












在过去的一年里,许多行业受疫情冲击发展陷入停滞,人工智能应用却实现了逆势突破。在世界人工智能大会WAIC2020上,李兰娟院士表示,AI在疫情防控中,发挥了重要作用。
此外,AI在无人驾驶汽车等前沿领域也持续发力;在AI顶层设计方面,国家也不遗余力积极制定相关标准,出台了《国家新一代人工智能标准体系建设指南》,为人工智能的规范发展扫平障碍。
AI高速发展的背后,离不开“燃料”算力的助推。算力作为AI 2.0的四大要素之一,为人工智能提供计算能力的支撑。
需求倒逼创新
AI芯片行业将迎变革
在过去的几十年里,基于摩尔定律,芯片行业的发展一直推动着芯片制程和性能的稳步提升,算力需求的增长也促进了人工智能工作负载中大量采用专用的AI加速器(GPU、FPGA、ASIC、xPU等)。
与传统的CPU架构相比,这些加速器能够执行更快的AI作业和并行计算。它们为有效执行控制ML/DL工作负载提供了专门的支持。
现在市场上已经有各类 AI加速器:GPU、FPGA、ASIC等等,各种各样的计算平台被运用到AI计算中。之所以会出现这么多各种形式的 AI 芯片,正是因为算法的多元化,例如机器学习算法有 LR、GBDT,深度学习中的 CNN、DNN 等,这些算法都非常复杂,如果机器要很快地让这些算法“跑”起来,一定需要算法的逻辑跟芯片计算的逻辑相互匹配。
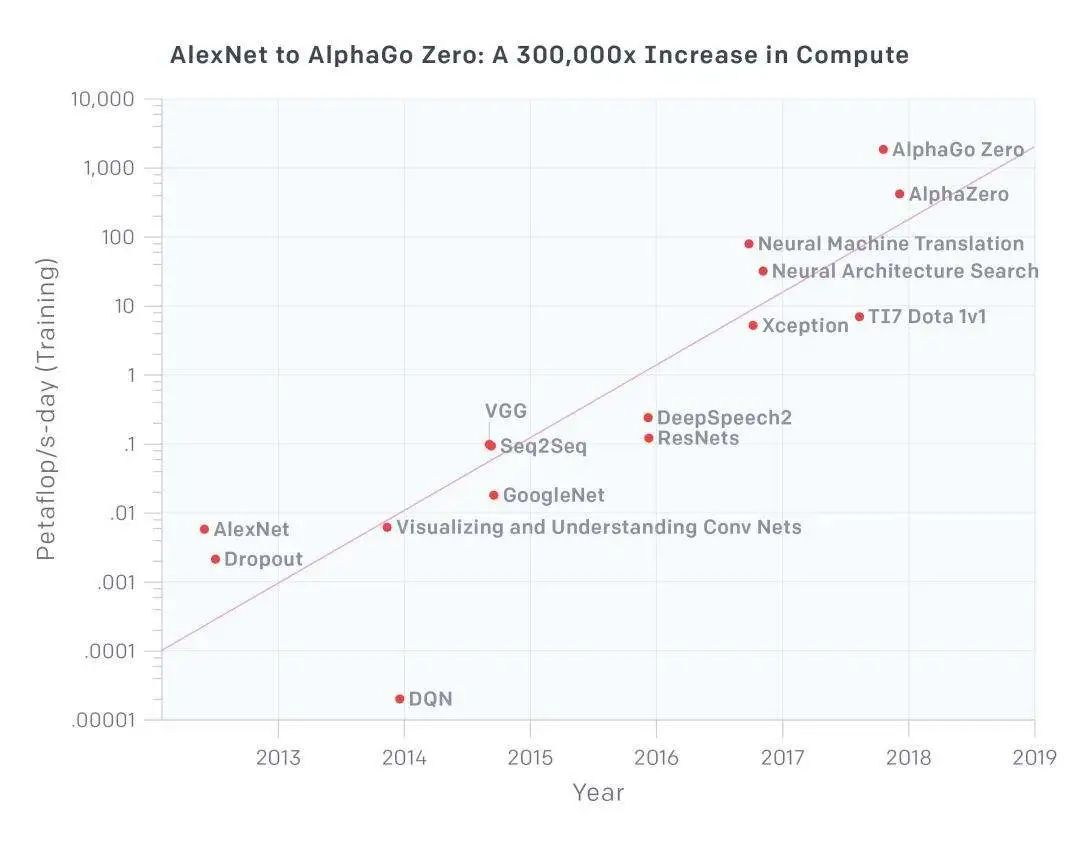
据OpenAI组织发布的一份分析报告显示,自2012年以来,在人工智能训练中所使用的计算量呈指数级增长,3.5个月的时间计算量就翻了一倍(相比之下,摩尔定律有18个月的倍增周期)。自2012年以来,该指标增长了30多万倍。按照这个趋势,想要满足未来AI发展的需求,芯片行业势必要有所变革。
Graphcore IPU:专为人工智能而生
一种全新的完全可编程处理器
