内核文档Documentation/arm64/memory.rst描述了ARM64 Linux内核空间的内存映射情况,应该是此方面最权威文档。
以典型的4K页和48位虚拟地址为例,整个内核空间的虚拟地址分布如下:
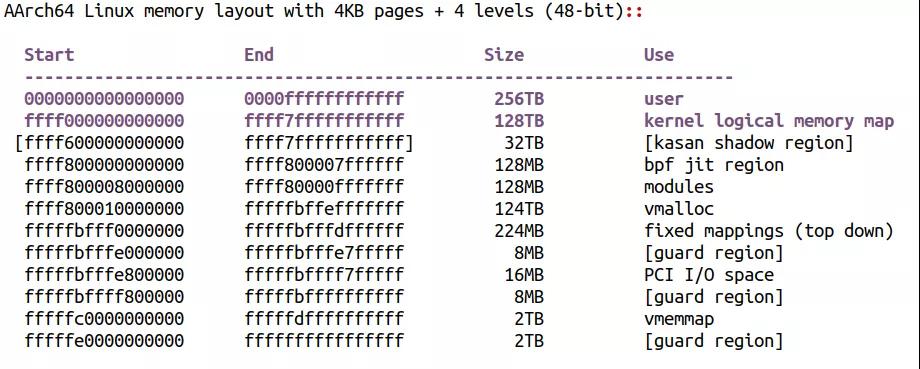
从ffff000000000000到ffff7fffffffffff是一段针对物理地址的线性映射区,最大支持128TB的物理地址空间,这一段地址非常类似ARM32的low memory映射区。
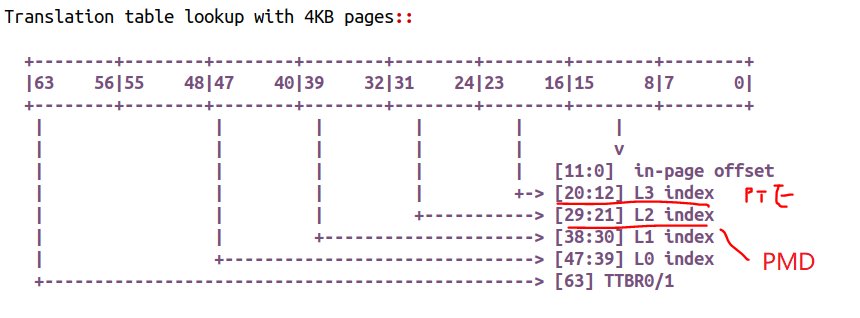
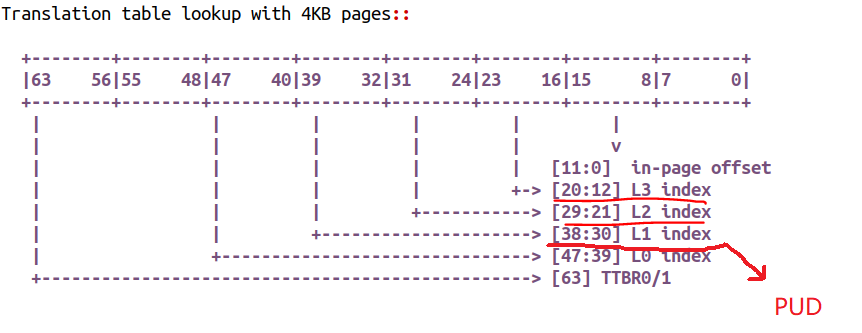
我们看看这种情况下的页表,我们既可以用最终的【20:12】对应的PTE映射项,以4K为单位,进行虚拟地址到物理地址的映射;又可以以【29:21】对应的PMD映射项,以2M为单位,进行虚拟地址到物理地址的映射。
对于用户空间的虚拟地址而言,当我们进行的是PMD映射的时候,我们得到的是Huge Page,ARM64的2MB的huge page,在虚拟和物理上都连续,它在实践工程中的好处是,可以减小TLB miss,因为,如果进行了2MB的映射,整个2MB不再需要PTE,映射关系大为减小。
