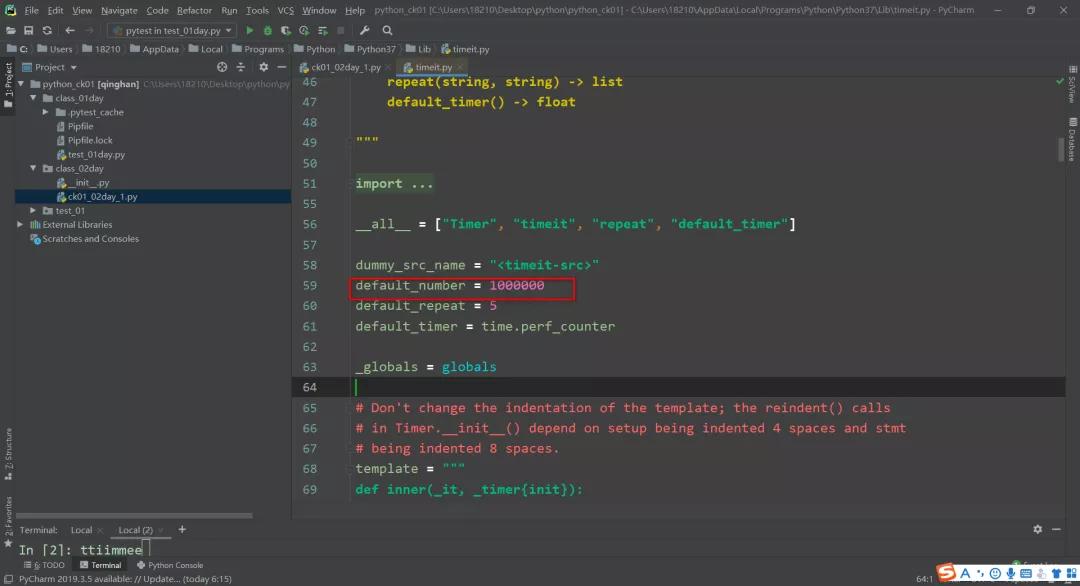
timer=default_timer代表的是:创建一个列表、元组等,它要执行的一个次数。
看源码,默认是一千万次:
import timeit # 这个模块可以用来做性能分析def func(): for i in range(10): print(i)# 这个对象有个方法叫做timeitres = timeit.Timer(func).timeit(100) # 把这个func函数传进去,运行100次,然后返回的是个时间# timeit.Timer(func).timeit(100)中函数func是不需要加引号的,如果是字符串、列表这些需要加# 引号放进去print(res)
可以看到运行 100 次需要的时间是:0.0043269999999999975
4.timeit 里面还有个直接用的 timeit 的方法,timeit.timeit()
import timeit # 这个模块可以用来做性能分析
def func():
