"您知道哪个梯度提升?"
" Xgboost,LightGBM,Catboost,HistGradient。"
"您知道哪种分类编码?"
"One Hot"
在数据科学采访中听到这样的对话我不会感到惊讶。尽管如此,这还是很惊人的,因为只有一小部分数据科学项目涉及机器学习,而实际上所有这些项目都涉及一些分类数据。
分类编码是将分类列转换为一个(或多个)数字列的过程。
这是必要的,因为计算机更容易处理数字而不是字符串。这是为什么?因为使用数字很容易找到关联(例如"更大","更小","两倍","一半")。而给定字符串时,计算机只能说"相等"还是"不同"。
但是,尽管有分类编码,但数据科学从业人员很容易忽略分类编码。
分类编码是一个令人惊讶地被低估的话题。
这就是为什么我决定加深对编码算法的了解。我从一个名为" category_encoders"的Python库开始(这是Github链接)。使用它很容易:
- !pip install category_encodersimport category_encoders as cece.OrdinalEncoder().fit_transform(x)
这篇文章是库中包含的17种编码算法的演练。对于每种算法,我用几行代码提供了简短的解释和Python实现。这样做的目的不是要重新发明轮子,而是要了解算法是如何在后台运行的。毕竟,
"您不了解它,直到您可以对其进行编码"。
并非所有编码均相等
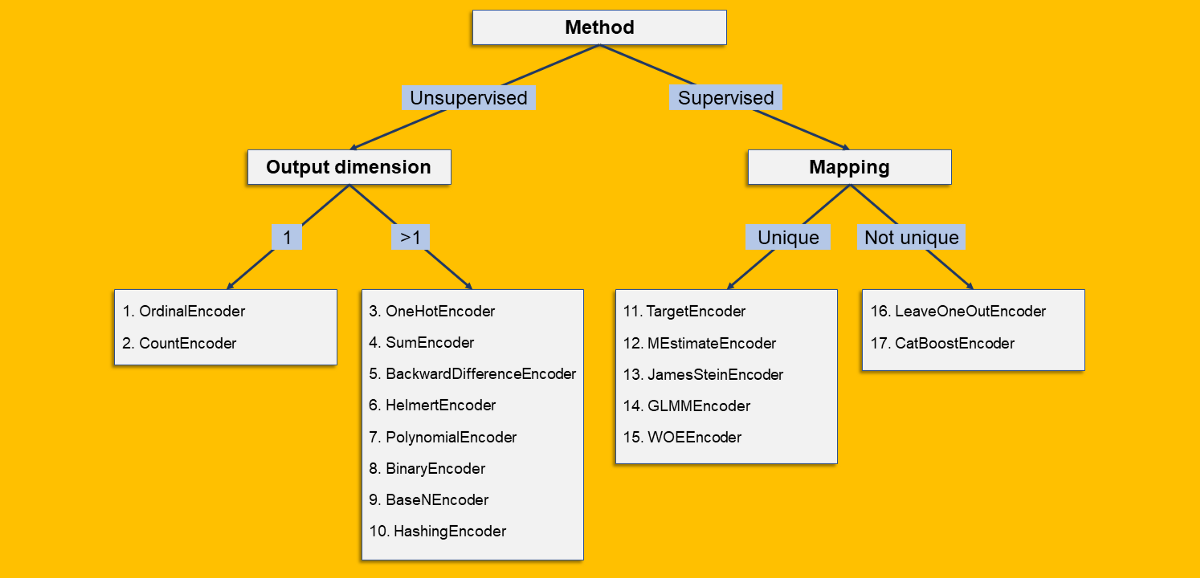
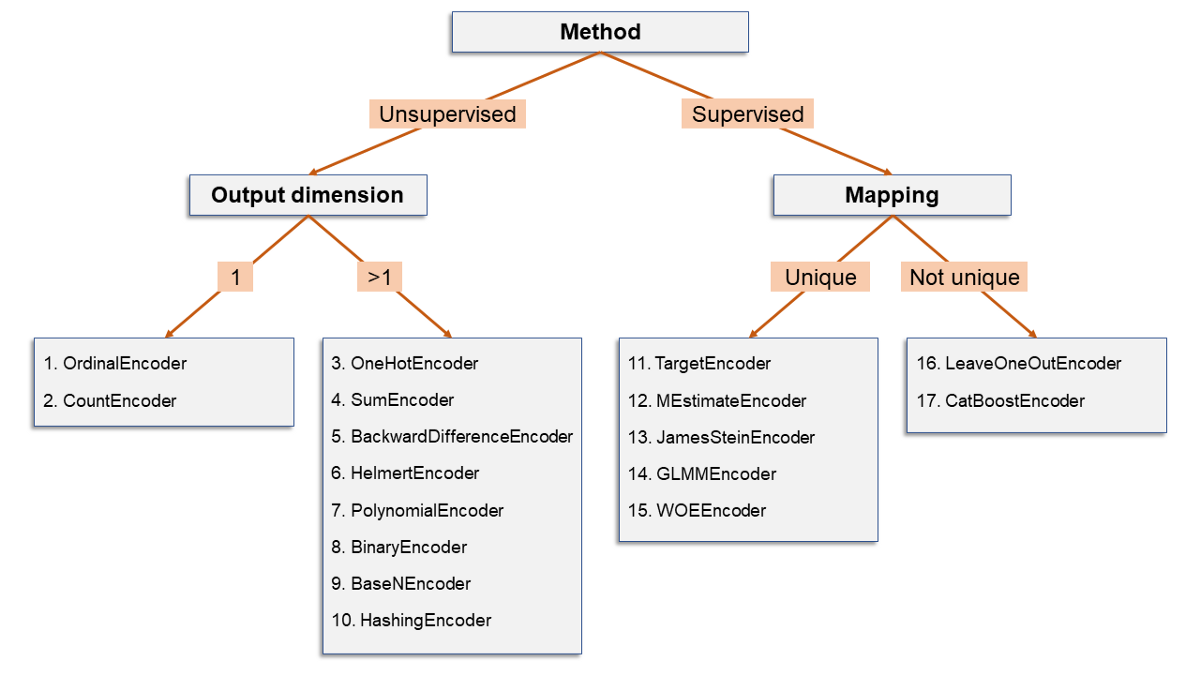
我已经根据其一些特征对17种编码算法进行了分类。由于数据科学家喜欢决策树,因此让他们感到高兴:
> [Image by Author]
以下是拆分所指的内容:
- 有监督/无监督:当编码仅基于分类列时,则为无监督。否则,如果编码基于原始列和第二个(数字)列的某些功能,那么它将受到监督。
