













01 数据库的隐私威胁模型
目前,隐私保护技术在数据库中的应用主要集中在数据挖掘和数据发布两个领域。数据挖掘中的隐私保护(Privacy Protection Data Mining,PPDM)是指如何在能保护用户隐私的前提下进行有效的数据挖掘;数据发布中的隐私保护(Privacy Protection Data Publish,PPDP)是指如何在保护用户隐私的前提下发布用户的数据,以供第三方有效地研究和使用。
图1描述了数据收集和数据发布的一个典型场景。
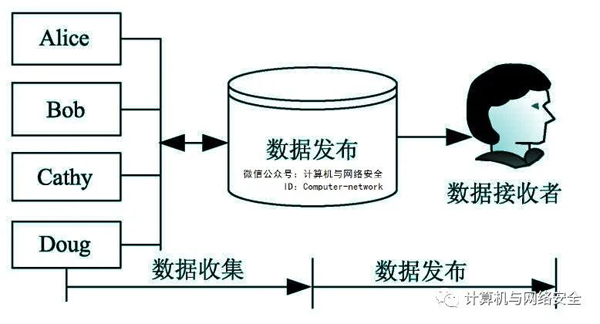
图1 数据收集和数据发布
在数据收集阶段,数据发布者从数据拥有者(如Alice,Bob等)处收集到了大量的数据。在数据发布阶段,数据发布者发布收集到的数据给挖掘用户或公共用户,这里也将他们称为数据接收者,它能够在发布的数据上进行有效的数据挖掘以便于研究和利用。这里讲的数据挖掘具有广泛的意义,并不仅限于模式挖掘和模型构建。例如,疾病控制中心须收集各医疗机构的病历信息,以进行疾病的预防与控制。某医疗机构从患者那里收集了大量的数据,并且把这些数据发布给疾病控制中心。本例中,医疗机构是数据发布者,患者是数据记录拥有者,疾病控制中心是数据接收者。疾病控制中心进行的数据挖掘可以是从糖尿病患者的简单计数到任何事情的聚类分析。
有两种计算模型针对数据发布者。在不可信计算模型中,数据发布者是不可信的,它可能会尝试从数据拥有者那里识别敏感信息。各种加密方法、匿名通信方法以及统计方法等都可用于从数据拥有者那里匿名收集数据而不泄露数据拥有者的身份标志。在可信计算模式中,数据发布者是可信的,而且数据拥有者也愿意提供他们的数据给数据发布者。但是,数据接收者是不可信的。
数据挖掘与知识发现在各个领域都扮演着非常重要的角色。数据挖掘的目的在于从大量的数据中抽取出潜在的、有价值的知识(模型或规则)。传统的数据挖掘技术在发现知识的同时会给数据的隐私带来严重威胁。例如,疾病控制中心在收集各医疗机构的病历信息的过程中,传统数据挖掘技术将不可避免地会暴露患者的敏感数据(如所患疾病),而这些敏感数据是数据拥有者(医疗机构、病人)不希望被揭露或被他人知道的。
02 数据库的隐私保护技术
隐私保护技术是为了解决数据挖掘和数据发布中的数据隐私暴露问题。隐私保护技术在具体实施时需要考虑以下两个方面:① 如何保证数据应用过程中不泄露数据隐私;② 如何更有利于数据的应用。下面分别对基于数据失真的隐私保护技术、基于数据加密的隐私保护技术、基于限制发布的隐私保护技术进行详细介绍。
1. 基于数据失真的隐私保护技术
数据失真技术是通过扰动原始数据来实现隐私保护的,扰动后的数据需要满足:① 攻击者不能发现真实的原始数据,即攻击者不能通过发布的失真数据并借助一定的背景知识重构出真实的原始数据;② 经过失真处理后的数据要能够保持某些性质不变,即利用失真数据得出的某些信息和从原始数据中得出的信息要相同,如某些统计特征要一样,这保证了基于失真数据的某些应用是可行的。
基于失真的隐私保护技术主要采用随机化、阻塞、凝聚等技术。
(1)随机化
数据随机化就是在原始数据中加入随机噪声,然后发布扰动后的数据。随机化技术包括随机扰动和随机应答两类。
① 随机扰动。随机扰动采用随机化技术来修改敏感数据,达到对数据隐私的保护。图2(a)给出了随机扰动的过程。攻击者只能截获或观察扰动后的数据,这样就实现了对真实数据X的隐藏,但是扰动后的数据仍然保留着原始数据的分布信息。通过对扰动数据进行重构,如图2(b)所示,可以恢复原始数据X的信息,但不能重构原始数据的精确值x1,x2,…,xn。

图2 随机扰动与重构过程