for i in range(10):
print(i)
# 这个对象有个方法叫做timeit
# res = timeit.Timer(func).timeit(100) # 把这个func函数传进去,运行100次,然后返回的是个时间
# timeit.Timer(func).timeit(100)中函数func是不需要加引号的,如果是字符串、列表这些需要加引号放进去
# print(res)
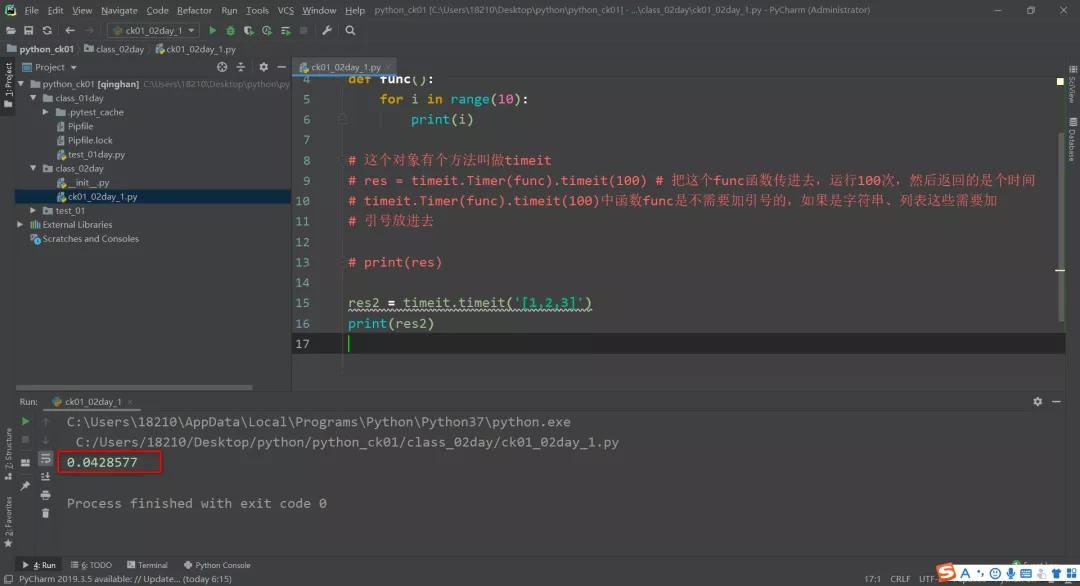
res2 = timeit.timeit('[1,2,3]')
print(res2)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
这个模块的作用: 大家写的功能函数,可以用它测下功能函数的速度,执行大概要多久。
默认是一千万次,结果如下:
如果列表不加引号直接传是会报错的:
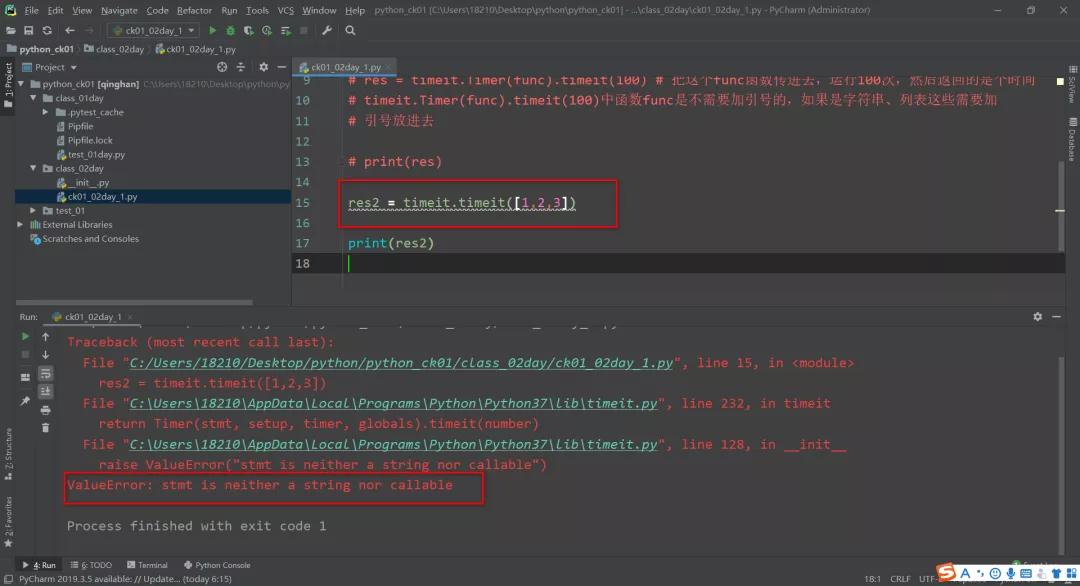
提示不可被调用!
