之前跟大家分享了在 pandas 的 apply 函数中用 pd.Series 功能来拆分文本,文章链接如下:
数据来源于 akshare,由于 akshare 版本的更新,部分接口发生变化,致使上面文章里的代码运行会出错。因此今天也会更新下代码。
此外,在上面文章里应用到了 apply 使用自定义函数的功能,之前文章里,自定义函数只有一个参数。有同学提了一个问题,如果自定义函数有两个参数,该怎么办?
嗯嗯嗯,这是一个好问题!
今天,Lemon也会分享下自定义函数有两个参数的情况,该如何解决。
接下来,还是先更新此前文章的代码。
01 使用apply拆分文本
Pandas 中 apply 函数,应用广泛,今天要跟大家分享一个使用的技巧,使用 apply 将 dataframe 中内容为 list 的列拆分为多列。
拆分前的数据情况,如下图红色标注所示:
拆分后,如下图所示:
这个案例中,Lemon 使用的数据来自 akshare ,在开始前,引入相关 package :
- # -*- coding: utf-8 -*-
- """
- @Author: Lemon
- @出品:Python数据之道
- @Homepage: liyangbit.com
- """
- import numpy as np
- import pandas as pd
- import akshare as ak
Lemon 使用的几个 Python 库的版本信息如下:
- print('numpy版本:{}'.format(np.__version__))
- print('pandas版本:{}'.format(pd.__version__))
- print('akshare版本:{}'.format(ak.__version__))
- # numpy版本:1.18.1
- # pandas版本:1.0.3
- # akshare版本:0.7.53
如果代码运行出现问题,请先检查下这几个Python库的版本是否与上面的一致
先从 akshare 获取需要的数据,分为两步,第一步是获取基金代码的列表,如下:
- df = ak.fund_em_fund_name().head(20).tail(5)
- dfdf = df[['基金代码','基金简称']]
- print(df)
第二步是获取基金净值数据和净值日期,通过一个自定义函数来获取,自定义函数如下:
- # 自定义函数只有一个参数的情形
- # 获取基金单位净值以及净值日期
- def get_mutual_fund(code):
- df = ak.fund_em_open_fund_info(fund=code, indicator="单位净值走势")
- dfdf = df[['净值日期', '单位净值','日增长率']]
- # df.columns = ['净值日期', '单位净值', 'equityReturn', 'unitMoney']
- df['净值日期'] = pd.to_datetime(df['净值日期'])
- dfdf = df.sort_values('净值日期',ascending=False)
- unit_equity = df.head(1)['单位净值'].values[0]
- date_latest = df.head(1)['净值日期'].values[0]
- return [unit_equity, date_latest]
对于这个自定义函数,在 pandas 使用 apply 来应用自定义函数,这是使用 apply 的一种常用的方法,如下:
- # 获取基金最新的单位净值和净值日期
- df['tmp'] = df['基金代码'].apply(get_mutual_fund)
- print(df)
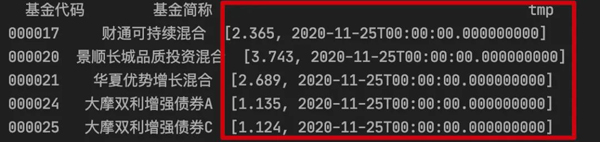
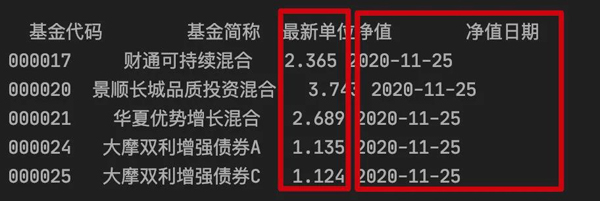
获取的数据截图如下:

文本拆分
上图中的 tmp 列,就是我们这次需要进行处理的对象。
处理方法可以有多种,这里 Lemon 使用 pandas 中的 apply 来处理,相对来说,也是比较便捷的方式。
在 apply 函数中,使用 pd.Series 就可以达到我们的目的。
- # 将单位净值和净值日期单独成列
- df[['最新单位净值','净值日期']] = df['tmp'].apply(pd.Series)
- dfdf = df.drop('tmp',axis=1)
- print(df)
结果如下:

02 有两个参数的函数
pandas 中的 apply 函数应用自定义函数时,通常情况下,都是没有参数或者一个参数,那么如果有两个参数,是否还可以使用apply函数呢?
答案是可以的。
这里我们也来探讨下。
还是以上面的案例为基础雏形,同样的,先从 akshare 获取数据
- df1 = ak.fund_em_fund_name().head(20).tail(5)
- df1df1 = df1[['基金代码','基金简称']]
接下来,自定义一个带有两个参数的函数,如下:
- # 自定义函数有两个参数的情形
- # 获取年度年底基金净值数据
- def get_mutual_fund_year(code,year):
- year = str(year)
- df = ak.fund_em_open_fund_info(fund=code, indicator="单位净值走势")
- dfdf = df[['净值日期', '单位净值', '日增长率']]
- # df.columns = ['净值日期', '单位净值', 'equityReturn', 'unitMoney']
- df['净值日期'] = pd.to_datetime(df['净值日期'])
- dfdf = df.sort_values('净值日期',ascending=False)
- dfdf = df.set_index('净值日期')[year]
- dfdf = df.reset_index()
- unit_equity = df.head(1)['单位净值'].values[0]
- date = df.head(1)['净值日期'].values[0]
- return [unit_equity,date]
带有两个参数的自定义函数
然后,使用 apply 来应用上面这个带两个参数的自定义函数,核心要点就是嵌套使用 lambda 函数,固定其中一个参数,具体如下
- df1['tmp'] = df1['基金代码'].apply(lambda code: get_mutual_fund_year(code, 2019))
后续,依旧是文本拆分,实现代码如下:
- # 将单位净值和净值日期单独成列
- df1[['最新单位净值','净值日期']] = df1['tmp'].apply(pd.Series)
- df1df1 = df1.drop('tmp',axis=1)
- print(df1)
应用场景
有同学可能会问,使用两个参数的自定义函数,有什么用呢?
这里,Lemon 也分享一个应用场景:
根据上面的基础雏形数据,针对具体的年度,建立一个下拉列表,选择不同的年份时,返回不同年份的结果,包括文本数据、表格数据以及图表等。
效果如下:

涉及到一些个人的数据,就没有完整展示啦~~
其他的应用场景,欢迎大家来分享!