介绍
在生产环境中,为了系统的可靠性,我们会对Redis搭建主从。这样当一个实例发生宕机,另一个实例中还有数据,还能继续提供服务。主从库之间采用的是读写分离的模式。
读操作:主库,从库都可以执行 写操作:只能主库上执行,主库将操作同步给从库
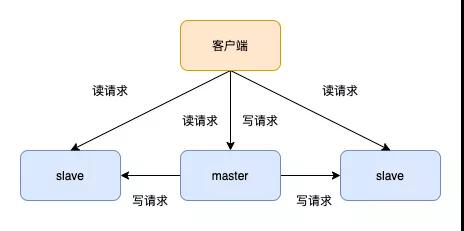
因为主从库都可以接收读请求,提高了系统的QPS。那么主从库之间如何进行数据同步呢?
全量复制
「我们可以通过replicaof命令或者replicaof设置来让redis形成主从库的关系」(redis 5.0之前使用slaveof命令)
假设现在有两个实例,实例一(172.16.19.1)和实例二(172.16.19.2)
当我们在实例二上执行如下命令后,实例二就变成了实例一的从库,并从实例一上复制数据
replicaof 172.16.19.1 6379
- 1.
当然我们也可以在实例二的redis.conf配置文件中配置如下内容
replicaof 172.16.19.1 6379
- 1.
整个同步过程如下图所示
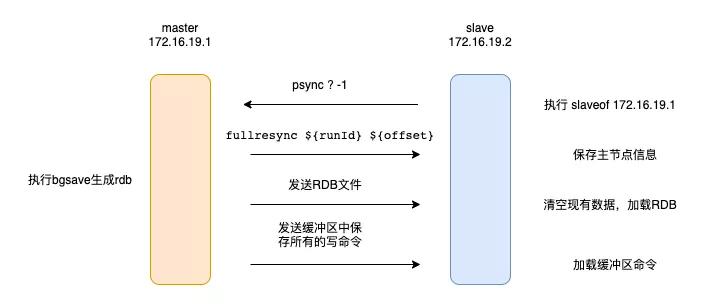
主从库全量复制主要分为如下三个阶段
- 从库发送psync命令,此时主库开始生成rdb文件
- 主库将生成的rdb文件发送给从库
- 主库将生成rdb文件后接收到的写命令发送给从库
我们仔细分析一下三个过程
从库发送psync命令,此时主库开始生成rdb文件
从库发送psync命令,表示要进行数据复制,psync命令包含了如下2个参数
「runID」:主库的runID,每个redis实例启动时都会自动生成一个随机ID,用来唯一标识实例。当从库第一次复制时,因为不知道主库的runID,所以将runID设置为?「offset」:复制进度,第一次复制为-1
主库将生成的rdb文件发送给从库
主库执行bgsave命令,生成rdb文件,并且发送给从库。从库收到rdb文件后,会清空当前数据库,然后加载rdb文件。因为从库在通过replicaof命令复制前,可能保存了其他的数据,为了避免之前数据的影响,需要先把从库清空
主库将生成rdb文件后接收到的写命令发送给从库
生成rdb文件后,主库仍能执行写命令,这些写命令会被放到replication buffer中。当主库发送完rdb文件后,就会把replication buffer中的命令发给从库,从库执行这些操作后。主从就是实现同步了。「后续正常的命令同步也是主库将命令写到replication buffer然后发给从库」
增量复制
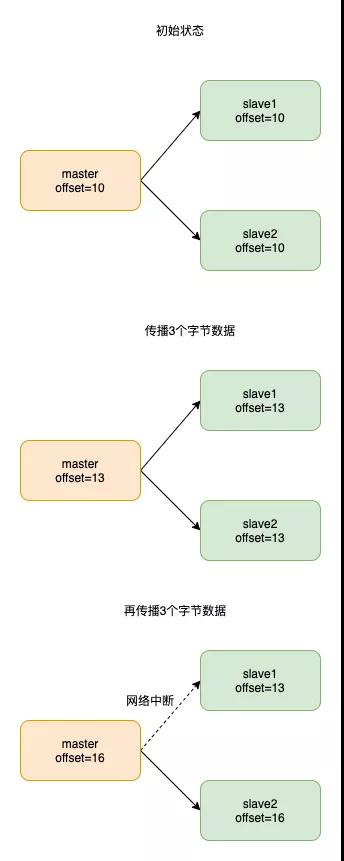
如果在主从命令传播的过程中,出现了网络异常应该怎么办呢?
在Redis2.8之前,如果出现了网络异常,从库和主库会进行一次增量复制,开销非常大。在Redis2.8之后,主从库会采用增量复制的方式进行同步。增量复制只会把主从库断连期间主库接收到的命令同步给从库
「增量同步时主从库如何保持一致呢?」
复制偏移量
主库和存库都会在内部维护一个复制偏移量 主库每次向从库发送n个字节的数据时,就把自己的复制偏移量加上n 从库每次收到主库传来的n个字节的数据时,就把自己的复制偏移量加上n
repl_backlog_buffer(复制积压缓冲区)
repl_backlog_buffer是由主服务器维护的一个固定长度先进先出(FIFO)队列 我们举个例子,如果将hello字符串放入一个固定长度为3的FIFO队列,值依次为
[h, e, l] [e, l, l] [l, l, o]
- 1.
「每次都是都是在队尾添加值,弹出队首」复制积压缓冲区的构造如下
| 偏移量 | ... | 20 | 21 | 22 | 23 | 24 | 25 | ... |
|---|---|---|---|---|---|---|---|---|
| 字节值 | ... | h | e | l | l | l | o | ... |

「当服务器在进行命令传播的时候,不仅会将写命令发送给所有从服务器,还会将写命令入队到复制积压缓冲区中」
当从库发生网络中断重新上主库之后,会发送「psync 主库id offset」给主库,主库根据复制偏移量来决定对从服务器执行何种复制操作
如果从库发送的主库id与当前连接的主库id相同,可以继续尝试增量复制
如果从库发送的主库id与当前连接的主库id不相同,说明主服务器断线之前复制的主服务器并不是当前连接的服务器,只能全量复制
如果offse偏移量之后的数据(即偏移量offset+1开始的数据)仍然存在repl_backlog_buffer中,则把命令放到replication buffer,然后发送给从库
如果offset偏移量之后的数据不存在repl_backlog_buffer中,则进行全量复制
replication buffer和repl_backlog_buffer

有很多小伙伴刚开始的时候分不清replication buffer和repl_backlog_buffer的作用,包括我。
其实很好理解,replication buffer其实是一个client端的缓冲区,redis每次把要发送的命令放到这个缓冲区中,然后再发送。「每个客户端一个replication buffer」
「而repl_backlog_buffer单纯用作增量复制,在redis服务器中只有一个」
本文转载自微信公众号「Java识堂」,可以通过以下二维码关注。转载本文请联系Java识堂公众号。