随机扰动技术可以在不暴露原始数据的情况下进行多种数据挖掘操作。由于扰动后的数据通过重构得到的数据分布几乎和原始数据的分布相同,因此,利用重构数据的分布进行决策树分类器训练后,得到的决策树能很好地对数据进行分类。在关联规则挖掘中,可以通过在原始数据中加入大量伪项来隐藏频繁项集,再通过在随机扰动后的数据上估计项集的支持度来发现关联规则。除此之外,随机扰动技术还可以被应用到联机分析处理(Online Analytical Processing,OLAP)上,实现对隐私的保护。
② 随机应答。随机应答是指数据拥有者在扰动原始数据后再将其发布,以使攻击者不能以高于预定阈值的概率得出原始数据是否包含某些真实信息或伪信息。虽然发布的数据不再真实,但是在数据量比较大的情况下,统计信息和汇聚信息仍然可以被较为精确地估计出来。随机应答和随机扰动的不同之处在于敏感数据是通过一种应答特定问题的方式提供给外界的。
(2)阻塞与凝聚
随机化技术的一个无法避免的缺点是:针对不同的应用都需要设计特定的算法以对转换后的数据进行处理,因为所有的应用都需要重建数据的分布。凝聚技术可以克服随机化技术的这一缺点,它的基本思想是:将原始数据分成组,每组内存储着由k条记录产生的统计信息,包括每个属性的均值、协方差等。这样,只要是采用凝聚技术处理的数据,都可以用通用的重构算法进行处理,并且重构后的数据并不会披露原始数据的隐私,因为同一组内的k条记录是两两不可区分的。
与随机化技术修改敏感数据、提供非真实数据的方法不同,阻塞技术采用的是不发布某些特定数据的方法,因为某些应用更希望基于真实数据进行研究。例如,可以通过引入代表不确定值的符号“?”来实现对布尔关联规则的隐藏。由于某些值被“?”代替,所以对某些项集的计数是一个不确定的值,此值位于一个最小估计值和最大估计值之间。于是,对敏感关联规则的隐藏就是在数据中的阻塞尽量少的情况下,将敏感关联规则可能的支持度和置信度控制在预定的阈值以下。另外,利用阻塞技术还可以实现对分类规则的隐藏。
2. 基于数据加密的隐私保护技术
基于数据加密的隐私保护技术多用于分布式应用中,如分布式数据挖掘、安全查询、几何计算、科学计算等。分布式应用的功能实现通常会依赖于数据的存储模式和站点的可信度及其行为。
分布式应用采用垂直划分和水平划分两种数据模式存储数据。垂直划分数据是指分布式环境中每个站点只存储部分属性的数据,所有站点存储的数据不重复;水平划分数据是将数据记录存储到分布式环境中的多个站点,所有站点存储的数据不重复。分布式环境下的站点,根据其行为可以分为准诚信攻击者和恶意攻击者。准诚信攻击者是遵守相关计算协议但仍试图进行攻击的站点;恶意攻击者是不遵守相关计算协议且试图披露隐私的站点。一般会假设所有站点为准诚信攻击者。
基于加密技术的隐私保护技术主要有安全多方计算、分布式匿名化、分布式关联规则挖掘、分布式聚类等。
(1)安全多方计算
安全多方计算协议是密码学中非常活跃的一个学术领域,它有很强的理论和实际意义。一个简单安全多方计算的实例就是著名华人科学家姚期智提出的百万富翁问题:两个百万富翁Alice和Bob都想知道他俩谁更富有,但他们都不想让对方知道关于自己财富的任何信息。
按照常规的安全协议运行之后,双方只知道谁更加富有,而对对方具体有多少财产却一无所知。
通俗地讲,安全多方计算可以被描述为一个计算过程:两个或多个协议参与者基于秘密输入来计算一个函数。安全多方计算假定参与者愿意共享一些数据用于计算。但是,每个参与者都不希望自己的输入被其他参与者或任何第三方知道。
