我们在使用各种编程语言进行多线程编程时,经常会用到thread local变量。
所谓thread local变量,就是对于同一个变量,每个线程都有自己的一份,对该变量的访问是线程隔离的,它们之间不会相互影响,所以也就不会有各种多线程问题。
正确的使用thread local变量,能极大的简化多线程开发。所以不管是c/c++/rust,还是java/c#等,都内置了对thread local变量的支持。
但你知道吗,不仅是在编程语言中,在linux内核中,也有一个类似的机制,用来实现类似的目的,它叫做percpu变量。
percpu变量,顾名思义,就是对于同一个变量,每个cpu都有自己的一份,它可以被用来存放一些cpu独有的数据,比如cpu的id,cpu上正在运行的线程等等,因该机制可以非常方便的解决一些特定问题,所以在内核编程中被广泛使用。
好奇的你们肯定都在问,它是怎么实现的呢?
我们先不管细节,先来看一张图,这样从全局的角度来了解下它的实现。
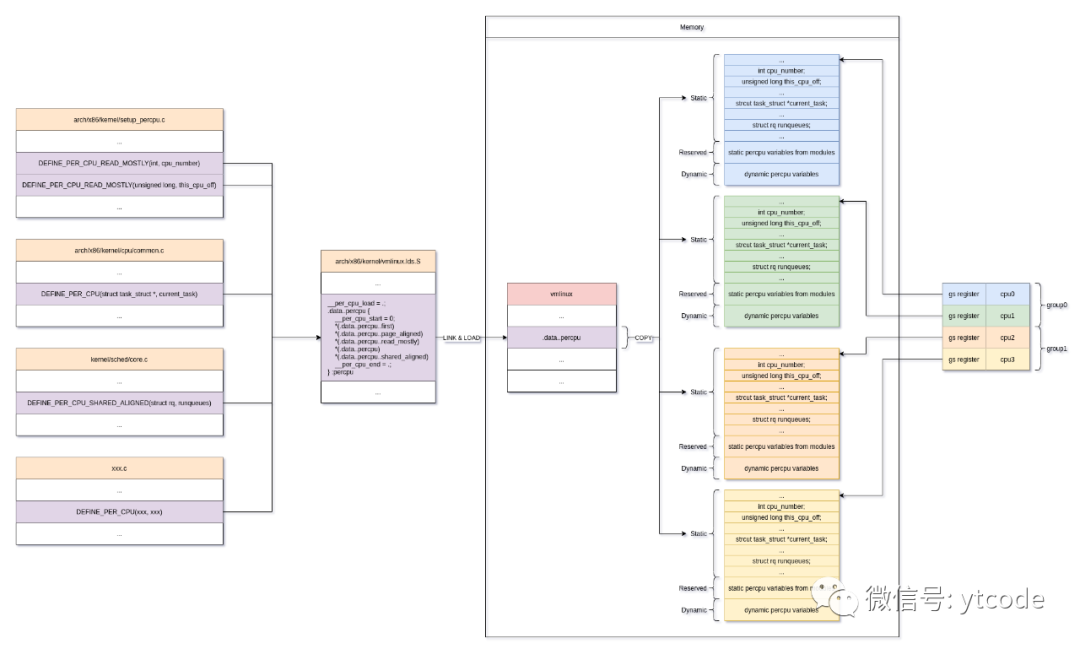
从上图中我们可以看到,各种源文件中通过DEFINE_PER_CPU的方式,定义了很多percpu变量,这些变量根据vmlinux.lds.S中的相关定义,会被linker聚合在一起,然后放到最终vmlinux文件的,一个名叫.data..percpu的section里。
这些变量的地址也是被特殊处理过的,它们从零开始依次递增,这样一个变量的地址,就是该变量在整个vmlinux的.data..percpu区里的位置,有了这个位置,然后再知道某个cpu的percpu内存块的起始地址,就可以很方便的计算出该cpu对应的该变量的运行时内存地址。
