本文转自雷锋网,如需转载请至雷锋网官网申请授权。
为庆祝Muzero论文在Nature上的发表,我特意写了这篇文章对MuZero算法进行详细介绍,希望本人能让你对该算法有一个直观的了解。
MuZero是令人振奋的一大步,该算法摆脱了对游戏规则或环境动力学的知识依赖,可以自行学习环境模型并进行规划。即使如此,MuZero仍能够实现AlphaZero的全部功能——这显示出其在许多实际问题的应用可能性!
所有一切不过是统计
MuZero是一种机器学习算法,因此自然要先了解它是如何使用神经网络的。简单来说,该算法使用了AlphaGo和AlphaZero的策略网络和值网络:
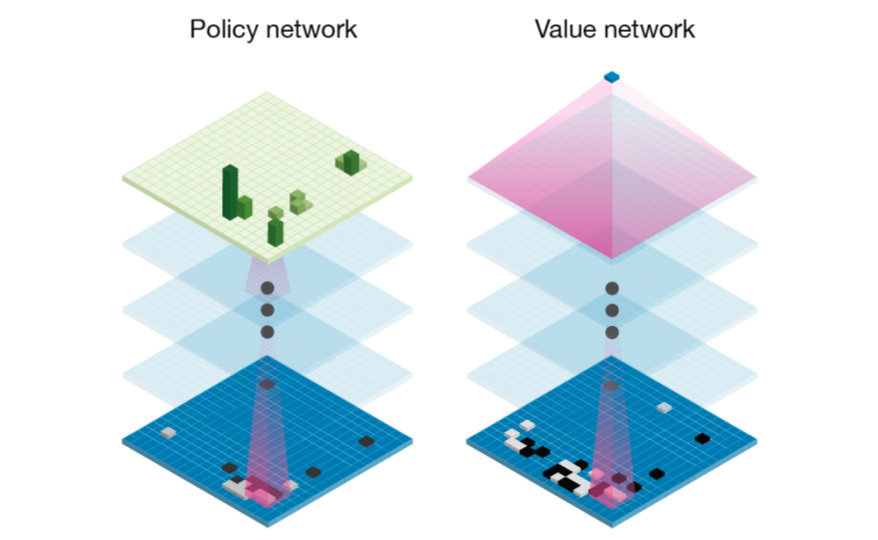
策略和值的直观含义如下:
-
策略p(s,a)表示在状态s时所有可能的动作a分布,据此可以估计最优的动作。类比人类玩家,该策略相当于快速浏览游戏时拟采取的可能动作。
-
值v(s)估计在当前状态s下获胜的可能性,即通过对所有的未来可能性进行加权平均,确定当前玩家的获胜概率。
这两个网络任何一个都非常强大:只根据策略网络,能够轻易预测每一步的动作,最终得到良好结果;只依赖值网络,始终选择值最高的动作。但是,将这两个估计结合起来可以得到更好的结果。
取胜之路