Graphcore是一家创办于2016年的人工智能芯片设计初创公司,总部位于英国,以“专注于新型 AI 处理器架构,专门适用于算力密集型的机器学习任务”,入选2020年度《麻省理工科技评论》“50家聪明公司”榜单。该公司开发了一款被称为IPU智能处理单元(intelligence processing unit)的新型AI加速器。
Graphcore IPU是专门为AI/Machine Learning设计的处理器,拥有完全不同于前面几类处理器类型的全新架构,能够提供强大的并行处理能力。Graphcore IPU区别于其他处理器的一个重要因素还在于,它实现了快速训练模型和实时操控,这使得它能够在自然语言处理以及理解自动驾驶方面取得重大进展。

Graphcore 的IPU特点可概括为:
- 同时支持 Training 和 Inference;
- 采用同构多核(many-core)架构,超过1000个独立的处理器;
- 支持 all-to-all的核间通信,采用Bulk Synchronous Parallel的同步计算模型;
- 采用大量片上SRAM,不需要外部DRAM。

据介绍,IPU处理器是迄今为止最复杂的处理器芯片,它在一个16纳米芯片上有几乎240亿个晶体管,每个芯片提供125 teraFLOPS运算能力。一个标准4U机箱中可以插入8张卡,卡间通过IPU-Link互连。8张卡上的IPU可以看做一个处理器工作,提供 1.6PetaFLOPS的运算能力。
与GPU争锋?
IPU:没在怕的
英伟达公司率先于1999年提出GPU的概念,GPU使显卡减少了对CPU的依赖,然而随着模型越来越大,参数越来越多,面对高精度高吞吐量的需求,算力优势显著的IPU也许更能代表AI芯片的发展方向。
Graphcore IPU在现有以及下一代模型上的性能均优于GPU,在自然语言处理方面的速度能比GPU快25%到50%;在图像分类方面,吞吐量7倍于GPU,而且时延更低。
Natural Language Processing-BERT
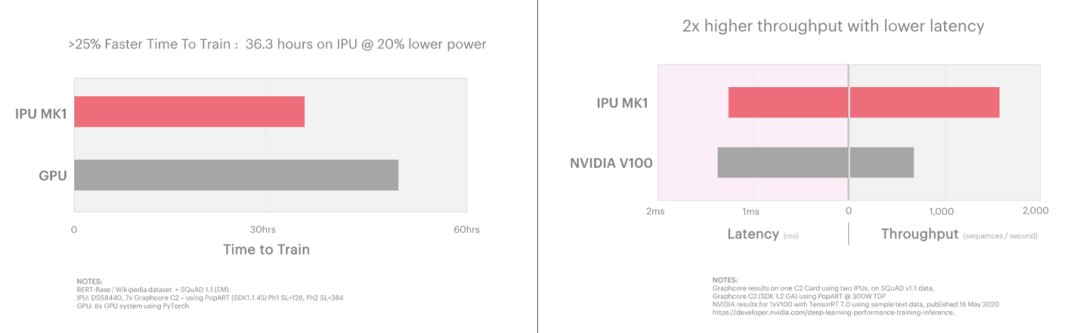