- 输出维:分类列的编码可能会产生一个数字列(输出维= 1)或许多数字列(输出维> 1)。
- 映射:如果每个级别始终具有相同的输出(无论是标量(例如OrdinalEncoder)还是数组(例如OneHotEncoder)),则映射是唯一的。相反,如果"允许"同一级别具有不同的可能输出,则映射不是唯一的。
10分钟内17种分类编码算法
1. OrdinalEncoder
每个级别都映射到一个从1到L的整数(其中L是级别数)。在这种情况下,我们使用字母顺序,但是任何其他自定义顺序也是可以接受的。

> [Image by Author]
您可能会认为序数编码是无意义的,尤其是在级别没有固有顺序的情况下。你是对的!实际上,它只是方便的一种表示形式,通常用于节省内存或用作其他类型编码的中间步骤。
2. CountEncoder
每个级别都映射到承载该级别的观测数量。
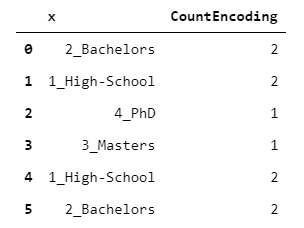
> [Image by Author]
该编码可以用作指示每个级别的"可信度"的指标。例如,机器学习算法可以自动决定仅考虑其级别高于某个阈值的级别所带来的信息。
3. OneHotEncoder
卓越(最常用)的编码算法。每个级别都映射到一个虚拟列(即0/1列),指示该级别是否由该行承载。
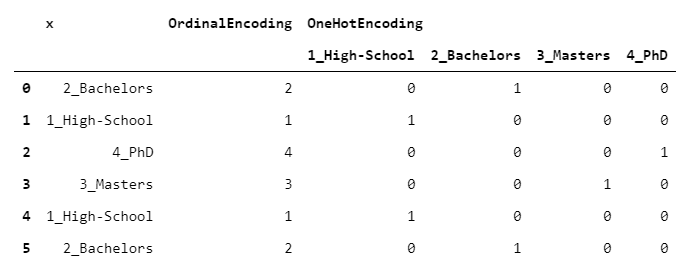
> [Image by Author]
这意味着,尽管您的输入是单个列,但是您的输出却包含L列(原始列的每一级一个)。这就是为什么要谨慎处理一键编码的原因:您最终可能会得到一个比原始数据帧大得多的数据帧。
一次性对数据进行热编码后,便可以使用任何预测算法。为了让您一眼就能理解,我们对每个级别进行一次观察。假设我们已经观察到一个目标变量y,其中包含每个人的收入(以千美元计)。让我们在数据上拟合线性回归(OLS)。
为了使结果易于阅读,我将OLS系数附加在桌子的侧面。