与AlphaGo和AlphaZero相似,MuZero也使用蒙特卡洛树搜索方法(MCTS)汇总神经网络预测并选择适合当前环境的动作。
MCTS是一种迭代的,最佳优先的树搜索过程。最佳优先意味着搜索树的扩展依赖于搜索树的值估计。与经典方法(如广度优先或深度优先)相比,最佳优先搜索利用启发式估计(如神经网络),这使其在很大的搜索空间中也可以找到有效的解决方案。
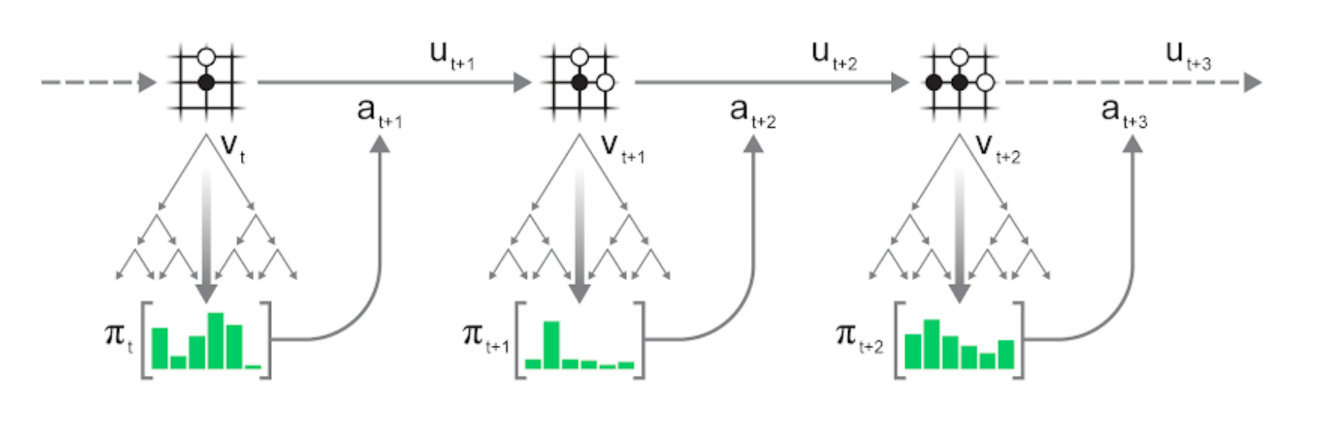
MCTS具有三个主要阶段:模拟,扩展和反向传播。通过重复执行这些阶段,MCTS根据节点可能的动作序列逐步构建搜索树。在该树中,每个节点表示未来状态,而节点间的边缘表示从一个状态到下一个状态的动作。
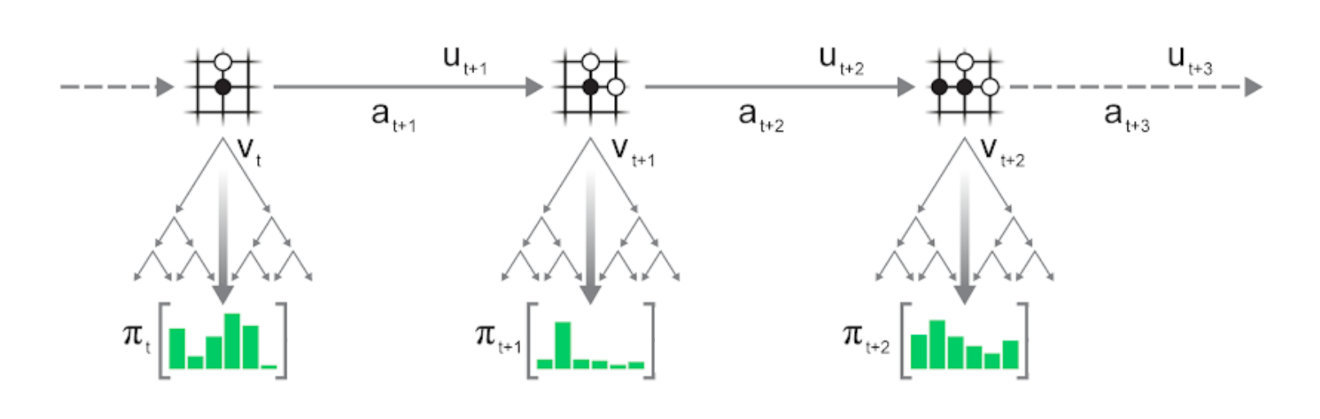
在深入研究之前,首先对该搜索树及逆行介绍,包括MuZero做出的神经网络预测:
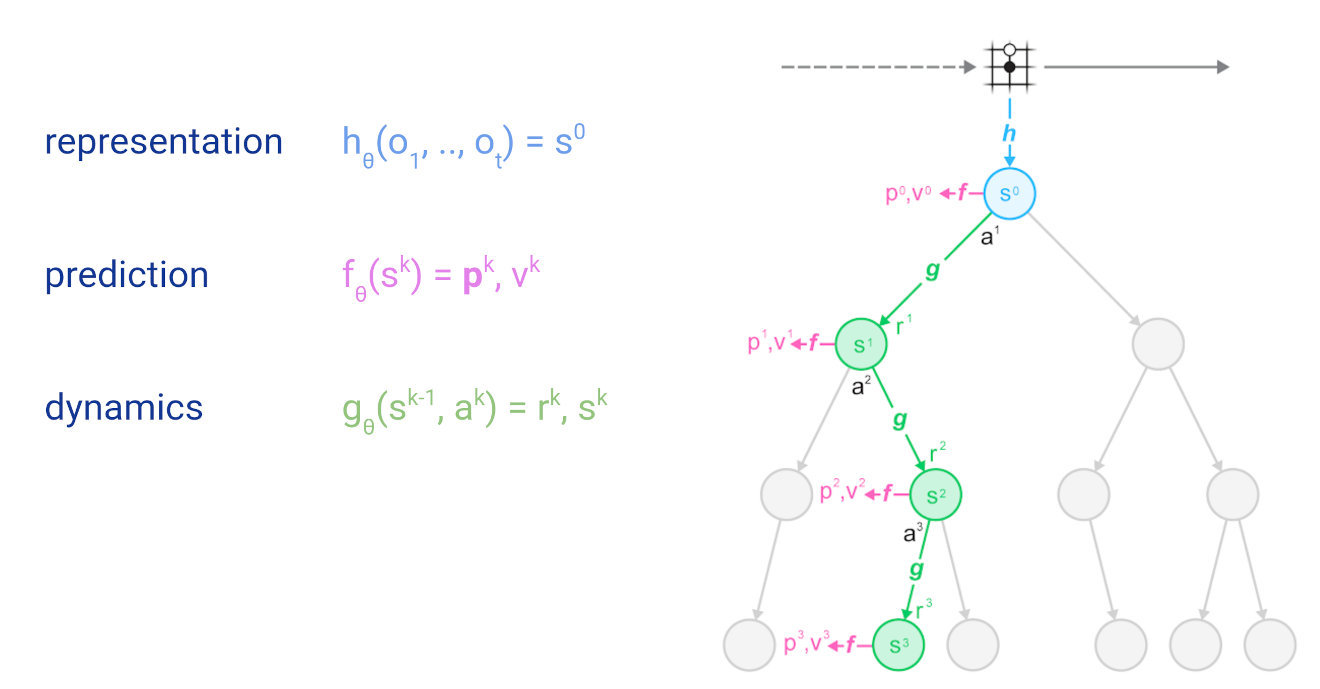
圆圈表示树节点,对应环境状态;线表示从一个状态到下一个状态的动作;根节点为当前环境状态,即围棋面板状态。后续章节我们会详细介绍预测和动力学函数。
模拟:从树的根节点出发(图顶部的淡蓝色圆圈),即环境或游戏的当前位置。在每个节点(状态s),使用评分函数U(s,a)比较不同的动作a,并选择最优动作。MuZero中使用的评分函数是将先前的估计p(s,a)与v(s')的值结合起来,即