一般来说,安全多方计算可以看成是在具有n个参与者的分布式网络中私密输入为x1,x2,…,xn的计算函数f(x1,x2,…,xn),其中参与者i仅知道自己的输入xi和输出f(x1,x2,…,xn),再没有任何其他多余信息。如果假设有可信第三方存在,则这个问题的解决就会变得十分容易,参与者只需要将自己的输入通过秘密通道传送给可信第三方,由可信第三方计算这个函数,然后将计算结果广播给每一个参与者即可。但是在现实中很难找到一个让所有参与者都信任的可信第三方。因此,安全多方计算协议主要是针对在无可信第三方的情况下安全计算约定函数的问题。
众多分布式环境下基于隐私保护的数据挖掘应用都可以抽象成无可信第三方参与的安全多方计算问题,即如何使两个或多个站点通过某种协议完成计算后,每一方都只知道自己的输入和所有数据计算后的结果。
由于安全多方计算基于了“准诚信模型”这一假设,因此其应用范围有限。
(2)分布式匿名化
匿名化就是隐藏数据或数据来源,因为大多数应用都需要对原始数据进行匿名处理以保证敏感信息的安全,然后在此基础上进行数据挖掘与发布等操作。分布式下的数据匿名化都面临在通信时如何既保证站点数据隐私又能收集到足够信息以实现利用率尽量大的数据匿名这一问题。
以在垂直划分的数据环境下实现两方分布式k-匿名为例来说明分布式匿名化。假设有两个站点S1、S2,它们拥有的数据分别是{ID,A1,A2,…,An}和{ID,B1,B2,…,Bn},其中,Ai为S1拥有数据的第i个属性。利用可交换加密在通信过程中隐藏原始信息,在构建完整的匿名表时判断是否“满足k-匿名条件”先实现。分布式k-匿名算法如下所示。
输入:站点S1、S2,数据{ID,A1,A2,…,An}、{ID,B1,B2,…,Bn}
输出:k-匿名数据表T×
过程:
① 2个站点分别产生私有密钥K1和K2,且须满足:EK1(EK2(D))=EK2(EK1(D)),其中D为任意数据。
② 表T×←NULL。
③ while T×中数据不满足k-匿名条件 do。
④ 站点i(i=1或2)
a. 泛化{ID,A1,A2,…,An}为{ID,A1×,A2×,…,An×},其中A1×表示A1泛化后的值;
b. {ID,A1,A2,…,An}←{ID,A1×,A2×,…,An×};
c. 用Ki加密{ID,A1×,A2×,…,An×}并将其传递给另一站点;
d. 用Ki加密另一站点加密的泛化数据并回传;
e. 根据两个站点加密后的ID值对数据进行匹配,构建经K1和K2加密后的数据表T×{ID,A1×,A2×,…,An×,ID,B1,B2,…,Bn}。
⑤ end while。
在水平划分的数据环境中,可以通过引入第三方,利用满足性质的密钥来实现数据的k-匿名化:每个站点加密私有数据并将其传递给第三方,当且仅当有k条数据记录的准标志符属性值相同时,第三方的密钥才能将这k条数据记录进行解密。
(3)分布式关联规则挖掘
在分布式环境下,关联规则挖掘的关键是计算项集的全局计数,加密技术能保证在计算项集计数的同时,不会泄露隐私信息。例如,在数据垂直划分的分布式环境中,需要解决的问题是:如何利用分布在不同站点的数据计算项集计数,找出支持度大于阈值的频繁项集。此时,在不同站点之间计数的问题被简化为在保护隐私数据的同时,在不同站点间计算标量积的问题。
(4)分布式聚类
基于隐私保护的分布式聚类的关键是安全地计算数据间的距离,聚类模型有Naïve聚类模型(K-means)和多次聚类模型,两种模型都利用了加密技术来实现信息的安全传输。
① Naïve聚类模型:各个站点将数据加密方式安全地传递给可信第三方,由可信第三方进行聚类后返回结果。
② 多次聚类模型:首先各个站点对本地数据进行聚类并发布结果,然后通过对各个站点发布的结果进行二次处理,实现分布式聚类。
3. 基于限制发布的隐私保护技术
限制发布是指有选择地发布原始数据、不发布或者发布精度较低的敏感数据以实现隐私保护。当前基于限制发布的隐私保护技术主要采用数据匿名化技术,即在隐私披露风险和数据精度之间进行折中,有选择地发布敏感数据及可能披露敏感数据的信息,但保证敏感数据及隐私的披露风险在可容忍的范围内。
