本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
2021年一开始,OpenAI在GPT-3方向上的又一重要突破,让吴恩达等大佬激动了。
之前给GPT-3一段话,就能写出一段小说。
现在它成功跨界——可以按照文字描述、生成对应图片!

简直就是“甲方克星、乙方福音”,提需求爱描述的甲方老板,现在直接哔哔就能立竿见影得到效果图。
比如你输入“OpenAI公司门面”,它就能给出设计图:

这个新的AI,叫做DALL·E(Dali + Wall-E)。
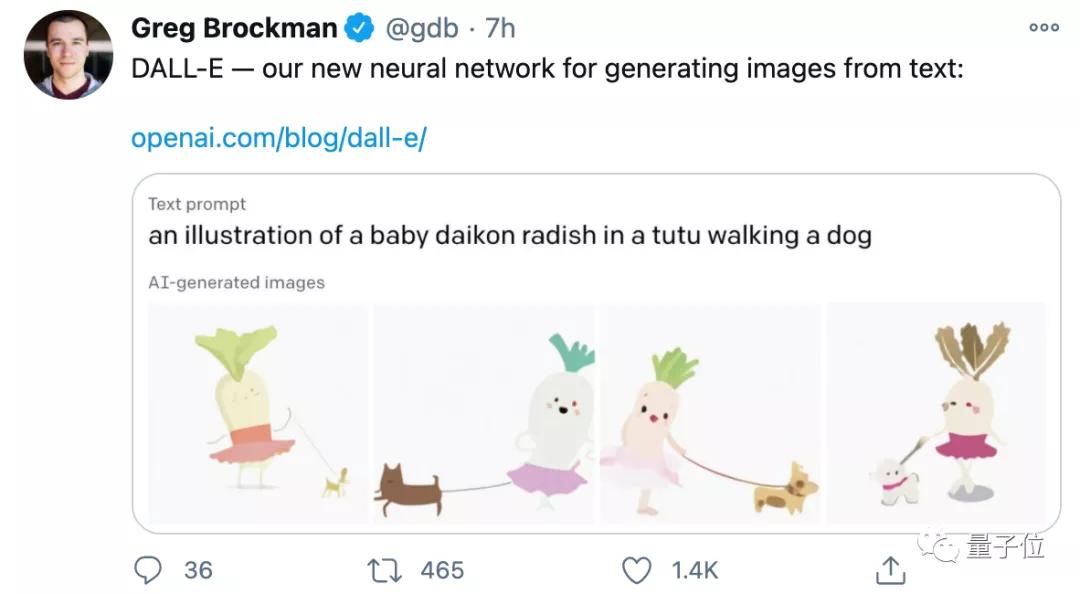
除了生成现实中的图片外,DALL·E还能按要求设计出“一颗白菜穿着芭蕾舞裙在遛狗”,妥妥的漫画风。