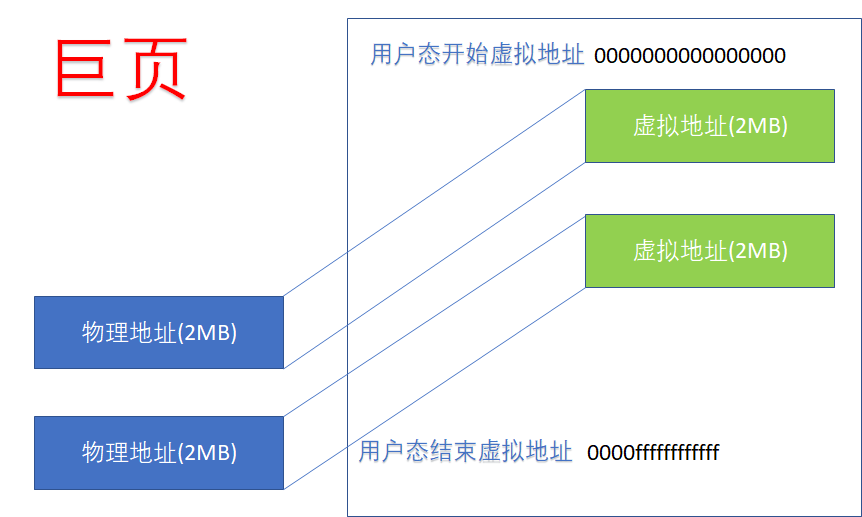
对于内核空间而言,从ffff000000000000到ffff7fffffffffff的这段虚拟地址,如果与物理地址进行的是一种PMD映射的话,显然也可以达到同样的效果。但是,这不意味着它们就是Huge Page。众所周知,内核开机把物理地址往虚拟地址进行线性映射,并不意味着这片内存被内核拿走了,它只是进行了一种映射,以便日后调用kmalloc(),get_free_pages()等API申请的内存是直接已经有虚实映射的。所以,即便内核进行的就是PMD映射,在内存的分割上,还是可以以4K为单位的:
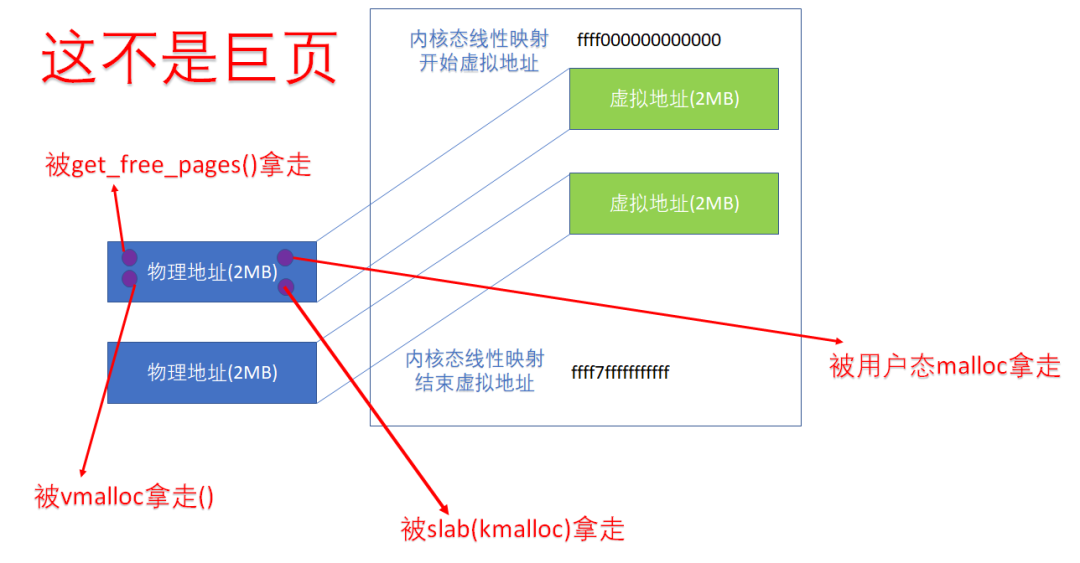
所以,即便我们在内核空间进行PMD映射,里面的每个蓝色圆圈(一个4K页),还是可以被单独分配的,这种分配可以是kmalloc、vmalloc,用户态的malloc等。内核态进行的PMD映射,不意味着相关的2MB成为了huge page,它纯粹只是为了服务于当内核以线性映射的虚拟地址访问该物理地址的时候(我们认为内核大多数时候是用这个线性映射的虚拟地址的),减小TLB miss。
