今天分享一个高频面试问题:深拷贝与浅拷贝以及写时拷贝
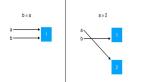
假设B复制了A,当修改A时,看B是否会发生变化。如果B也跟着变了,说明这是浅拷贝;如果B没变,那就是深拷贝。
1、浅拷贝:将原对象的引用直接赋给新对象,新对象只是原对象的一个引用。
2、深拷贝:创建一个新的对象和数组,将原对象的各项属性的“值”(数组的所有元素)拷贝过来,是“值”而不是“引用”。
浅拷贝只是对指针的拷贝,拷贝后两个指针指向同一个内存空间,深拷贝不但对指针进行拷贝,而且对指针指向的内容进行拷贝,经深拷贝后的指针是指向两个不同地址的指针。
3、写时复制技术:最初产生于Unix系统,用于实现一种傻瓜式的进程创建:当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,因为它需要:
· 为子进程的页表分配页面
· 为子进程的页分配页面
· 初始化子进程的页表
· 把父进程的页复制到子进程相应的页中
创建一个地址空间的这种方法涉及许多内存访问,消耗许多CPU周期,并且完全破坏了高速缓存中的内容。在大多数情况下,这样做常常是毫无意义的,因为许多子进程通过装入一个新的程序开始它们的执行,这样就完全丢弃了所继承的地址空间。
现在的Unix内核(包括Linux),采用一种更为有效的方法称之为写时复制(或COW)。这种思想相当简单:父进程和子进程共享页面而不是复制页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中并标记为可写。原来的页面仍然是写保护的:当其它进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写的。
Linux的fork()使用写时复制
传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据或许可以共享。更糟糕的是,如果新进程打算立即执行一个新的映像,那么所有的拷贝都将前功尽弃。Linux的fork()使用写时拷贝(copy-on-write)页实现。
写时拷贝是一种可以推迟甚至避免拷贝数据的技术。内核此时并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间。只用在需要写入的时候才会复制地址空间,从而使各个进行拥有各自的地址空间。也就是说,资源的复制是在需要写入的时候才会进行,在此之前,只有以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候。在页根本不会被写入的情况下—例如,fork()后立即执行exec(),地址空间就无需被复制了。fork()的实际开销就是复制父进程的页表以及给子进程创建一个进程描述符。在一般情况下,进程创建后都为马上运行一个可执行的文件,这种优化,可以避免拷贝大量根本就不会被使用的数据(地址空间里常常包含数十兆的数据)。由于Unix强调进程快速执行的能力,所以这个优化是很重要的。
COW技术初窥:
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,linux中引入了“写时复制“技术,也就是只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
那么子进程的物理空间没有代码,怎么去取指令执行exec系统调用呢?
在fork之后exec之前两个进程用的是相同的物理空间(内存区),子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。
在网上看到还有个细节问题就是,fork之后内核会通过将子进程放在队列的前面,以让子进程先执行,以免父进程执行导致写时复制,而后子进程执行exec系统调用,因无意义的复制而造成效率的下降。