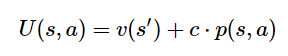
其中c是比例因子,随着值估计准确性的增加,减少先验的影响。
每选择一个动作,我们都会增加其相关的访问计数n(s,a),以用于UCB比例因子c以及之后的动作选择。
模拟沿着树向下进行,直到尚未扩展的叶子。此时,应用神经网络评估节点,并将评估结果(优先级和值估计)存储在节点中。
扩展:一旦节点达到估计量值后,将其标记为“扩展”,意味着可以将子级添加到节点,以便进行更深入的搜索。在MuZero中,扩展阈值为1,即每个节点在首次评估后都会立即扩展。在进行更深入的搜索之前,较高的扩展阈值可用于收集更可靠的统计信息。
反向传播:最后,将神经网络的值估计传播回搜索树,每个节点都在其下保存所有值估计的连续均值,这使得UCB公式可以随着时间的推移做出越来越准确的决策,从而确保MCTS收敛到最优动作。
中间奖励
细心的读者可能已经注意到,上图还包括r的预测。某一情况(如棋盘游戏)在完全结束后提供反馈(获胜/失败结果),这样可以通过值估计进行建模。但在另外一些情况下,会存在频繁的反馈,即每次从一种状态转换到另一种状态后,都会得到回报r。
只需对UCB公式进行简单修改,就可以通过神经网络预测直接对奖励进行建模,并将其用于搜索。