linux内核在启动时,会先把vmlinux文件加载到内存中,然后根据cpu的个数,为每个cpu都分配一块用于存放percpu变量的内存区域,之后把vmlinux中的.data..percpu section里的内容,拷贝到各个cpu的percpu内存块的static区域里,最后将各percpu内存块的起始地址放到对应cpu的gs寄存器里。
到这里有关percpu变量的初始化工作就已经结束了。
当我们在访问percpu变量时,只需要将gs寄存器里的地址,加上我们想要访问的percpu变量的地址,就能得到在该cpu上,该percpu变量真实的内存地址。
有了这个地址,我们就可以方便的操作这个percpu变量了。
上图中重点描述的是那些,在内核编译期就已经确定的percpu变量,这些变量是静态的,是不会随着时间的推移而动态的增加或减少的,所以它们在内核初始化时,就直接被拷贝到了各个percpu内存块的static区。
除了这种静态percpu变量,还有另外两种percpu变量。
其中一种是内核模块中的静态percpu变量,它虽然也是在编译期就能确定的,但由于内核模块动态加载的特性,它不是完全静态的,内核为这种percpu变量在percpu内存块中单独开辟了一个区域,叫reserved区,当内核模块被加载到内存时,其静态percpu变量就会在这个区域分配内存。
另外一种percpu变量就是纯动态的percpu变量,它是在运行时动态分配的,它使用的内存是上图中的dynamic区。
static区的大小是在编译期就算好的,是固定不变的,reserved区也是固定不变的,但其大小是预估的,dynamic区是可以动态增加的。
虽然这三种percpu变量的分配方式不同,但它们的内在机制本质上都是一样的,所以这里我们只讲内核里的静态percpu变量,对其他两种方式感兴趣的同学,可以参考内核源码自己研究下。
下面我们就用一个具体的例子,来看下percpu变量到底是怎么实现的。
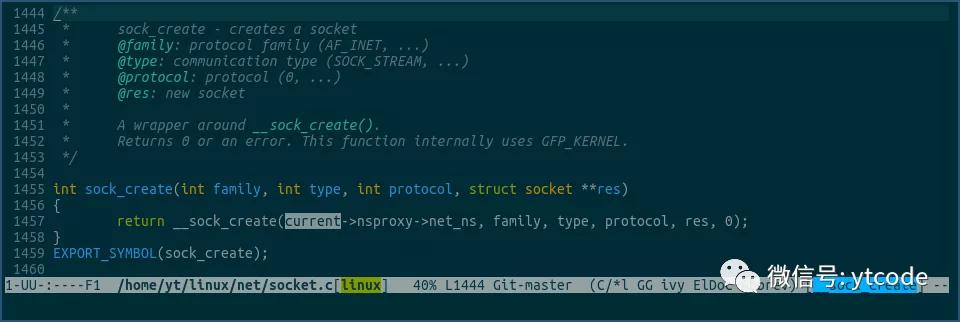