从“五边形闹钟”到“牛油果形状的座椅”,只要你的想象力够丰富,DALL·E全都能画出来。


技术上更厉害的是,OpenAI透露这个AI是基于GPT-3而构建,仅使用了120亿个参数样本,相当于GPT-3参数量的十四分之一。
于是效果一出,吴恩达、Keras之父等纷纷转发、点赞。堪称2021年第一个令人兴奋的AI技术突破。
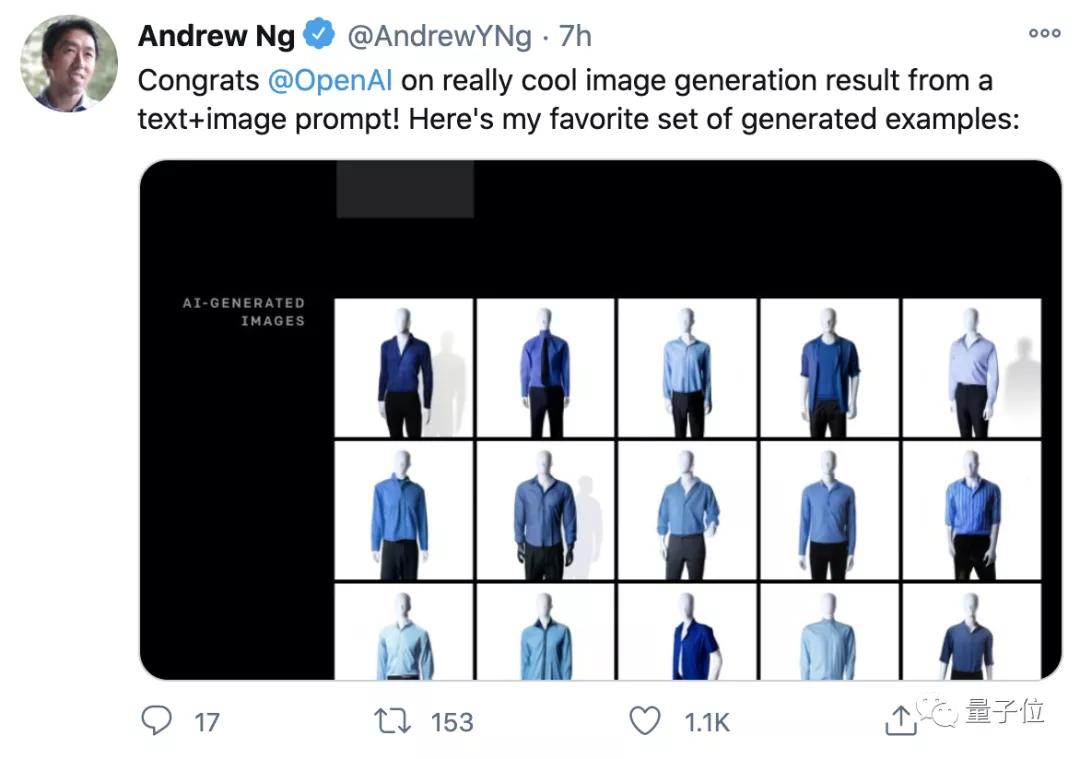
看吴恩达老师pick的这个demo效果,以后是想直接描述生成自己想要的蓝工装?
“图像版”GPT-3,还自带排名
生成这些优秀作品的,是一个名为DALL·E的结构。
DALL·E的名字,来源于大艺术家达利(Dalí)和皮克斯动画《机器人总动员》中的主角“瓦力”(WALL·E)。
本质上,它就是一个被重新训练过的“120亿参数版”GPT-3,能根据一段文字描述,生成对应的图像。
为了让DALL·E能“识字画图”,研究者们用包含各种“文本-图像”组合的数据集,来训练DALL·E。
这其中,DALL·E以单数据流的形式,一次性接收1280个字符(token),其中256个字符分配给文字,其余的1024个则分配给图像。

DALL·E将对这些输入信息进行建模,利用自注意力层的注意力遮罩,确保每一个输入的图像字符,都与所有输入的文字字符关联。
然后DALL·E将根据文本,通过最大似然估计,逐个字符生成图像。它不仅能从文字中,生成一整幅草图,还能重新生成图像中的任何一块矩形区域。