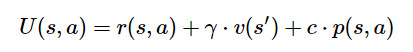
其中,r(s,a)是指在状态s时执行动作a后观察到的奖励,而折扣因子γ是指对未来奖励的关注程度。
由于总体奖励可以时任意量级的,因此在将其与先验奖励组合之前,我们将奖励/值估计归一化为区间[0,1]:
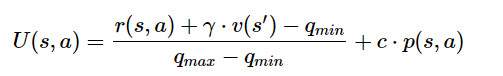
其中,q_min和q_max分别是整个搜索树中观察到的最小和最大r(s,a)+γ⋅v(s')估计。
过程生成
重复执行以下过程可实现上述MCTS:
-
在当前环境状态下进行搜索;
-
根据搜索的统计信息π_t选择一个动作a_(t+1);
-
根据该动作更新环境,得到新的状态s_(t+1)和奖励u(t+1);
-
重复上述过程。
动作的选择可以是贪心的(选择访问次数最多的动作),也可以是探索性的:通过一定的温度t控制探索程度,并对与访问次数n(s,a)成比例的动作a进行采样:
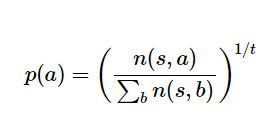
当t = 0时,等效贪婪采样;当t = inf时,等效均匀采样。
训练
现在,我们已经学会了运行MCTS来选择动作,并与环境互动生成过程,接下来就可以训练MuZero模型了。
首先,从数据集中采样一条轨迹和一个位置,然后根据该轨迹运行MuZero模型:
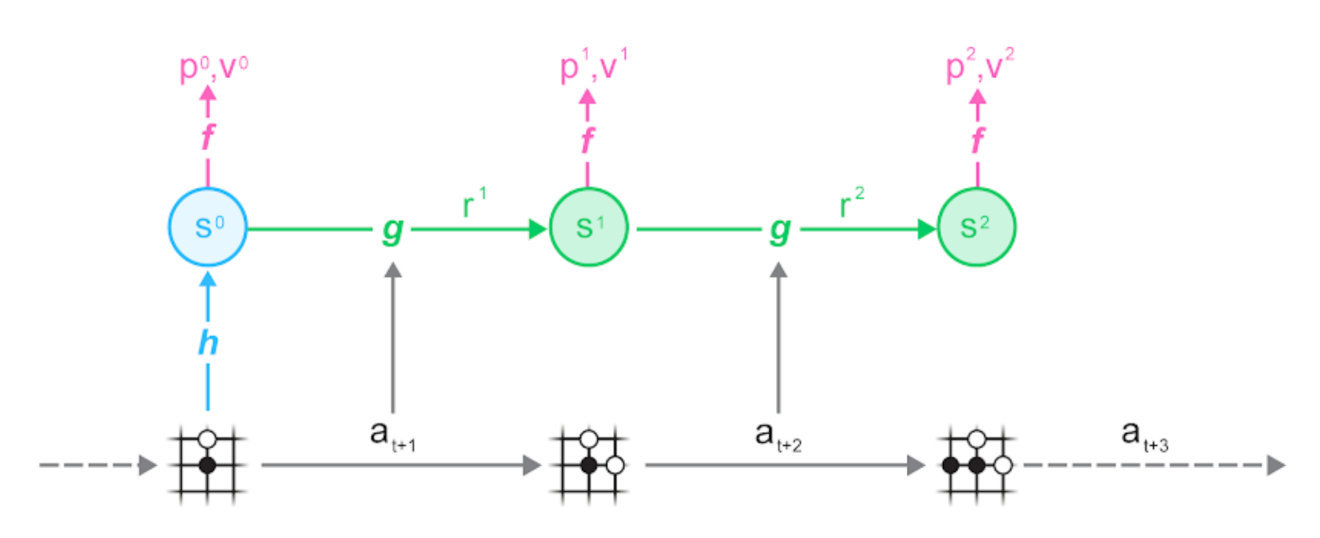
可以看到,MuZero算法由以下三部分组成:
-
表示函数h将一组观察值(棋盘)映射到神经网络的隐藏状态s;
-
动态函数g根据动作a_(t + 1)将状态s_t映射到下一个状态s_(t + 1),同时估算在此过程的回报r_t,这样模型就能够不断向前扩展;
-
预测函数f根据状态s_t对策略p_t和值v_t进行估计,应用UCB公式并将其汇入MCTS过程。
根据轨迹选择用于网络输入的观测值和动作。相应地,策略、值和奖励的预测目标是在生成存储的轨迹。
从下图可以看到过程生成(B)与训练(C)之间的一致性:
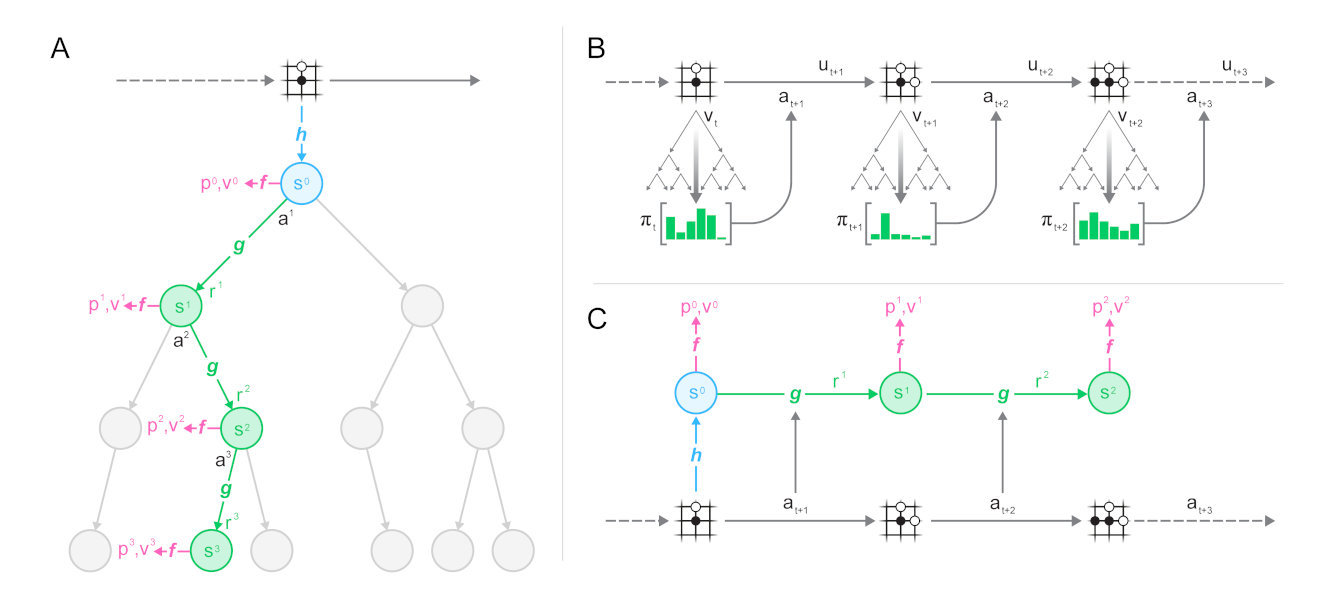
具体问言,MuZero估计量的训练损失为:
-
策略:MCTS访问统计信息与预测函数的策略logit之间的交叉熵;
-
值:N个奖励的折扣和+搜索值/目标网络估计值与预测函数的值之间的交叉熵或均方误差;
-
奖励:轨迹观测奖励与动态函数估计之间的交叉熵。
重分析
在了解了MuZero的核心思想后,接下来我们将介绍重分析技术,这将显著提高模型对大量数据的搜索效率。
在一般训练过程中,通过与环境的相互作用,我们会生成许多轨迹,并将其存储在重播缓冲区用于训练。那么,我们可以从该数据中获得更多信息吗?