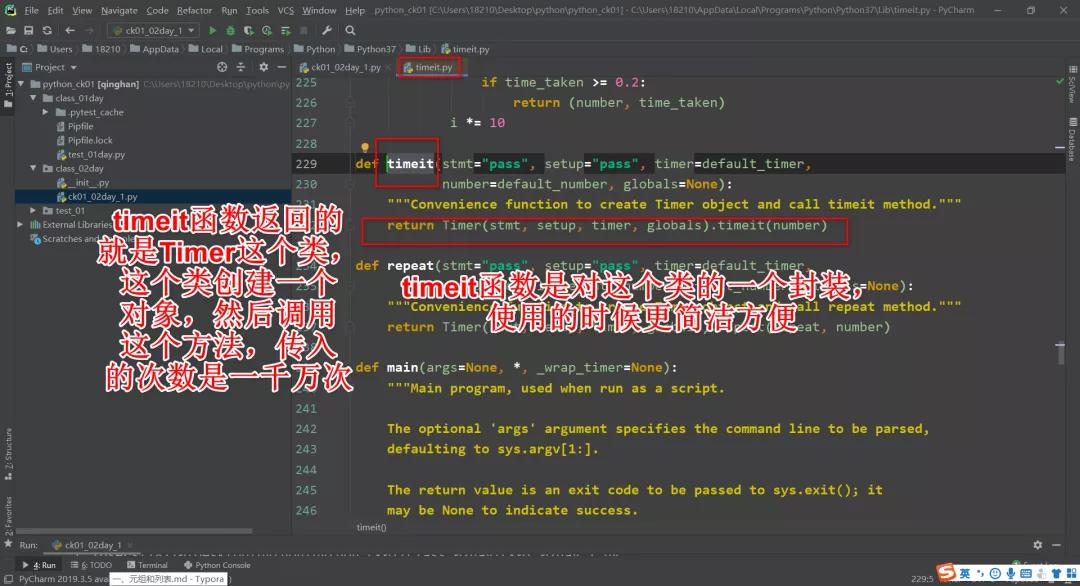
5.这 2 个方法有啥区别?
其实它们是一个东西。
二、命名元组
元组的性能是大大优于列表的。元组、列表在使用的时候,都是通过下标索引取值的。
下标索引取值不太人性化,如果我知道数据储存在元组里面,但是我不知道它具体储存的下标位置。这个时候找这个元素,还得先把下标找出来,知道下标再去拿,这样很不方便。
字典的话,这方面就比较有优势。数据是存储在字典里面的,只要通过键,就能把值找到。字典相对于元组和列表,有一定的优势和劣势。
命名元组使用的时候可以让元组像字典一样去取值。
例如,有个元组里面保存了 3 条数据:
创建一个命名元组的话,需要用到 Python 的一个内置模块from collections import namedtuple
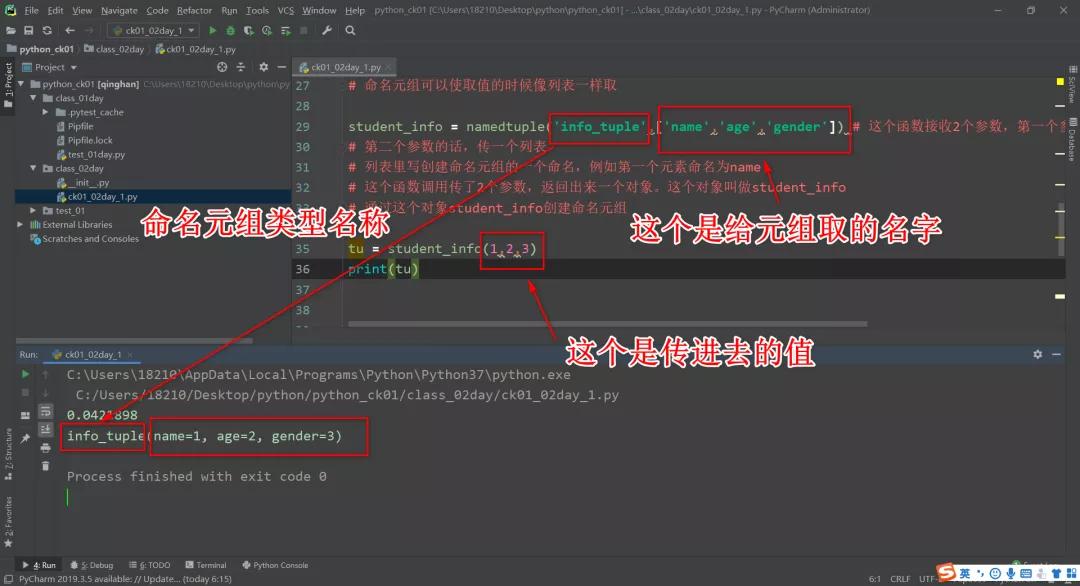
import timeit # 这个模块可以用来做性能分析
from collections import namedtuple
# namedtuple是个函数,创建命名元组可以通过这个函数来创建
def func():
for i in range(10):
print(i)
# 这个对象有个方法叫做timeit
# res = timeit.Timer(func).timeit(100) # 把这个func函数传进去,运行100次,然后返回的是个时间
# timeit.Timer(func).timeit(100)中函数func是不需要加引号的,如果是字符串、列表这些需要加引号放进去
# print(res)
res2 = timeit.timeit('[1,2,3]')