这就完了?
当然没有,我们最终看到的作品,其实只是DALL·E创作的一部分,即“优秀作品选”。
也就是说,还需要一个网络CLIP,来对它生成的这些作品进行排名、打分。
越是CLIP看得懂、匹配度最高的作品,分数就会越高,排名也会越靠前。
这种结构,有点像是利用生成对抗文本,以合成图像的GAN。不过,相比于利用GAN扩大图像分辨率、匹配图像-文本特征等方法,CLIP则选择了直接对输出进行排名。
据研究人员表示,CLIP网络的最大意义在于,它缓解了深度学习在视觉任务中,最大的两个问题。
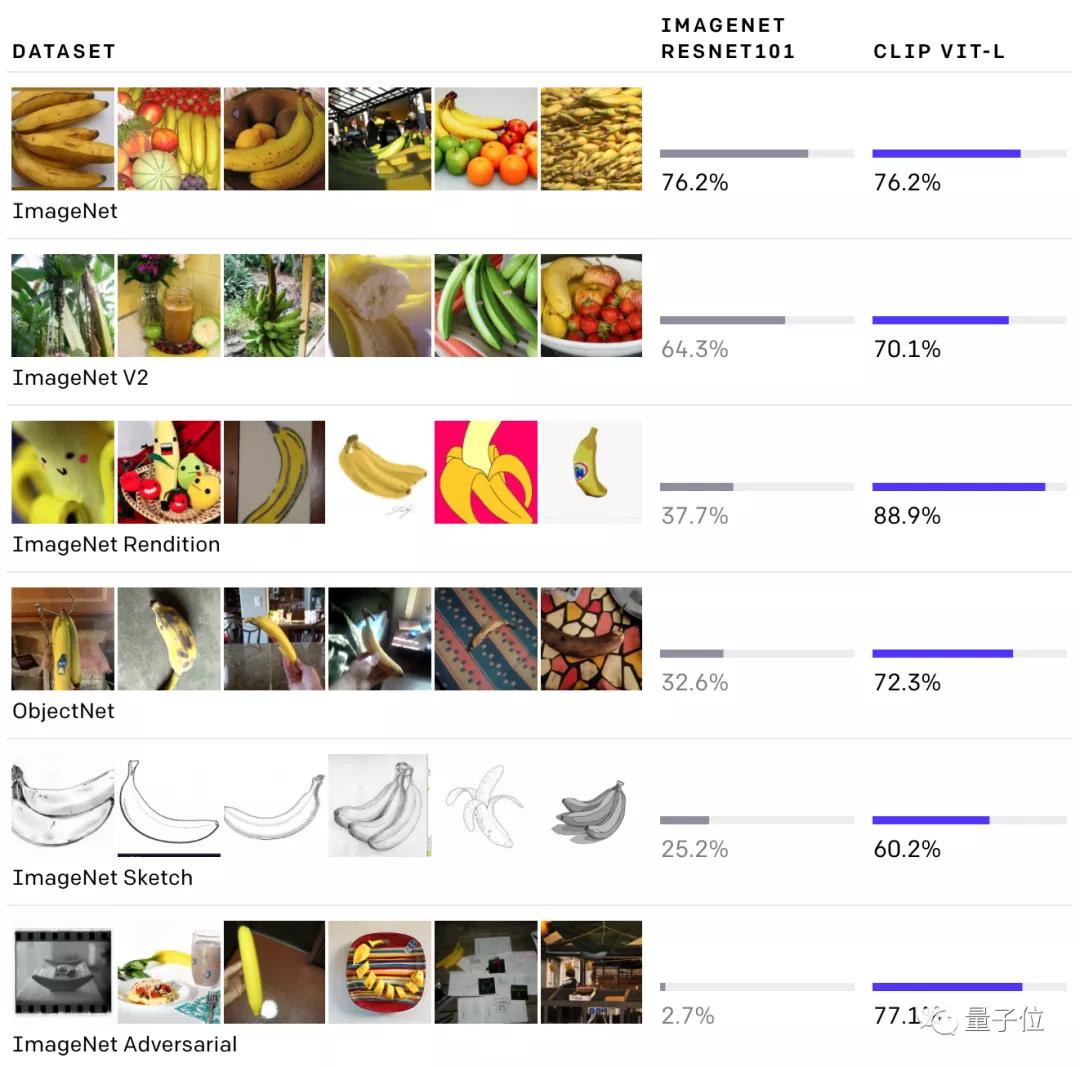
首先,它降低了深度学习需要的数据标注量。相比于手动在ImageNet上,用文字描述1400万张图像,CLIP直接从网上已有的“文字描述图像”数据中进行学习。