BERT (Bidirectional Encoder Representations from Transformers)是目前使用的最著名的NLP模型之一。IPU加速了BERT的训练和推理,在极低延迟的情况下, IPU能够进行实现2倍于目前解决方案的吞吐量,同时延迟性能比当前的解决方案提升1.3倍。
计算机视觉:EfficientNet & ResNeXt模型
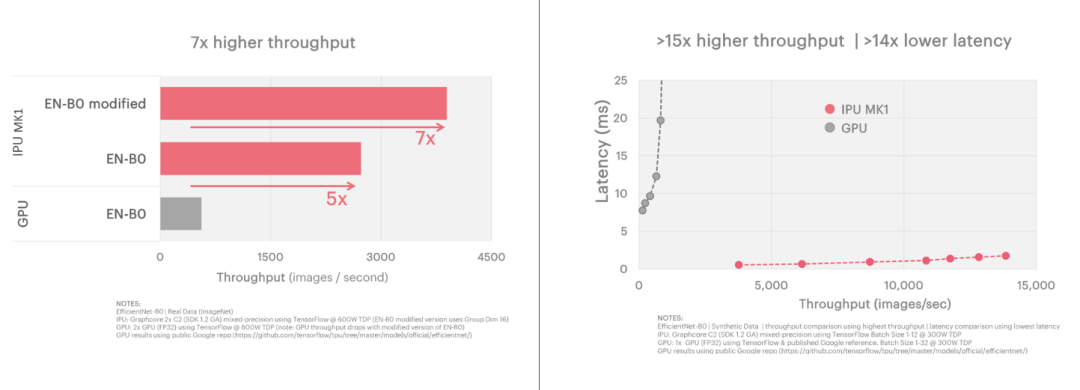
由于IPU架构的特定特性,它非常擅长于分组卷积的模型。在计算机视觉模型如efficient entnet和ResNeXt中显著提升了训练和推理的性能。
在EfficientNet推理(左图)和训练(右图)模型测试中,IPU在比GPU延迟低14倍的情况下实现了15倍的高吞吐量的优势,推理模型种子能够实现7倍于目前GPU解决方案的吞吐量。
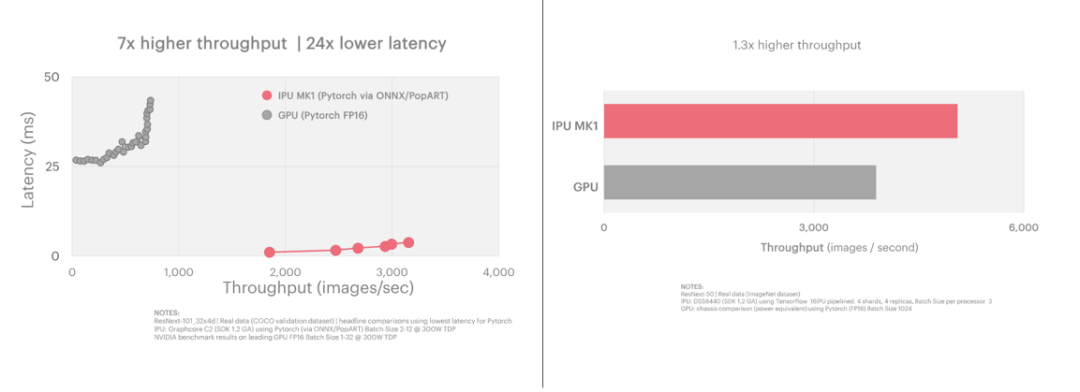
如下图所示,ResNeXt-101: Inference(左图) 和 ResNeXt-50 Training(右图)与GPU相比,Graphcore C2 IPU处理器在延迟低24倍的情况下实现了7倍的高吞吐量。
好马配好鞍——IPU全软件栈和框架支持
Graphcore提供了Poplar SDK IPU软件开发平台,帮助用户高效地构建人工智能应用,可为当今的领先模型提供开箱即用的先进性能。
Poplar SDK可与TensorFlow、Pytorch和ONNX等流行框架一起使用。它支持高阶的机器智能图描述,可编译加载到IPU上优化的Poplar图和相关的控制程序。大规模的处理器内存意味着可以充分利用庞大的处理器内带宽,可将整个模型加载到IPU上。
Poplar SDK支持一系列标准框架。通过TensorFlow,Poplar SDK可直接接受XLA图,并将XLA编译输出为Poplar图和控制程序。
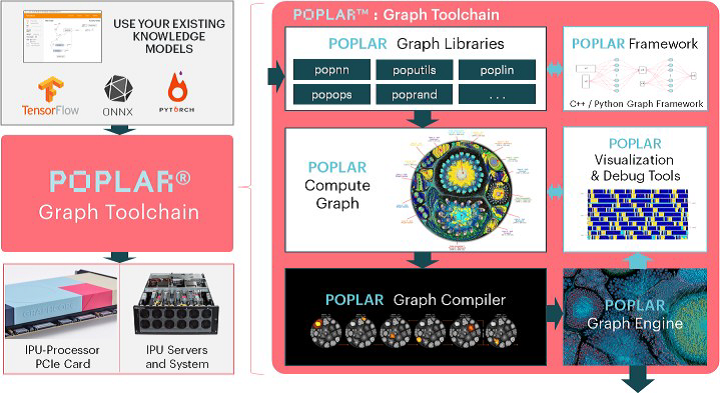
Graphcore还为ONNX提供了训练运行时(runtime),并且正与ONNX各组织紧密合作,以将其纳入ONNX标准环境中。