上图中的current表示要获取当前线程对象,它其实是一个宏,具体定义如下:
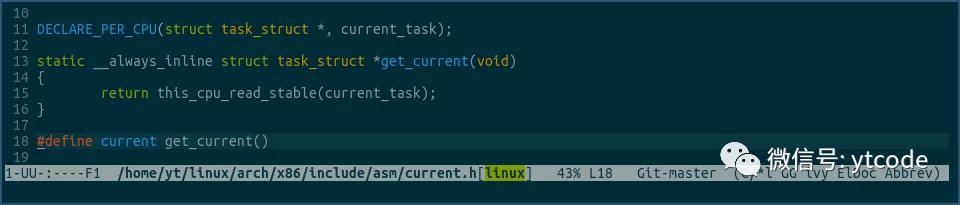
由上可见,current获取的当前线程对象其实是一个名为current_task的percpu变量。
在get_current方法中,通过this_cpu_read_stable方法,获取属于当前cpu的current_task。
this_cpu_read_stable方法其实也是一个宏,它全部展开后是下面这个样子:
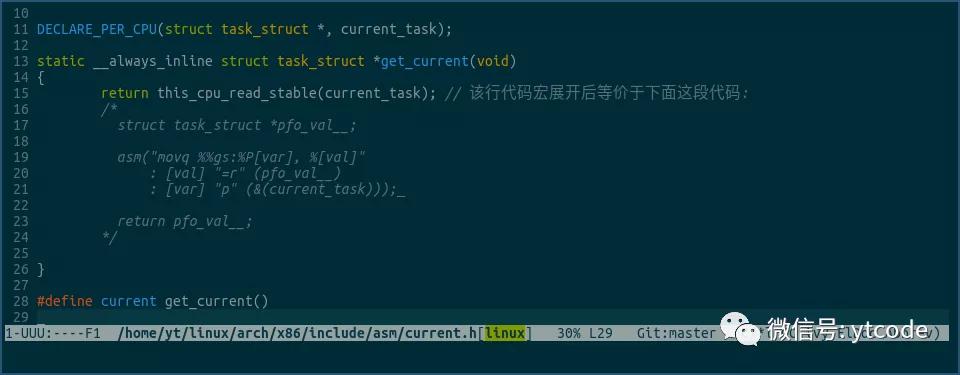
在这里,我们先不讲宏展开后各语句到底是什么意思,我们先跑个题。
读过linux内核源码的同学都知道,在linux内核中,宏使用的非常多,且比较复杂,如果我们对自己进行宏展开的正确性没有信心的话,可以使用下面我介绍的这个方式,使用它,你可以非常容易的得到任意文件宏展开后的结果。
我们知道,一个程序的构建分为预处理、编译、汇编、链接这些阶段,而宏展开就发生在预处理阶段。
各个阶段在完成后,一般都会生成一个临时文件给下一阶段使用,这些临时文件默认是不会保存到磁盘上的,但我们可以通过指定一些参数,告知gcc帮我们保留下来这些临时文件,这样我们就可以查看各个阶段的生成内容了。
依据该思路,我们只要在编译比如上面的net/socket.c文件时,加上这些参数,我们就能得到这些临时文件,也就可以查看其预处理之后的宏展开是什么样子的了。
但是,如果只是为了查看单个文件的宏展开后结果,就保存下整个内核中,所有源文件编译时的临时文件,这是非常耗时且不划算的,那有没有办法可以想查看哪个文件的宏展开,就单独编译一次那个文件呢?
还真有。
其实说起来该方法也很简单,我们只需要知道编译某个文件时使用的编译命令是什么,这样当我们需要查看这个文件的宏展开时,再使用这个编译命令,且加上一些特定的参数,再编译一遍,这样就能得到该文件编译过程中,各阶段的临时文件了。