此外,CLIP还能“身兼多职”,在各种数据集上的表现都很好(包括没见过的数据集)。但此前的大部分视觉神经网络,只能在训练的数据集上有不错的表现。
例如,CLIP与ResNet101相比,在各项数据集上都有不错的检测精度,然而ResNet101在除了ImageNet以外的检测精度上,表现都不太好。
具体来说,CLIP用到了零样本学习(zero-shot learning)、自然语言理解和多模态学习等技术,来完成图像的理解。
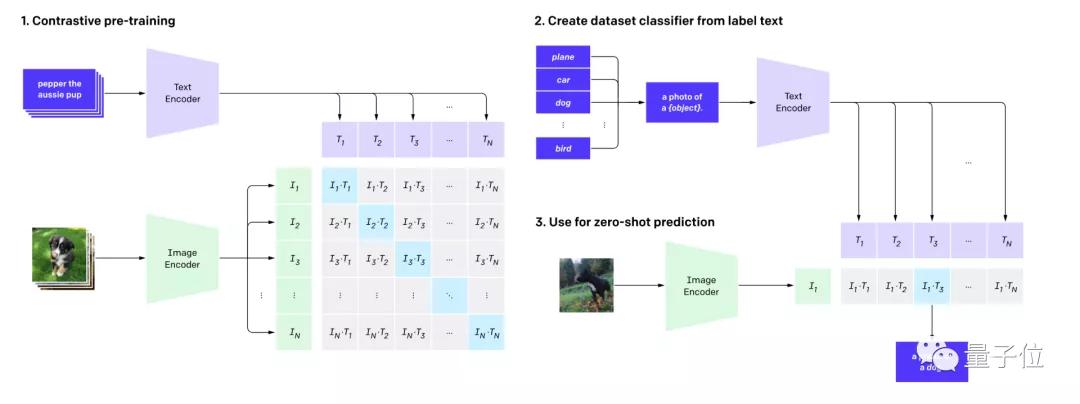
例如,描述一只斑马,可以用“马的轮廓+虎的皮毛+熊猫的黑白”。这样,网络就能从没见过的数据中,找出“斑马”的图像。
最后,CLIP将文本和图像理解结合起来,预测哪些图像,与数据集中的哪些文本能完成最好的配对。
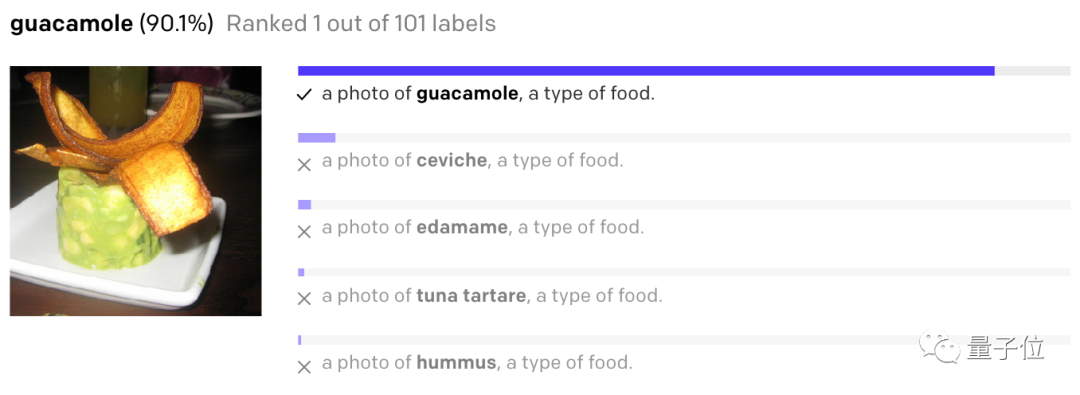
此次生成的Demo图像,正是从512个样本中,用CLIP选出的前32个样本。研究人员强调,整个过程他们全程没有参与。
有哪些初步效果?
此次上线的Demo,大致分成这几类效果。
控制变量,修改物体的属性(数量、颜色)。

甚至,还可以加上个年代属性。输入文字:电话。
那这个电话放在未来呢?竟然会是这个亚子。

同时控制多个对象。比如,戴红色帽子,黄色手套,蓝色衬衫和绿色裤子的企鹅。
说实话,要换成是我,我一个也画不出来。(手动裂开)