数据匿名化一般采用两种基本操作。
① 抑制。抑制某数据项,即不发布该数据项。
② 泛化。泛化指对数据进行更抽象的和概括性的描述。例如,可把年龄30岁泛化成区间[20,40]的形式,因为30在区间[20,40]内。
数据匿名化处理的原始数据一般为数据表形式,表中每一行都是一个记录,对应一个人。每条记录包含多个属性(数据项),这些属性可分为3类。
① 显式标志符(explicit identifier),能唯一表示单一个体的属性,如身份证、姓名等。
② 准标志符(quasi-identifiers),几个属性联合起来可以唯一标志一个人,如邮编、性别、出生年月等联合起来可能就是一个准标志符。
③ 敏感属性(sensitive attribute),包含用户隐私数据的属性,如疾病、收入、宗教信仰等。
表1所示为某家医院的原始诊断记录,每一条记录(行)都对应一个唯一的病人,其中{“姓名”}为显示标志符属性,{“年龄”“性别”“邮编”}为准标志符属性,{“疾病”}为敏感属性。
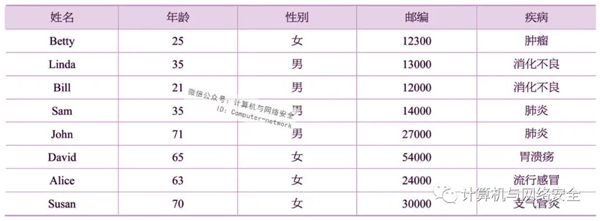
表1 某医院原始诊断记录
传统的隐私保护方法是先删除表1中的显示标志符“姓名”,然后再将其发布出去。表2给出了表1的匿名数据。假设攻击者知道表2中有Betty的诊断记录,而且攻击者知道Betty年龄是25岁,性别是女,邮编是12300,则根据表2,攻击者可以很容易地确定Betty对应表中的第一条记录。因此,攻击者可以肯定Betty患了肿瘤。
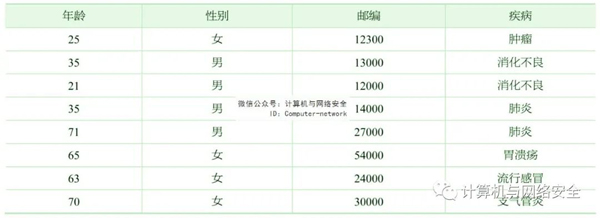
表2 某医院原始诊断记录(匿名)
显然,由传统的数据隐私保护算法得到匿名数据不能很好地阻止攻击者根据准标志符信息推测目标个体的敏感信息。因此,需要有更加严格的匿名处理方法以达到保护数据隐私的目的。
(1)数据匿名化算法
大多数匿名化算法致力于解决根据通用匿名原则怎样更好地发布匿名数据这一问题,另一方面则致力于解决在具体应用背景下,如何使发布的匿名数据更有利于应用。
① 基于通用原则的匿名化算法
基于通用原则的匿名化算法通常包括泛化空间枚举、空间修剪、选取最优化泛化、结果判断与输出等步骤。基于通用原则的匿名化算法大都基于k-匿名算法,不同之处仅在于判断算法结束的条件,而泛化策略、空间修剪等都是基本相同的。
② 面向特定目标的匿名化算法
在特定的应用场景下,通用的匿名化算法可能不能满足特定目标的要求。面向特定目标的匿名化算法就是针对特定应用场景的隐私化算法。例如,考虑到数据应用者需要利用发布的匿名数据构建分类器,因此设计匿名化算法时就需要考虑在保护隐私的同时,怎样使发布的数据更有利于分类器的构建,并且采用的度量指标要能直接反映出对分类器构建的影响。已有的自底向上的匿名化算法和自顶向下的匿名化算法都将信息增益作为度量。发布的数据信息丢失越少,构建的分类器的分类效果越好。自底向上的匿名化算法会在每次搜索泛化空间时,采用使信息丢失最少的泛化方案进行泛化,重复执行以上操作直到数据满足匿名原则的要求为止。自顶向下的匿名化算法的操作过程则与之相反。
③ 基于聚类的匿名化算法
基于聚类的匿名化算法将原始记录映射到特定的度量空间,再对空间中的点进行聚类以实现数据匿名。类似k-匿名,算法保证每个聚类中至少有k个数据点。根据度量的不同,有r-gather和r-cellular两种聚类算法。在r-gather算法中,以所有聚类中的最大半径为度量对所有数据点进行聚类,在保证每个聚类至少包含k个数据点时,所有聚类中的最大半径越小越好。
基于聚类的匿名化算法主要面临以下两个挑战。
a. 如何对原始数据的不同属性进行加权(因为对属性的度量越准确,聚类的效果就越好)?