print(res2)
# 命名元组
# 如果知道里面储存的具体位置,可以通过下标取值。例如tu=[0]
# 如果我不知道名字存储在哪里,通过下标去取值就不好取了
# 命名元组可以使取值的时候像列表一样取
student_info = namedtuple('info_tuple',['name','age','gender']) # 这个函数接收2个参数,第一个参数是创建命名元组的类型的名字;
# 第二个参数的话,传一个列表
# 列表里写创建命名元组的一个命名,例如第一个元素命名为name
# 这个函数调用传了2个参数,返回出来一个对象。这个对象叫做student_info
# 通过这个对象student_info创建命名元组
tu = student_info('qinghan',18,'nv')
print(tu)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
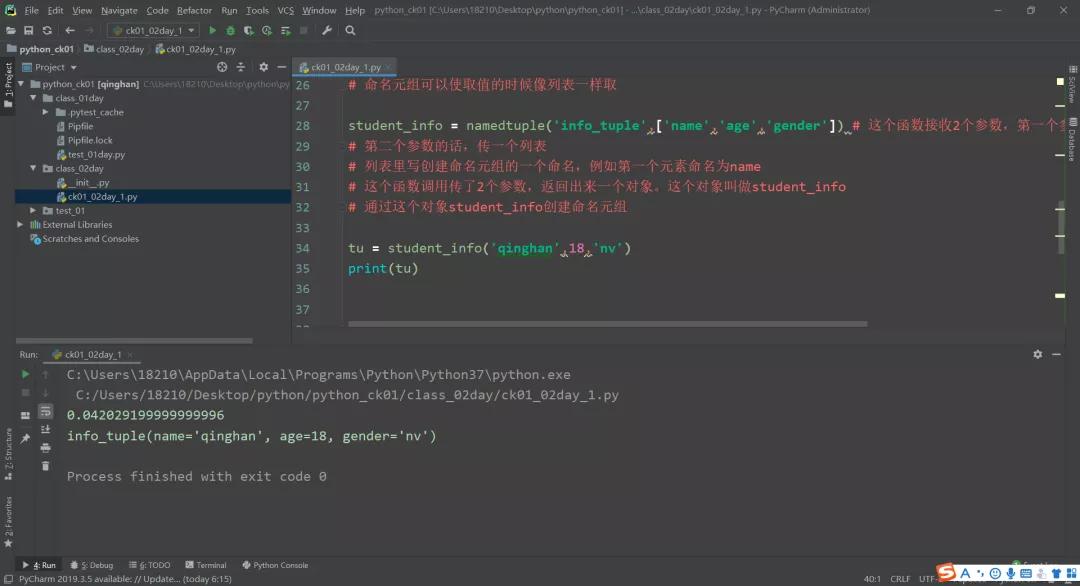
这个 tu 就是个命名元组。
student_info 是通过命名元组这个namedtuple函数创建命名元组类型:namedtuple('info_tuple',['name','age','gender'])。
然后返回出来一个对象student_info
通过student_info这个对象传入对应的元组,定义元组的时候就通过这个对象把元素写进去,返回的就是命名元组。
三、命名元组有什么特点?