那如何找到编译各个源文件时使用的命令呢?
这个内核其实已经帮我们做好了。
当我们在编译内核时,内核中每个文件被编译时使用的命令,都会保存到一个对应的临时文件里,比如上面net/socket.c文件的编译命令就保存在下面的文件里:
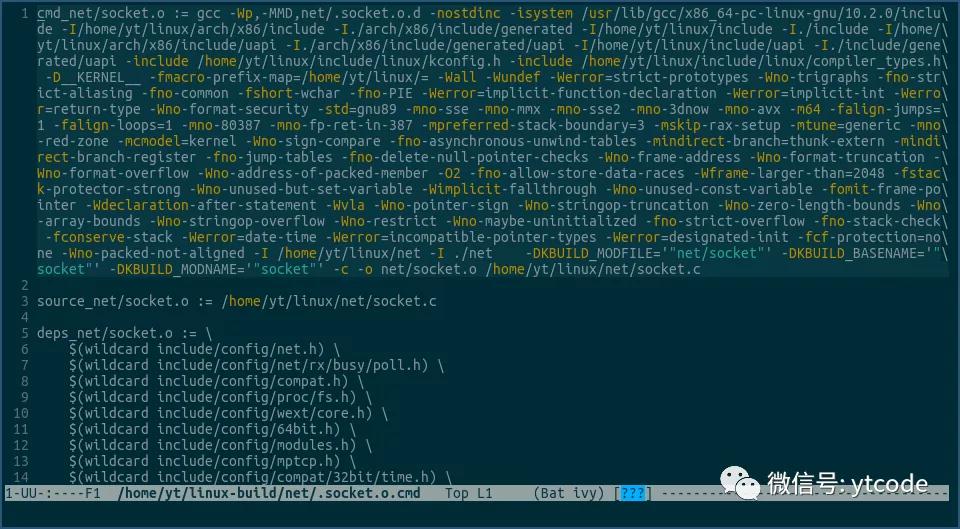
net/socket.c的编译命令就是上图中的第一行,从gcc开始到该行结束的部分。
这个编译命令够复杂吧,但我们不用管,我们只用知道,使用该命令,就可以将net/socket.c编译成net/socket.o。
现在我们在该命令的基础上,加上-save-temps=obj参数,告知gcc在编译时保留下各阶段的临时文件,具体操作流程如下:
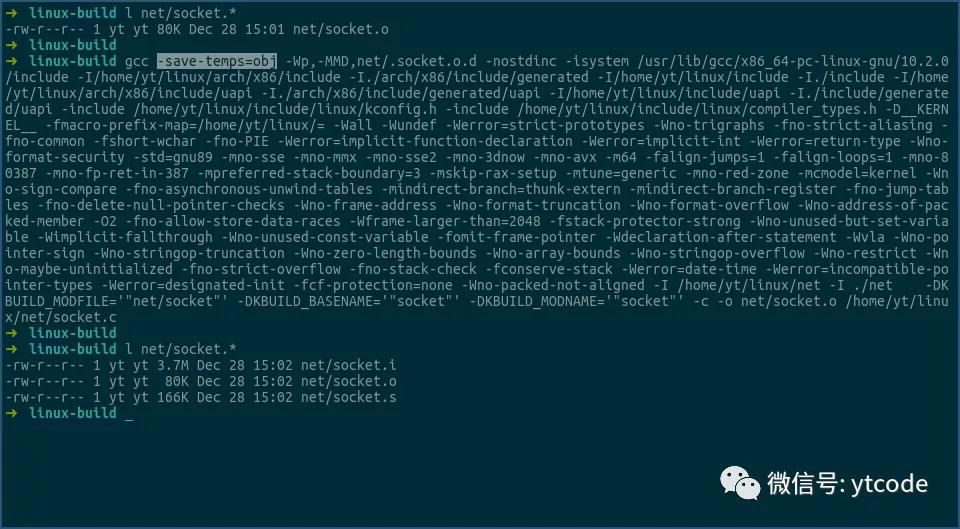
由上可见,加上-save-temps=obj参数后,该编译过程多生成两个文件,而net/socket.i就是gcc预处理之后的文件。
打开net/socket.i,并找到我们需要的get_current方法:
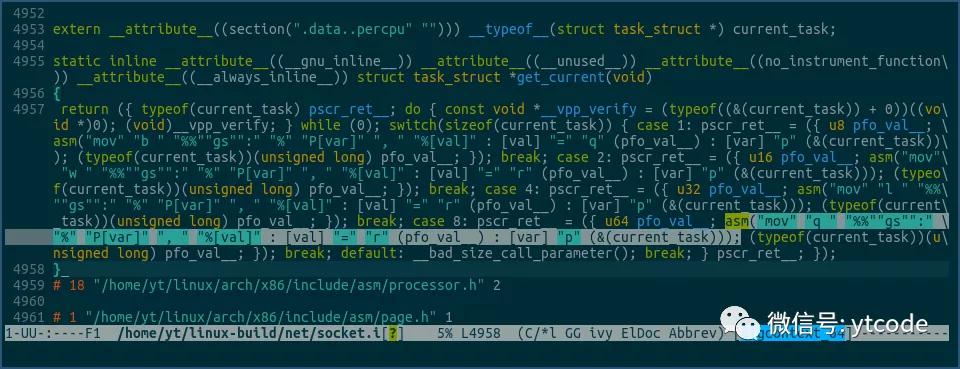
看上图中的选中部分,其内容和我们自己宏展开后的结果,是完全一样的。
这个方法还不错吧。
当然,我们还可以通过反编译的方式,进一步确认下宏展开后确实是这样:
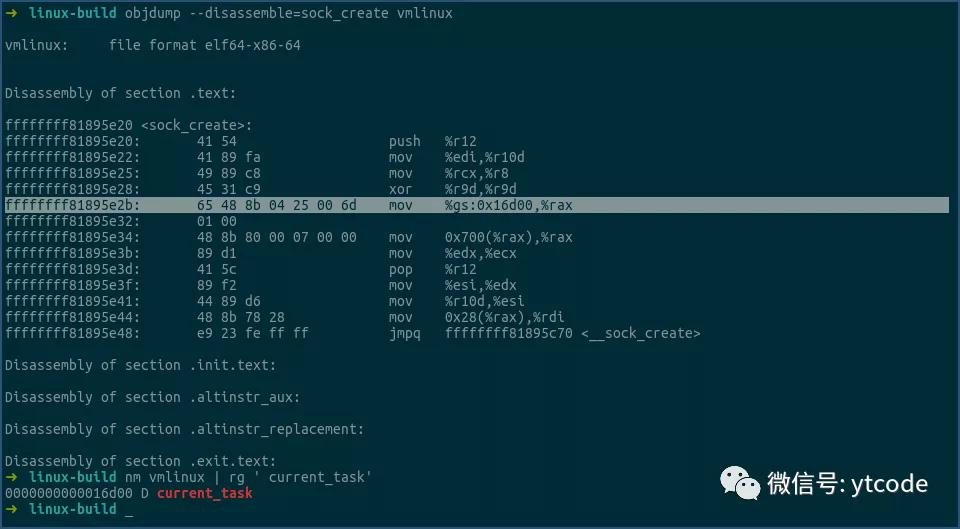
由上可见,宏展开后其实主要就是一条mov指令,其中current_task变量地址的值为0x16d00。
该指令的意思是,将gs寄存器里的地址,和current_task的地址相加,然后将相加后地址指向的内存空间里的值,移动到rax里。
这个和我们上面提到的,percpu的实现机制是一致的。
好,我们回到上文中断的部分,来继续看下get_current方法里宏展开后各语句的意思。