b. 如何使不同性质的属性同意映射到同一度量空间?
数据匿名化由于能处理多种类型的数据,并发布真实的数据,因此能满足众多实际应用的需求。图3所示是数据匿名化的场景及相关隐私匿名实例。可以看到,数据匿名化是一个复杂的过程,需要同时权衡原始数据、匿名化技术、匿名数据、背景知识、攻击者等众多因素。

图3 数据匿名化场景
(2)k-匿名规则
基于k-匿名规则演化的各种数据发布方式将原始数据表中的属性分成了以下3类。
① 标志符属性
标志符属性是指唯一标志身份的个体属性,这种属性必须在数据发布之前从数据表中全部抹掉,如用户姓名、电话号码、身份证号码、联系方式等。
② 敏感属性
通常,包含了个体隐私信息的属性称为敏感属性,如身体健康状况、收入水平、年龄、籍贯等。
③ 准标志符属性
通过某些单个属性的连接来标志个体的唯一身份的属性,称为准标志符属性,其能够进行共享,也有可能会通过与其他的外部数据表进行连接而泄露隐私信息。
k-匿名规则:是指要求其在所发布的数据表中的每一条记录,不能区别于其他k-1(k为正整数)条记录,这些不能相互区分的k条记录称为一个等价类。
等价类:就是在准标志符上的投影完全相同的记录所组成的等价组,它是针对非敏感属性值而言的,是不能被区分的。
全局泛化:指对于每一个相同的簇,至少包含k个元组,它们对于簇中准标志符的属性的取值完全相同,即属性均被泛化。如表3所示,这是一个对于年龄属性全局泛化的例子,年龄在所有簇中的取值相同。
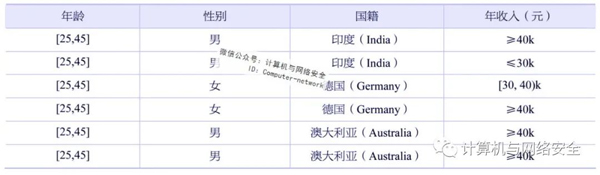
表3 年龄属性全局泛化的k-匿名表
局部泛化:指每个簇中的准标志符属性相同,并且均大于k,但是簇间的属性泛化后的值却不相同。局部泛化的k-匿名表如表4所示。

表4 局部泛化的k-匿名表
在传统k-匿名的基础上,人们从多个方面对k-匿名进行了优化和改进。改进后的算法主要有多维k-匿名算法、Datefly 算法、Incognito 算法、Classfly 算法、Mingen 算法等。
k-匿名方法通常采用泛化和压缩技术对原始数据进行匿名化处理以便得到满足k-匿名规则的匿名数据,从而使得攻击者不能根据发布的匿名数据准确地识别出目标个体的记录。
k-匿名规则要求每个等价类中至少包含k条记录,即匿名数据中的每条记录都至少不能和其他k-1条记录区分开来,这样可以防止攻击者根据准标志符属性识别目标个体对应的记录。一般k值越大对隐私的保护效果越好,但丢失的信息越多,数据还原越难。
表5给出了使用泛化技术得到的表2的k=4时的k-匿名数据(简称4-匿名数据)。
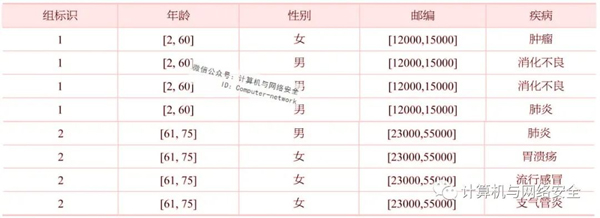
表5 4-匿名数据
k-匿名规则切断了个体与数据库中某条具体记录的联系,可以防止敏感属性值泄露,而且每个个体身份被准确标志的概率最大为1/k,这在一定程度上保护了个人隐私。然而,数据表在匿名化过程中并未对敏感属性做任何约束,这也可能会导致隐私泄露。k-匿名的泛化技术的思想是将原始数据中的记录划分成多个等价类,并用更抽象的值替换同一等价类中记录的准标志符属性值,使每个等价类中的记录都拥有相同的准标志符属性值。这样,同一等价类内若敏感属性值较为集中,甚至完全相同(可能在形式上,也可能在语义上),则即使满足k-匿名要求,也很容易推理出与指定个体相应的敏感属性值。除此之外,攻击者也可以通过自己掌握的足够的相关背景知识以很高的概率来确定敏感数据与个体的对应关系,从而导致隐私泄露。因此,攻击者可以根据准标志符属性值来区分同一等价类的所有记录。