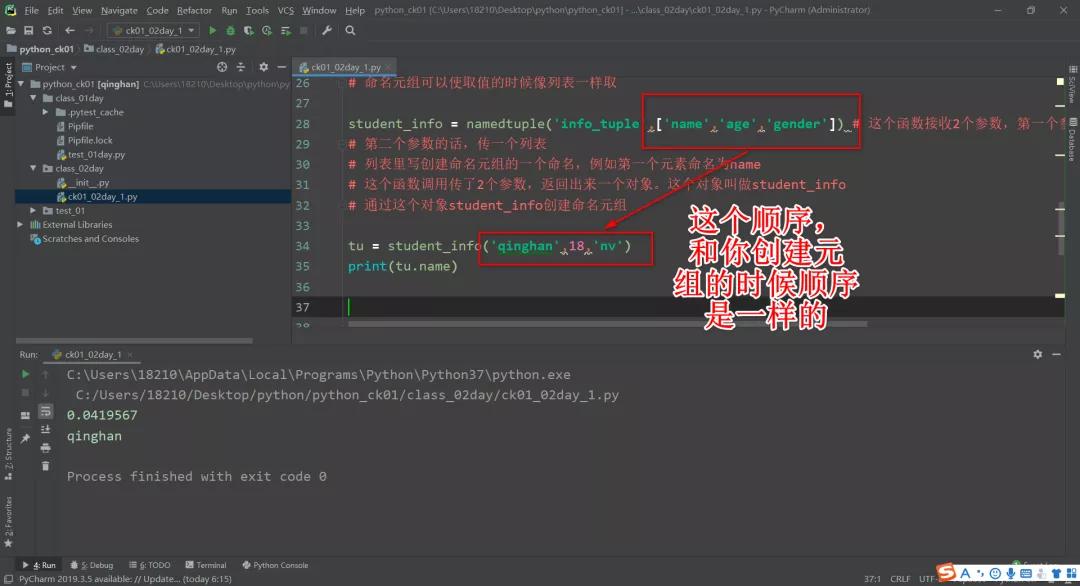
它取值的时候可以像字典一样取值,通过对应的键,找到对应的值。命名元组使用起来更像对象。
这样用:命名元组.name
这样就能找到 name 所对应的值:
import timeit # 这个模块可以用来做性能分析
from collections import namedtuple
# namedtuple是个函数,创建命名元组可以通过这个函数来创建
def func():
for i in range(10):
print(i)
# 这个对象有个方法叫做timeit
# res = timeit.Timer(func).timeit(100) # 把这个func函数传进去,运行100次,然后返回的是个时间
# timeit.Timer(func).timeit(100)中函数func是不需要加引号的,如果是字符串、列表这些需要加引号放进去
# print(res)
res2 = timeit.timeit('[1,2,3]')
print(res2)
# 命名元组
# 如果知道里面储存的具体位置,可以通过下标取值。例如tu=[0]
# 如果我不知道名字存储在哪里,通过下标去取值就不好取了
# 命名元组可以使取值的时候像列表一样取
student_info = namedtuple('info_tuple',['name','age','gender']) # 这个函数接收2个参数,第一个参数是创建命名元组的类型的名字;