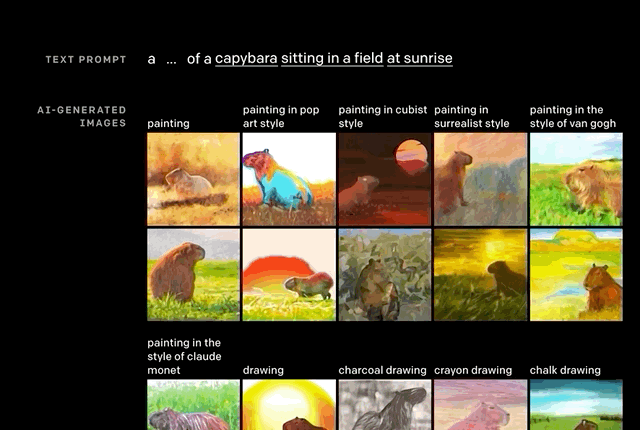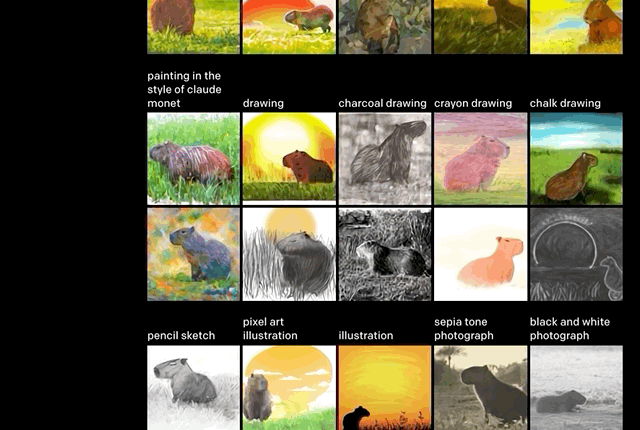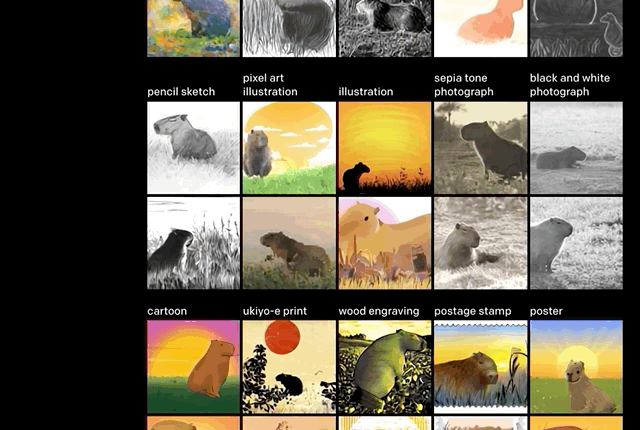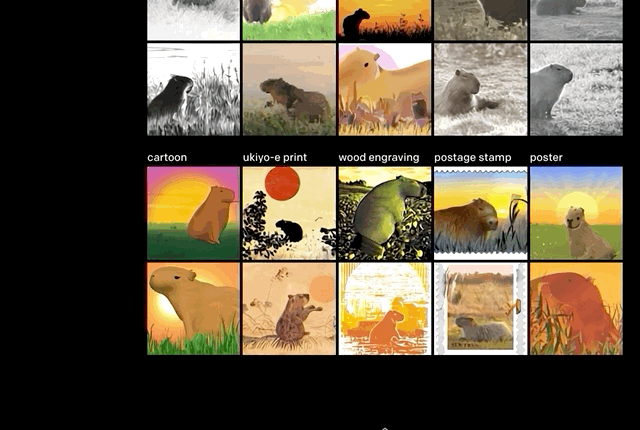
推断细节。正如上文举的例子,“沐浴在朝阳中的田间水豚”。
单从文字上看,还有很多细节需要考究:水豚位置,阴影有无,绘画风格。但这些,似乎都没有难到DALL·E。
大佬们纷纷给出好评
对于OpenAI这个新鲜出炉的DALL·E,大佬们也纷纷发表了自己的看法。
Keras创始人@François Chollet表示,这看起来非常酷,尤其是“图像生成”部分。
从原理上来看,应该就是GPT-3在文本合成图像方向上的扩展版。