k-匿名方法的缺点在于并没有考虑敏感属性的多样性问题,攻击者可以利用一致性攻击(homogeneity attack)和背景知识攻击(background knowledge attack)来确认敏感数据与个人的联系,进而导致隐私泄露。
常见的针对匿名化模型的攻击方式有以下4种。
① 链接攻击:某些数据集存在其自身的安全性,即孤立情况下不会泄露任何隐私信息,但是当恶意攻击者利用其他存在属性重叠的数据集进行链接操作时,便可能唯一识别出特定的个体,从而获取该个体的隐私信息。将医疗信息和选举人信息结合在一起,能够发现两个数据集的共有属性,这样,恶意攻击者通过链接攻击就能够轻易确定选举人的医疗信息情况。因此,该类攻击手段会造成极其严重的隐私泄露。
② 同质攻击:当通过链接攻击仍然无法唯一确认个体时,存在个体对应的多条记录拥有同一条敏感隐私信息,从而造成隐私的泄露,这一过程称为同质攻击。
③ 相似性攻击:由于敏感信息往往存在敏感度类似的情况,因此攻击者虽然无法唯一确定个体,但是如果个体对应的多条记录拥有相似的敏感信息,则可推测出个体的大概隐私情况。例如,某个体患有极其不愿为人所知的疾病,这也属于一种无法回避的严重攻击。虽然该攻击类似于同质攻击,并且不如同质攻击泄露得那么直接,但其发生的可能性极大,给被泄露者造成的心理压力往往难以预料,因此需要特别重视此种攻击手段。
④ 背景知识攻击:指攻击者掌握了某个体的某些具体信息,通过链接攻击后即使只能得到某个体对应的多条信息记录,并且记录间的敏感属性也完全不同或不相似,也能根据所掌握的背景知识,从多条信息记录中找出唯一对应的信息记录,从而获取到该个体的隐私信息。
(a,k)-匿名规则、l-多样性规则、t-逼近规则等算法在此基础之上都进行了相应程度的改进。
(3)(a,k)-匿名模型
(a,k)-匿名模型是一种扩展后的k-匿名模型,其目的是保护标志属性与敏感信息之间的关联关系不被泄露,从而防止攻击者根据已经知道的准标志符属性的信息找到敏感属性值。该模型要求发布的数据值在满足k-匿名原则的同时,还需要保证这些数据里包含的每个等价类中任意一个敏感属性值出现的次数与等价类个数的百分比小于a。
a表示某个敏感属性可以接受的最大泄露概率,它所反映的是一个隐私属性值所应该受到的保护程度,因此a的设置至关重要,它是根据每个敏感属性值的重要程度设置的。a的数值越小,该敏感属性值的泄露概率就越小,隐私保护程度就越高。a的数值越大,该敏感属性值的泄露概率就越大。
例如,在处理工资信息时,需要重点关注的是超高收入人群和超低收入人群,这是因为往往这两个群体会更加在意他们的工资信息是否被泄露。然而对于那些工资处于平均水平的人群来说,他们对个人工资信息的保护欲则较低。这种情况下,敏感属性值就可以设置得大一些,甚至可以设为1。可以理解为该敏感属性值与保护等级相关联。通过设定阈值a,能更加有效地防止隐私信息的泄露,从而提高隐私信息的保护程度。