# 第二个参数的话,传一个列表
# 列表里写创建命名元组的一个命名,例如第一个元素命名为name
# 这个函数调用传了2个参数,返回出来一个对象。这个对象叫做student_info
# 通过这个对象student_info创建命名元组
tu = student_info('qinghan',18,'nv')
print(tu.name)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
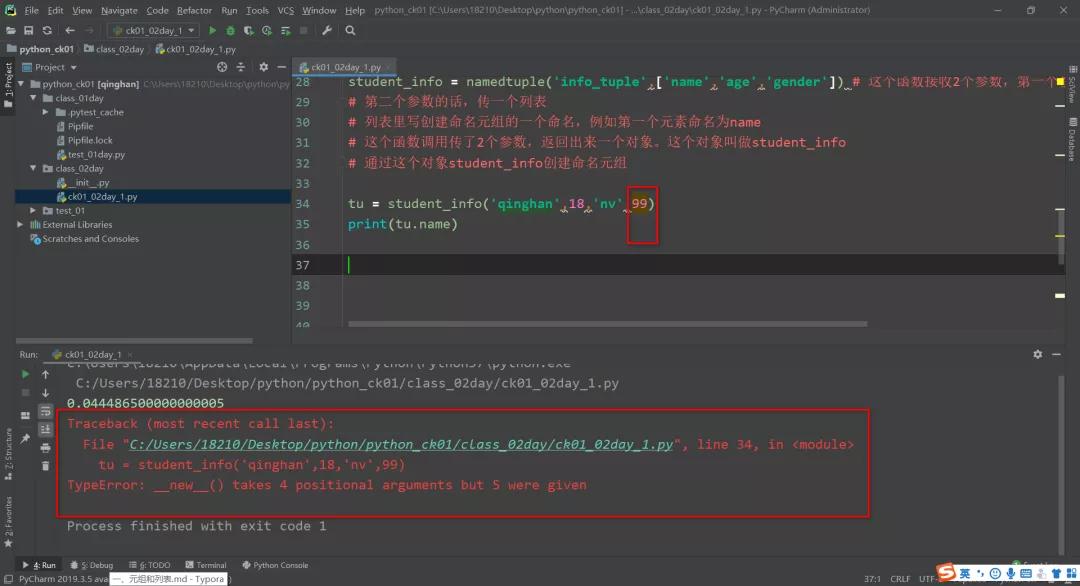
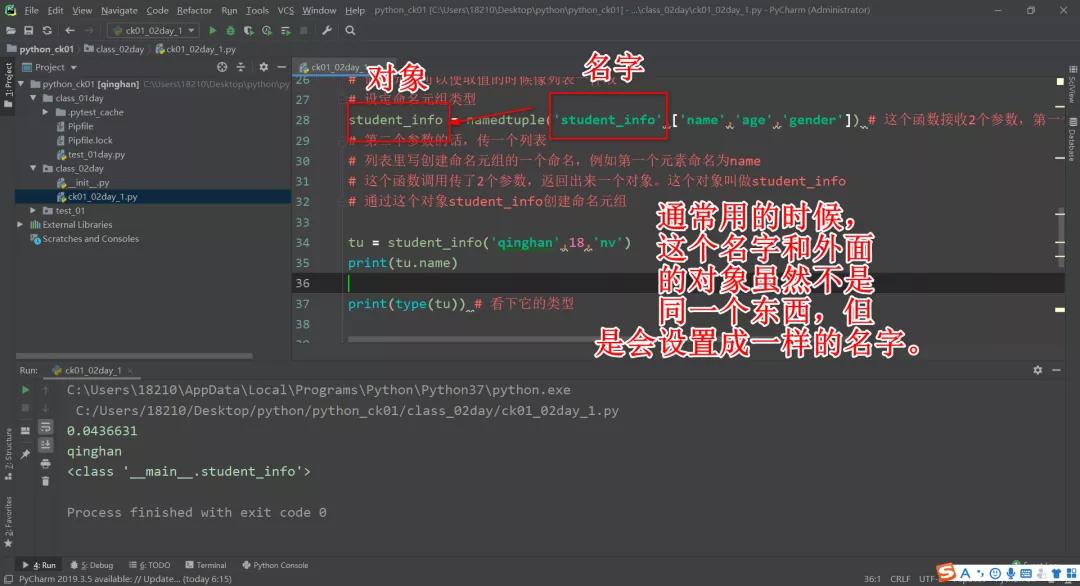
设定命名元组类型的时候,它返回的这个对象它里面只包含了传进去的这几个名字。
接下来,要创建命名元组的时候,元素和它一样多,名字和对应的元素的值是一一对应的,不能多,不能少。
否则就会报错:
print(type(tu)) # 看下它的类型
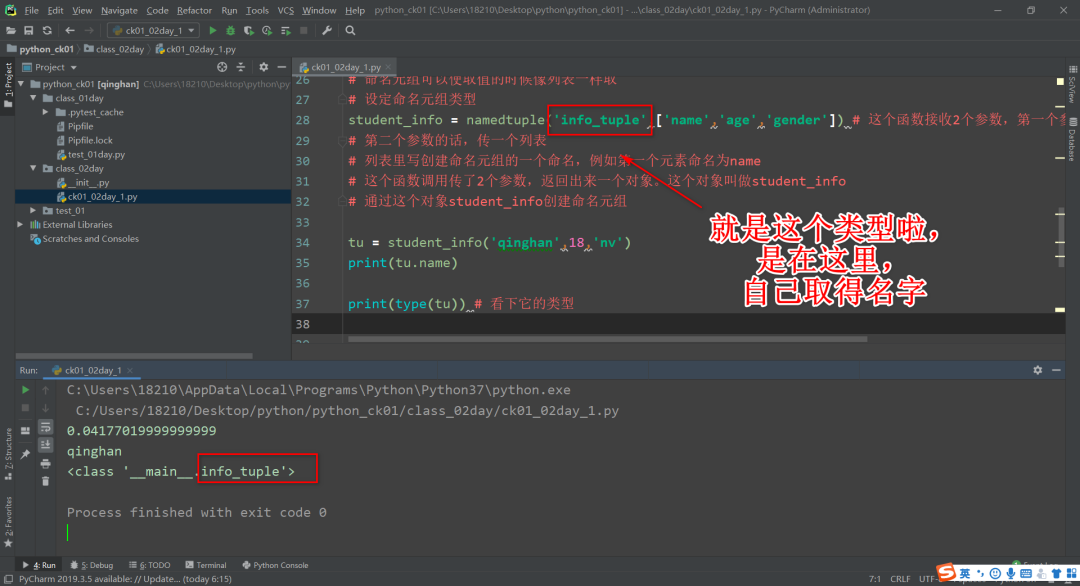
它返回的对象和类型名用的同一个名字。
print(type(student_info))
import timeit # 这个模块可以用来做性能分析
from collections import namedtuple
# namedtuple是个函数,创建命名元组可以通过这个函数来创建
def func():
for i in range(10):
print(i)
# 这个对象有个方法叫做timeit
# res = timeit.Timer(func).timeit(100) # 把这个func函数传进去,运行100次,然后返回的是个时间
# timeit.Timer(func).timeit(100)中函数func是不需要加引号的,如果是字符串、列表这些需要加引号放进去
# print(res)
res2 = timeit.timeit('[1,2,3]')