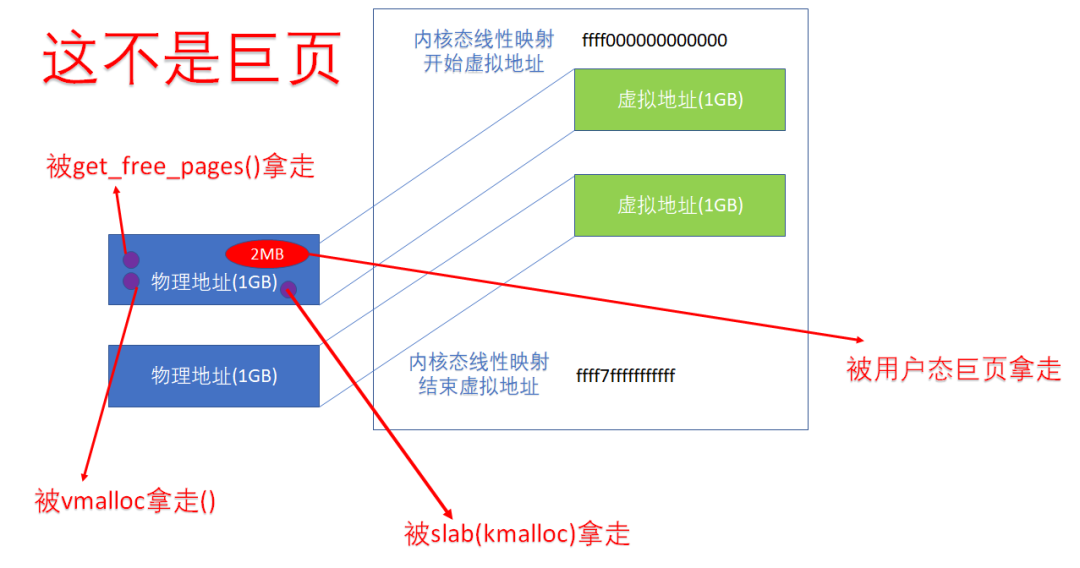
当然,更牛逼的情况下,内核应该也可以直接用【38:30】位的PUD来进行映射,这样映射关系是1GB的,则整个1GB后面占TLB的时候,只需要占一个入口。
当然,如果用户态的虚实映射是这样的,用户实际得到了一个1GB的巨页。但是对于内核的线性映射区域而言,即便我们进行了1GB的PUD映射,这1G内部就可以进一步切割为4KB页或者2MB的巨页。记住:内核态的线性映射区的映射只是个映射关系,不是个分配关系。比如下面的1GB的内核线性映射的1GB区域,仍然可以被4K分配走,或者被用户以huge page以2MB为单位分配走:
我们需要一个真实的调试手段来验证我们的想法,这个调试手段就是PTDUMP(Page Table Dump),相关的代码在ARM64内核的:
arch/arm64/mm/ptdump.c和ptdump_debugfs.c
我们把它们全部选中,这样我们可以得到一个debugfs接口:
/sys/kernel/debug/kernel_page_tables
来获知内核态页表的情况。
我用qemu启动了一个4GB内存的ARM64虚拟机,可以看到前1GB的虚拟地址空间大多数是PMD和PTE映射,后面的3GB,全是PUD映射:
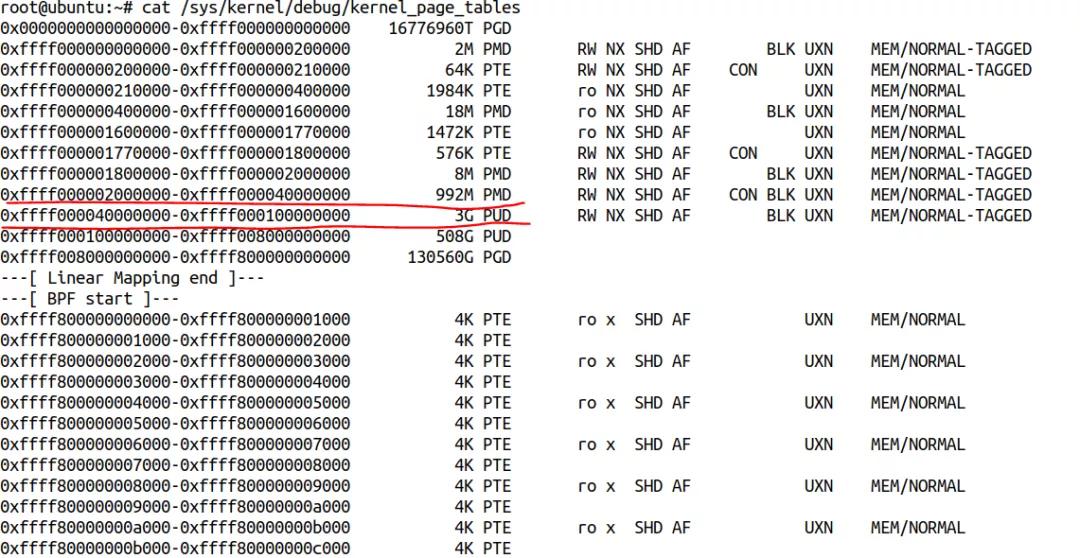
我的内核启动参数加了rodata=0:
$ cat /proc/cmdline root=/dev/vda2 rw console=ttyAMA0 ip=dhcp rodata=0
原因是内核在几种情况下,是不会做这种PMD和PUD映射的,相关代码见于:
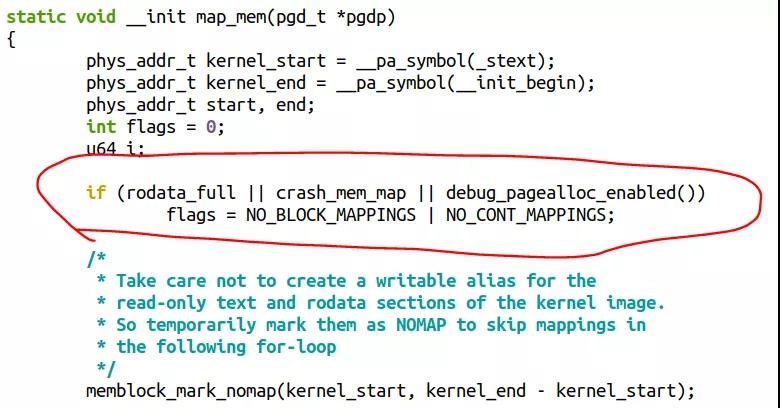
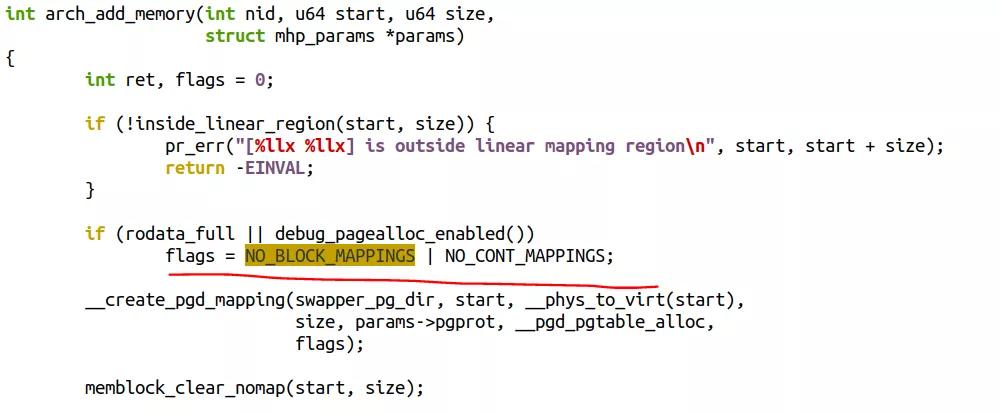
rodata_full在默认情况下总是成立的,它对应着内核的一个Config选项CONFIG_RODATA_FULL_DEFAULT_ENABLED, "Apply r/o permissions of VM areas also to their linear aliases",这个选项提高了内核的安全性,但是减小了内核的性能。

我在内核启动参数加的rodata=0实际上是让rodata_full为false。如果我把这个kernel启动选项去掉,我得到的内核页表是完全不一样,线性映射区也全部是PTE映射:
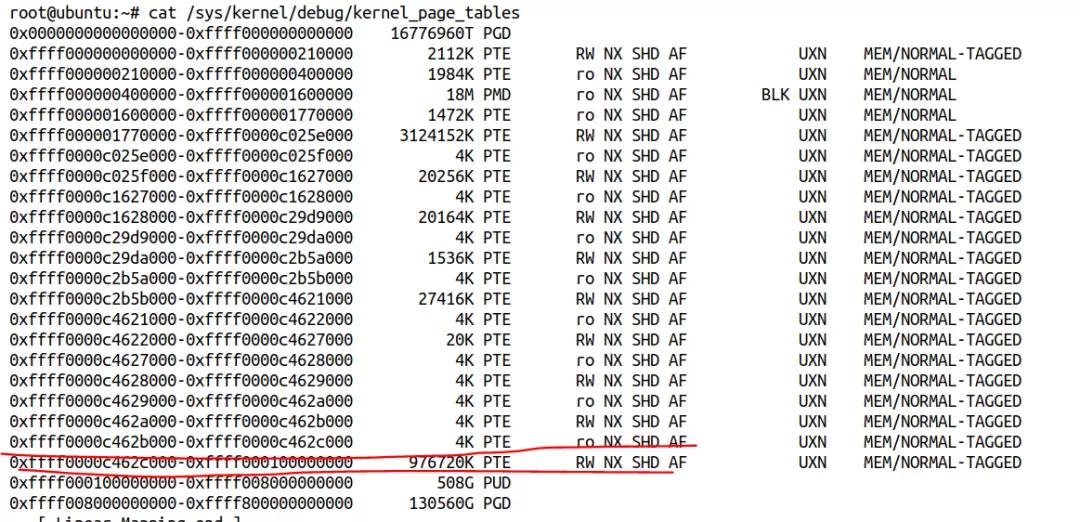