如表6所示,在外部数据表中,姓名为标志符属性,已经将其删除。年龄、性别、国籍为准标志符属性,年收入为敏感属性。给定数据表RT(A1,A2,…,An),QI是与RT相关联的准标志符。若仅在RT [QI]中出现的每个值序列,至少在RT[QI]中出现过k次,这里的k=2,则RT就满足k-匿名。若敏感属性中的每个取值出现的频率都小于a,这里a设置为0.5,则RT就满足(a,k)-匿名。

表6 (0.5,2)-匿名表
(4)l-多样性规则
为了解决同质性攻击和背景知识攻击所带来的隐私泄露问题,研究人员在k-匿名规则的基础上提出了l-多样性(l-diversity)规则。
如果说数据表RT′满足k-匿名规则,且在同一等价类中的元组至少有l个不同的敏感属性,则称数据表RT′满足l-多样性规则。
l-多样性规则建立在k-匿名规则的基础之上,其意义在于解决属性链接,降低敏感属性和准标志属性之间的相关联程度。该规则除了要求等价类中的元组数大于k以外,还要满足每组元组至少有l个不同的敏感属性。在一定程度上而言,l-多样性规则与(a,k)-匿名规则的意义类似。表7所示是满足2-多样性规则的匿名信息表,在每个等价类中,敏感属性收入取值均大于或等于2,因此我们可以说表7满足2-多样性规则。
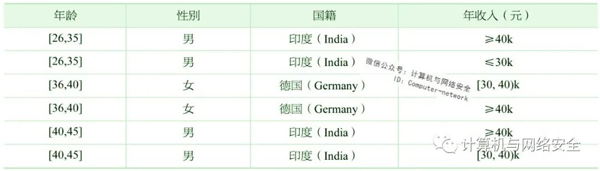
表7 2-多样性表
同理,表5发布的数据不仅满足4-匿名规则,这满足3-多样性规则,即每个等价类中至少有3个不同的敏感属性。
显然,l-多样性规则仍然将原始数据中的记录划分成了多个等价类,并利用泛化技术使每个等价类中的记录都拥有相同的准标志符属性,但是l-多样性规则要求每个等价类中至少有l个不同的敏感属性。因此,l-多样性规则会使得攻击者最多以1/l的概率确认某个体的敏感信息。
此外,l-多样性规则仍然采用泛化技术来得到满足隐私要求的匿名数据,而泛化技术的根本缺点在于丢失了原始数据中的大量信息。因此l-多样性规则仍未解决k-匿名规则会丢失原始数据中的大量信息这一问题。另外,l-多样性规则还不能阻止相似攻击(similarity attack)。
(5)t-逼近规则
t-逼近(t-closeness)规则要求匿名数据中的每个等价类中敏感属性值的分布接近于原始数据中的敏感属性值的分布,两个分布之间的距离不超过阈值t。t-closeness规则可以保证每个等价类中的敏感属性值具有多样性的同时在语义上也不相似,从而使其自身能够阻止相似攻击。但是,t-closeness规则只能防止属性泄露,却不能防止身份泄露。因此,t-closeness规则通常与k-匿名规则同时使用以防止身份泄露。另外,t-closeness规则仍是采用泛化技术的隐私规则,在很大程度上降低了数据发布的精度。
(6)Anatomy方法
Anatomy是肖小奎等人提出的一种高精度的数据发布隐私保护方法。Anatomy首先利用原始数据产生满足l-多样性规则的数据划分,然后将结果分成两张数据表发布,一张表包含每个记录的准标志符属性值和该记录的等价类ID,另一张表包含等价类ID、每个等价类的敏感属性值及其计数。这种将结果“切开”发布的方法,在提高准标志符属性值的同时,保证了发布的数据满足l-多样性规则,对敏感数据提供了较好的保护。