很难。由于需要与环境交互,我们无法更改存储数据的状态、动作或奖励。在《黑客帝国》中可能做到,但在现实世界中则不可能。
幸运的是,我们并不需要这样。只要使用更新的、改进标签的现有输入,就足以继续学习。考虑到MuZero模型和MCTS,我们做出如下改进:
保持轨迹(观测、动作和奖励)不变,重新运行MCTS,就可以生成新的搜索统计信息,从而提供策略和值预测的新目标。
我们知道,在与环境直接交互过程中,使用改进网络进行搜索会获得更好的统计信息。与之相似,在已有轨迹上使用改进网络重新搜索也会获得更好的统计信息,从而可以使用相同的轨迹数据重复改进。
重分析适用于MuZero训练,一般训练循环如下:
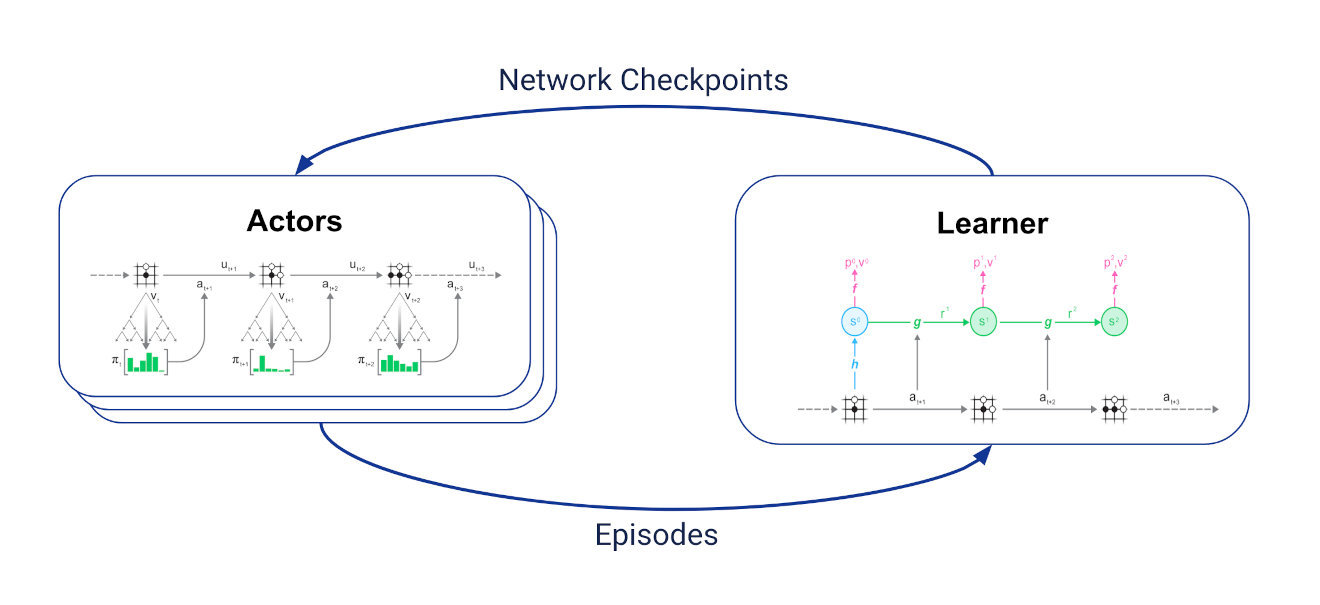
设置两组异步通信任务:
-
一个学习者接收最新轨迹,将最新轨迹保存在重播缓冲区,并根据这些轨迹进行上述训练;
-
多个行动者定期从学习者那里获取最新的网络检查点,并使用MCTS中的网络选择动作,与环境进行交互生成轨迹。
为实现重分析,引入两个新任务:
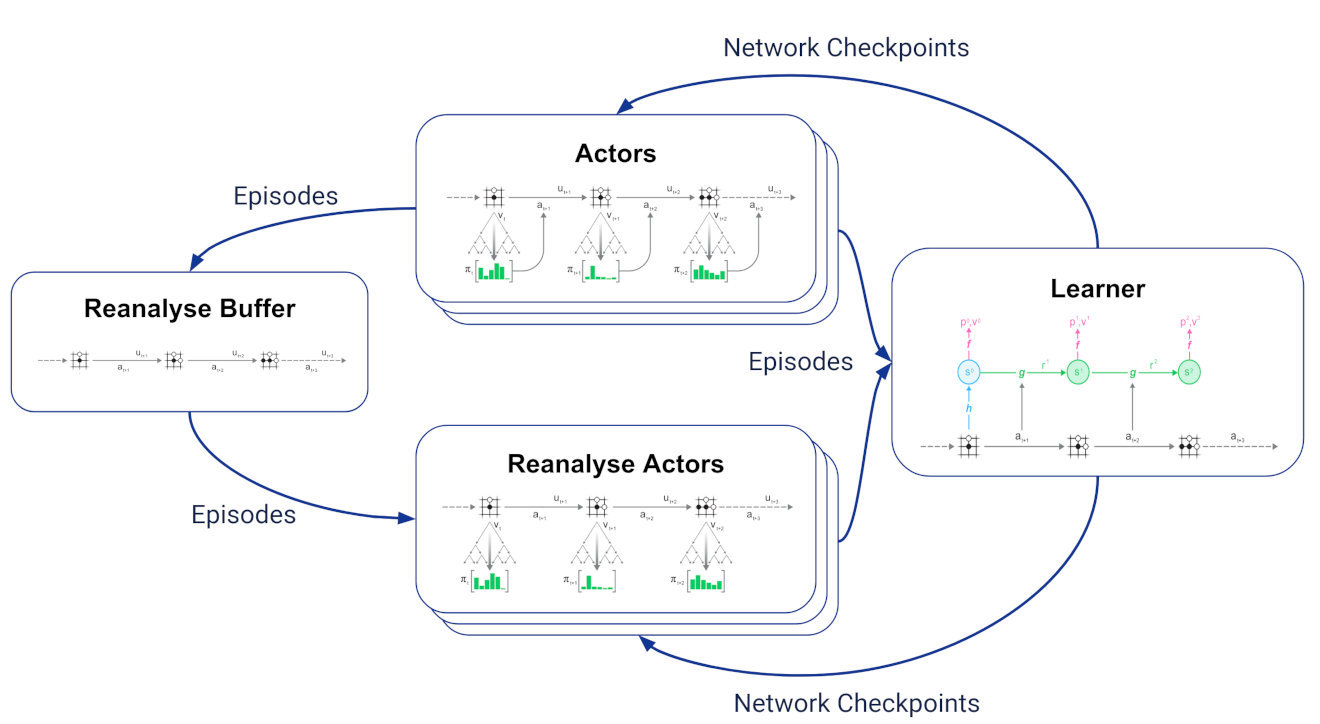
-
重分析缓冲区,用于接收参与者生成的所有轨迹并保留最新轨迹;
-
多个重分析行动者从重分析缓冲区采样存储的轨迹,使用学习者的最新网络检查点重新运行MCTS,并将生成的轨迹和更新的统计信息发送给学习者。
由于学习者无法区分新轨迹和重分析的轨迹,这使得新轨迹与重分析轨迹的比例更改变得简单。
MuZero命名含义
MuZero的命名基于AlphaZero,其中Zero表示是在没有模仿人类数据的情况下进行训练的,Mu取代Alpha表示使用学习模型进行规划。
更研究一些,Mu还有其他丰富的含义:
-
夢,日语中读作mu,表示“梦”的意思, 就像MuZero通过学习的模型来想象未来状况一样;
-
希腊字母μ(发音为mu)也可以表示学习的模型;
-
無, 日语发音为mu,表示“无、没有”,这强调从头学习的概念:不仅无需模仿人类数据,甚至不需提供规则。