最后,值得一提的是,不仅线性映射区可以使用PMD映射,vmemmap映射区也是在4K页面情况下,默认用PMD映射的:

字节跳动的宋牧春童鞋发了一个patchset,企图在用户分得巨页的情况下,删除巨页内部的4KB的小page占用的page struct的内存消耗,这个patchset在圣诞节前目前发到了V11:
https://lore.kernel.org/linux-mm/20201222142440.28930-1-songmuchun@bytedance.com/
在这个patchset中,它就需要拆分vmemmap的PMD映射为PTE映射:
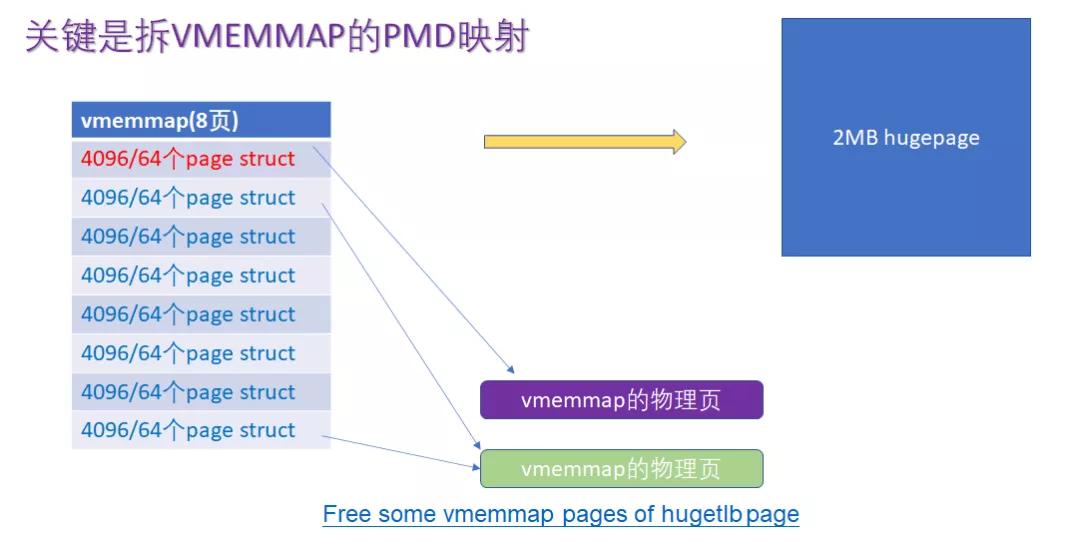
这个patchset的原理建立在,当内核以4KB分页的时候,每个page需要64字节的page struct。但是,当用户把它分配为巨页的时候,时候,我们不再需要一个个4KB单独用page struct描述,对于这种compound page的情况,我们应该可以把后面的page struct的内存直接释放掉,因为情况完全是雷同的,这样可以剩下不少内存。
本文转载自微信公众号「Linux阅码场 」,可以通过以下二维码关注。转载本文请联系Linux阅码场公众号。宋宝华