print(res2)
# 命名元组
# 如果知道里面储存的具体位置,可以通过下标取值。例如tu=[0]
# 如果我不知道名字存储在哪里,通过下标去取值就不好取了
# 命名元组可以使取值的时候像列表一样取
# 设定命名元组类型
# student_info是个类
student_info = namedtuple('student_info',['name','age','gender']) # 这个函数接收2个参数,第一个参数是创建命名元组的类型的名字;
# 第二个参数的话,传一个列表
# 列表里写创建命名元组的一个命名,例如第一个元素命名为name
# 这个函数调用传了2个参数,返回出来一个对象。这个对象叫做student_info
# 通过这个对象student_info创建命名元组
tu = student_info('qinghan',18,'nv')
print(tu.name)
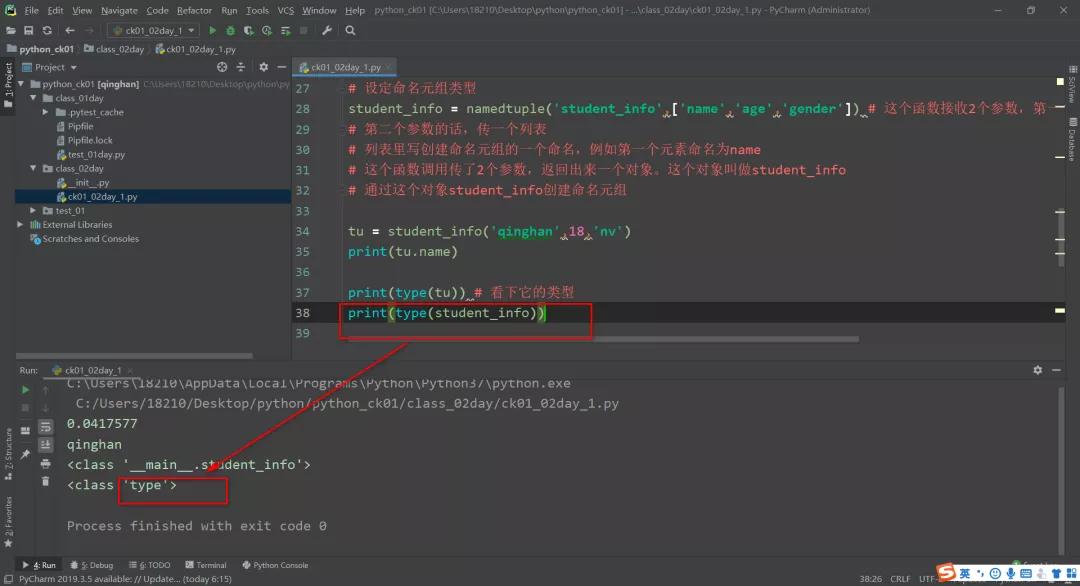
print(type(tu)) # 看下它的类型
print(type(student_info))
# 因为student_info是个类,所以看student_info的type就是个type。随便看哪个类都是一样的。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
本文转载自微信公众号「清菡软件测试」,可以通过以下二维码关注。转载本文请联系清菡软件测试公众号。