结语
希望本文对MuZero的介绍对你有所启发!
如果想了解更多细节,可以阅读原文,还可以查看我在NeurIPS的poster以及在ICAPS上发表的关于MuZero的演讲。
最后,分享给你一些其他研究人员的文章,博客和GitHub项目:
<ahelp_12" name="help_12"></ahelp_12">
-
A Simple Alpha(Go) Zero Tutorial
-
MuZero General implementation
-
How To Build Your Own MuZero AI Using Python
-
为简单起见,在MuZero中仅使用单个网络进行预测。
-
根据Rémi Coulom在2006年发表的Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search,MCTS为解决围棋问题提供可能。具体而言,MCTS中的“蒙特卡洛”指在围棋比赛中的随机模拟数,通过计算每次随机移动得获胜概率从而选择合适位置。
-
MuZero中使用的比例因子为∑bn(s,b)√1+n(s,a)⋅(c1+log(∑bn(s,b)+c2+1c2)),其中n(s,a)表示从状态s到动作a的访问次数,常数c1和c2分别为1.25和19652,它们决定先验对于值估计得重要性。请注意,当c2远大于n时,c2的确切值不再重要,对数项此时为0。在这种情况下,公式简化为c1⋅∑bn(s,b)√1+n(s,a)c1。
-
就像AlphaGo之前的许多Go程序使用的随机卷展,随机评估函数有一定作用。但如果评估函数是确定性的(如标准神经网络),那么对同一节点多次评估没什么意义。
-
在棋盘游戏中,折扣因子γ为1,TD步数趋于无限,因此,这仅适用于对蒙特卡洛奖励(游戏获胜者)的预测。
-
在运行MuZero时,无需单独对行动者进行重分析:由于只有一组行动者,在每次行动之前决定是与环境交互生成新轨迹还是对存储轨迹进行重分析。