DSS 8440服务器:业界首款采用Graphcore技术的机器学习服务器
作为Graphcore的合作伙伴,戴尔科技希望能为用户提供更强大的算力支持,将业内领先的创新研发成果融入机器学习硬件产品,推出了业界首款搭载Graphcore IPU的戴尔易安信DSS 8440服务器。它属于两处理器插槽的4U服务器,旨在为人工智能应用提供卓越的性能。
支持8个Graphcore C2卡(双IPU),可提供高达1.6Peta FLOP的混合精度机器智能计算能力。
采用了多功能平衡加速器,可以搭载4个、8个或10个NVIDIA Tesla V100 GPUs以及更高达16块T4 GPUs,用户可以根据需要和最佳配置,有效地分配机器学习资源。
拥有高速输入/输出性能,利用IPU-Link的“阶梯式”拓扑,在两个IPU C2卡之间的总体双向带宽为256GB/s。此配置保障了多块IPU卡之间高速共享模型参数或数据,为科学和工程环境中的建模、模拟和预测分析等计算密集型工作负载提供更优性能。
对于分布式训练应用,戴尔易安信DSS 8440服务器还提供多个100Gbps网络链接,以实现服务器到服务器的可扩展性。
搭载了Graphcore IPU的戴尔易安信DSS 8440服务器,是人工智能训练和推理应用的理想之选。用户利用DSS 8440中大量的低延迟本地存储和强大的吞吐能力,可从海量的数据源中获得更快的结果。

戴尔易安信丰富的机器学习专业知识,经典机器学习、深度学习的硬件和解决方案,能够帮助AI 技术开发、研发型的初创小企业,快速部署稳定可靠且高算力的基础架构产品,支持创新研发提高其核心竞争力。
尊敬的读者
随着2021新年的到来
戴尔科技开年第一“惠”盛情来袭
助企业新的一年牛气冲天!
多款服务器、工作站、商用笔记本
等产品限时优惠
更有0元试用、现金红包
等活动等你来参与
快来扫描下方二维码
或点击文末阅读原文
了解活动详情

相关内容推荐:戴尔科技开年第一“惠”盛情来袭|爆款服务器“骨折价”限时抢购
