OpenAI的CTO Greg Brockman在转发DALL·E后,更是立刻获得了1.4k的赞。
英伟达的机器学习专家Ming-Yu Liu,也送上了自己的祝福。
他表示,这样的模型在文本转图像的能力上,简直超乎想象。

当然,也有对这种方法的限制感到困惑的学者。
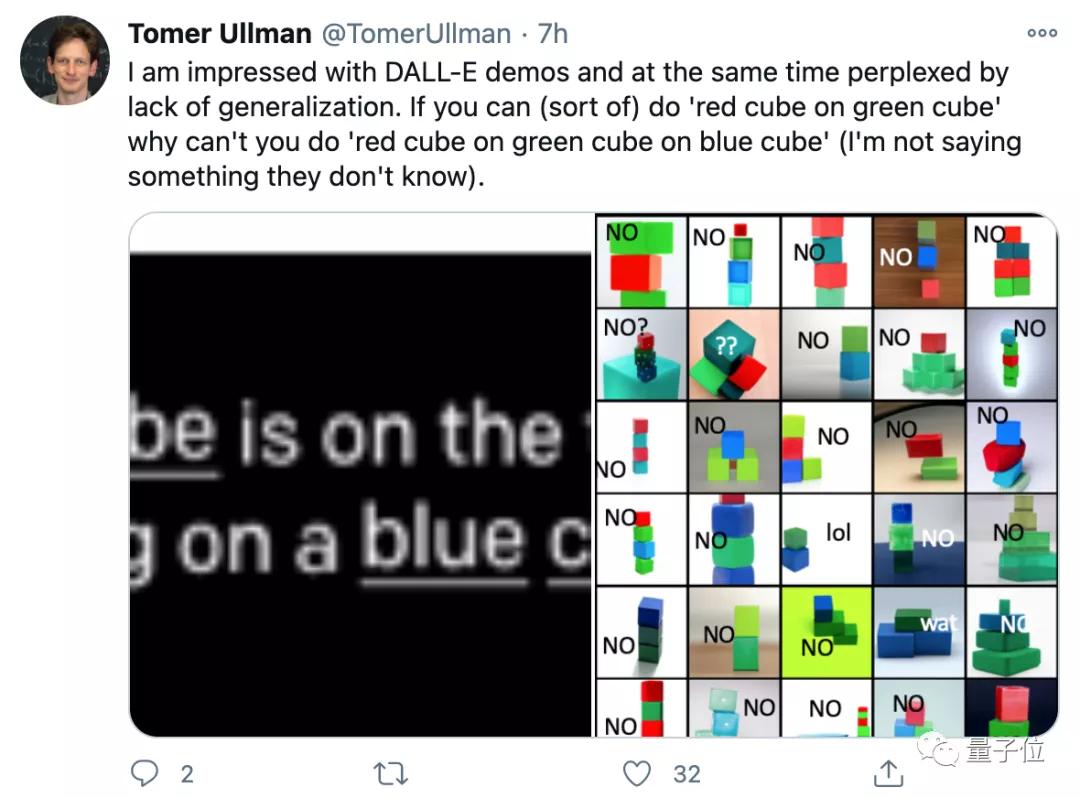
来自哈佛的助理教授Tomer Ullman,在对DALL·E的能力表示惊叹时,也提出了对于模型泛化能力限制的疑惑。
他认为,如果能生成“绿方块上的红方块”,模型理应也能生成“蓝方块上的绿方块上的红方块”?
希望这样的模型,能在提升泛化等能力后,真正被用来减轻设计师们的负担。
当然,如果再开一开脑洞的话,应用前景可能不止于减轻负担。
如果效果足够好,还要什么乙方设计师?
以及像动画、影视等领域,是不是未来剧本一放,AI就能给你出成果了?