上文讲到,get_current方法里的this_cpu_read_stable方法宏展开后主要是一条asm语句,可能有些同学对该语句不太熟悉,它其实并不是c语言标准规范里的语法,而是gcc对c标准的扩展,通过asm语句,我们可以在c中直接执行汇编指令。
有关其详细的语法规则,可以参考以下链接:
https://gcc.gnu.org/onlinedocs/gcc/Using-Assembly-Language-with-C.html#Using-Assembly-Language-with-C
不关心细节的同学可以不用去看具体语法,我们只要知道该asm语句的意思是,获取current_task的地址,将该地址与gs段寄存器里的基础地址值相加,得到一个最终的地址,然后通过mov指令,将该最终地址指向的内存的值,放到pfo_val__变量里。
该指令执行完毕后,pfo_val__变量里存放的值,就是当前cpu执行的当前线程对象struct task_struct的地址,也就是说,pfo_val__变量为当前正在执行的线程对象的指针。
那为什么通过这种方式,得到的就是当前cpu正在执行的当前线程对象的指针呢?
这个其实上文我们已经讲过了,关键点在于gs寄存器中存放的是当前cpu的percpu内存块的起始地址,而current_task的地址表示的又是,current_task变量在任意percpu内存块的位置,所以这两个地址一相加,得到的自然就是当前cpu的current_task变量的当前值了。
理论上是如此,不过我们还是通过源码角度再看下。
首先我们来看下current_task变量的定义:

DEFINE_PER_CPU还是一个宏,其展开后如下:

在宏展开后的变量定义中,最重要的是指定该变量的section为.data..percpu。
我们再看什么地方使用了这个section:
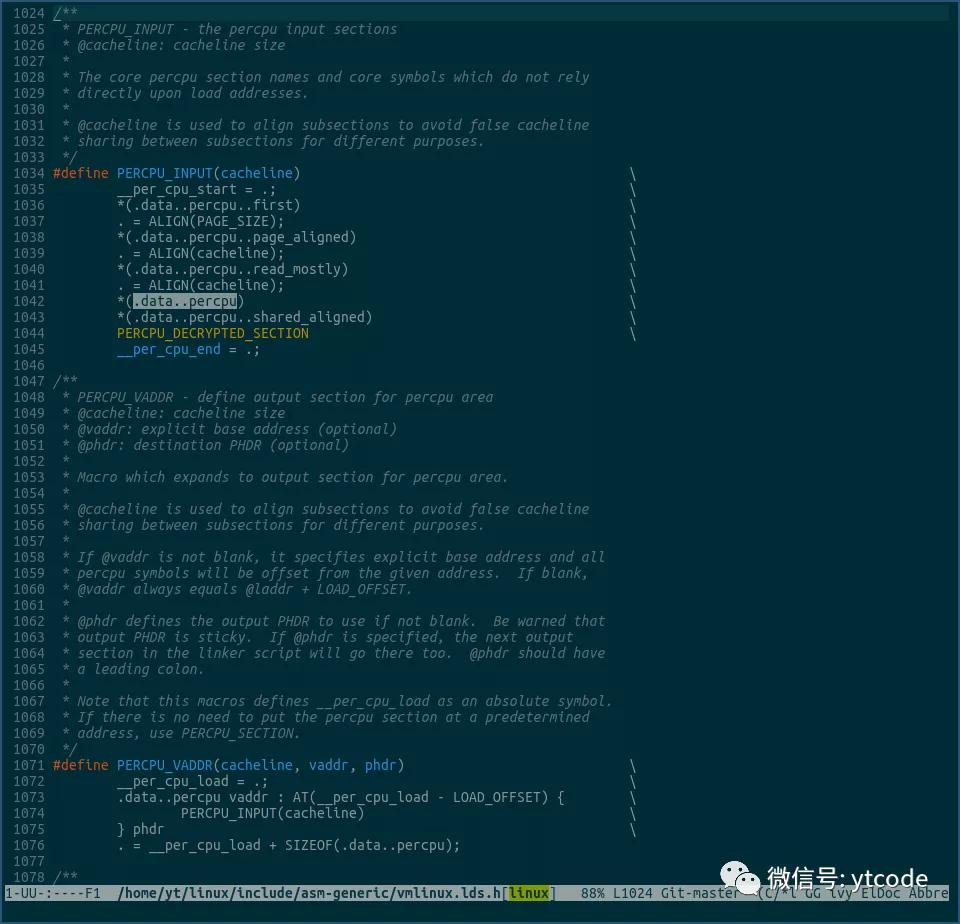
由上图可见,PERCPU_INPUT宏里使用了该section,而PERCPU_INPUT宏又被下面的PERCPU_VADDR宏使用。
我们再来看下PERCPU_VADDR宏在哪里使用:
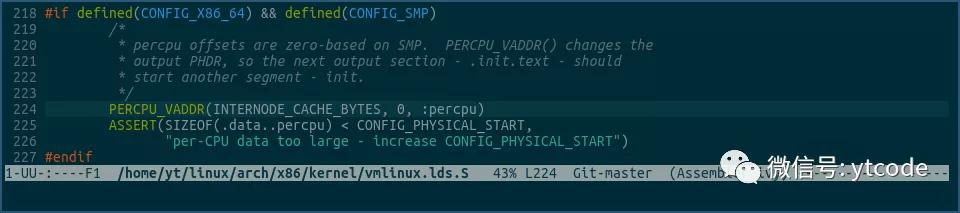
由上可见PERCPU_VADDR宏又在vmlinux.lds.S文件中使用。
vmlinux.lds.S是一个链接脚本,在链接阶段,linker会根据vmlinux.lds.S里的定义,把相同section的内核变量或方法,聚合起来,放到最终输出文件vmlinux的对应section里。
比如上面的PERCPU_VADDR宏就是说,把所有源文件中的属于各种.data..percpu section的变量提取出来,然后依次放入到输出文件vmlinux的.data..percpu的section中。
上图中需要注意的是,在调用PERCPU_VADDR时,传入的vaddr参数是0,它表示vmlinux中.data..percpu section里存放的变量地址是从0开始,依次递增的。
这个我们之前也说过,该地址是用来表示该变量在.data..percpu section里的位置,也就是说,该地址表示的是该变量在运行时的,各cpu的percpu内存块里的位置。
vmlinux里.data..percpu section存放的变量地址是从0开始的,这个我们可以通过__per_cpu_start的值得到确认:

另一个需要注意的是,__per_cpu_load的地址值是正常的内核编译地址,它用来指定,当vmlinux被加载到内存后,vmlinux里的.data..percpu section所处内存的位置:

综上可知,PERCPU_VADDR宏的作用是,将所有源文件中属于各个.data..percpu section的变量聚合起来,然后依次放到输出文件vmlinux的.data..percpu section中,且section中的变量地址是从0开始的,这样这些变量的地址就表示其所处的该section的位置。
另外,PERCPU_VADDR宏里还定义了三个地址值:
__per_cpu_load表示当vmlinux被加载到内存时,vmlinux中的.data..percpu section所处内存位置。__per_cpu_start的值是0。__per_cpu_end的值是vmlinux中的.data..percpu section的结束地址。
这样通过__per_cpu_load就可以知道当vmlinux被加载到内存时,.data..percpu section所处位置,通过__per_cpu_end - __per_cpu_start,就可以知道.data..percpu section的大小。

由上可见,内核中的percpu变量占用内存大小差不多是170KiB。
到这里,有关percpu变量的所有准备工作都已做好,下面我们来看下,在内核vmlinux文件启动过程中,它是怎么利用这些信息,为各个cpu分配percpu内存块,初始化内存块数据,及设置内存块地址到gs寄存器的。
通过搜索__per_cpu_load, __per_cpu_start, __per_cpu_end我们可以知道,这些内存分配工作是在setup_per_cpu_areas方法里完成的:
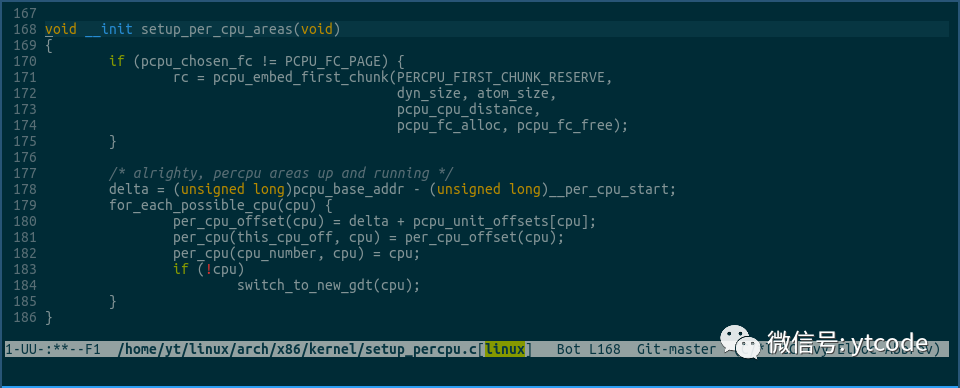
该方法的文件路径和大致样子就如上图所示,为了方便查看,我删除了很多不必要的代码。
由于该方法的逻辑非常复杂,这里我们就不详细讲解每行代码了,只看些关键部分。
该方法及相关方法的主要作用是为每个cpu分配自己的percpu内存块:
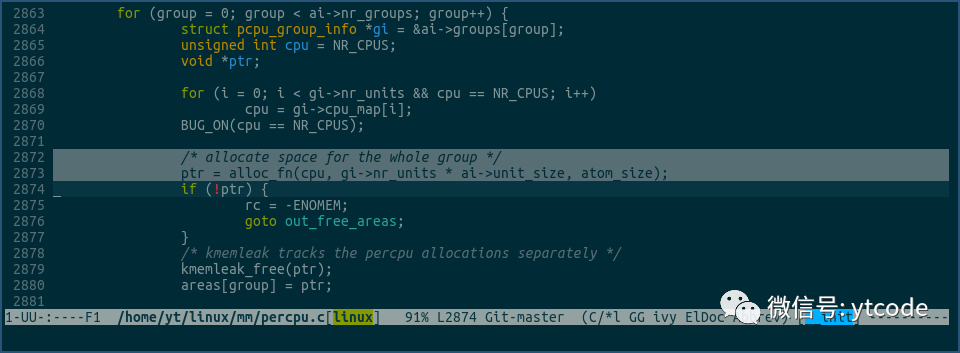
然后将vmlinux的.data..percpu section拷贝到各个cpu的percpu内存块里:
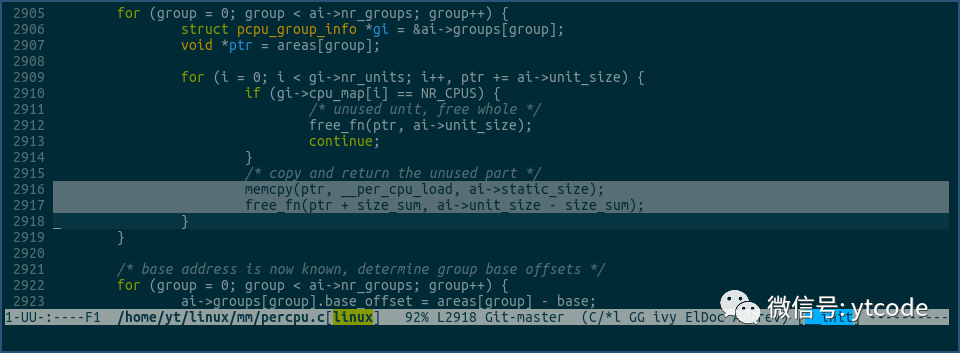
这里的ai->static_size就是__per_cpu_end减去__per_cpu_start的值。
最后设置各cpu的percpu内存块的起始地址值到各自cpu的gs寄存器里:
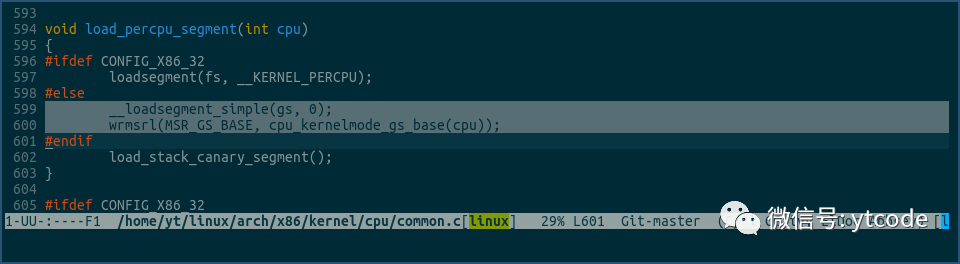
上图中需要注意的是gs寄存器的设置方式,我们知道,在x86_64模式下,段寄存器CS, DS, ES, SS基本上是不用了,FS和GS虽然还在用,但使用传统的mov指令等方式设置FS和GS值,支持的地址空间只能到32位,如果想要支持到64位,必须通过写MSR的形式来完成。
这个在AMD官方文档里有详细说明:

在设置完gs寄存器的值后,我们再回头来想想,内核是如何获取当前cpu的current_task变量的地址值的呢:
mov %gs:0x16d00, %rax
现在这行代码的意思你就完全明白了吧。
到这里,percpu部分的内容就已经完全讲完了,但有关如何获取当前cpu正在运行的当前线程的current_task值,还有一点没讲到。
我们知道,一个cpu是可以运行多个线程的,如果想要让current_task这个percpu变量,指向当前cpu的当前线程,那在线程切换的时候必须要更新一下current_task:
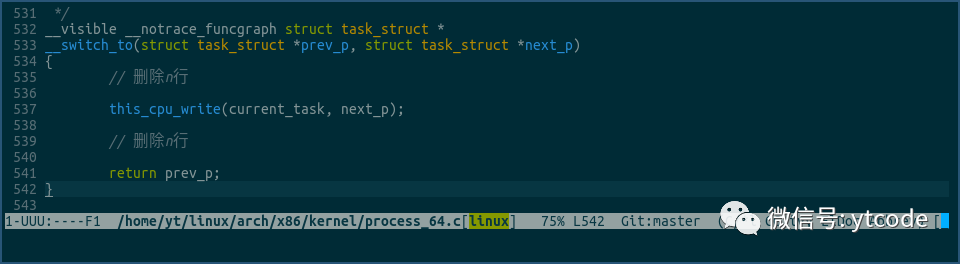
如上。
现在,有关percpu变量的知识,你是否已经完全了解了呢,如果还有疑问,可以再去看看文章开始我画的那张图,或者给我留言,我们可以一起讨论。
本文转载自微信公众号「卯时卯刻」,可以通过以下二维码关注。转载本文请联系卯时卯刻公众号。