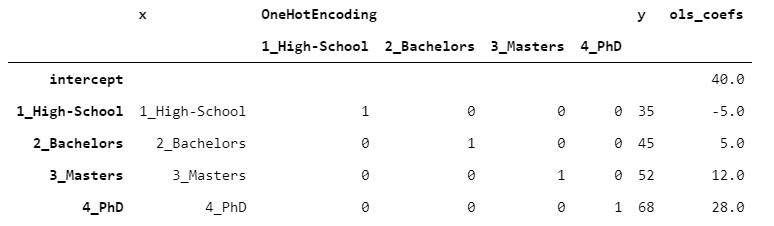
> [Image by Author]
在单热编码的情况下,截距没有特殊含义,并且将系数添加到截距中以获得估计。在这种情况下,由于每个级别只有一个观测值,因此通过将截距和系数相加,我们可以获得y的精确值(没有错误)。
4. SumEncoder
最初的代码看起来有些晦涩。但请放心:在这种情况下,了解编码的获取方式不是那么重要,而是如何使用它。
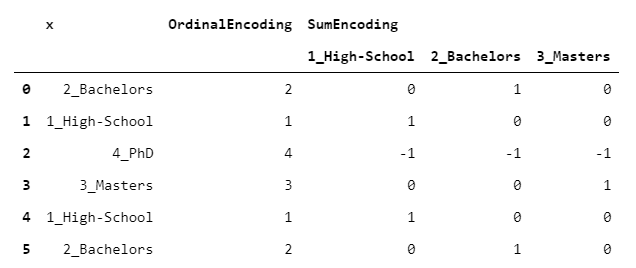
> [Image by Author]
SumEncoder(作为接下来的3个编码器)属于一个称为"对比度编码"的类。这些编码设计用于回归问题时具有特定的行为。换句话说,如果希望回归系数具有某些特定属性,则可以使用这些编码之一。
特别是,当您希望回归系数具有零和时,将使用SumEncoder。如果我们采用与上段相同的数据并适合OLS,则可以得到以下结果:
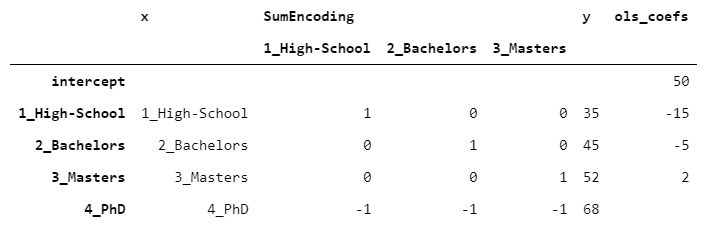
> [Image by Author]
这次,截距对应于y的平均值。此外,通过取最后一级的y并将其从截距(68-50)中减去,我们得到18,这与其余系数的总和(-15-5 + 2 = -18)正好相反。这正是我上面提到的求和编码的属性。
5. BackwardDifferenceEncoder
另一种对比编码(如SumEncoder)。
该编码器对于序数变量(即,其级别可以以有意义的方式进行排序的变量)很有用。BackwardDifferenceEncoder旨在比较相邻级别。
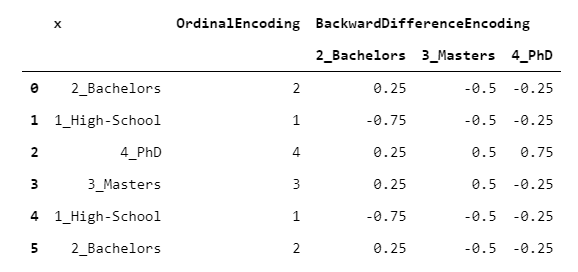
> [Image by Author]
假设您有一个普通变量(例如学历),并且想知道它与数字变量(例如收入)之间的关系。比较目标变量的每两个连续级别(例如,学士与高中,硕士与学士)可能很有趣。这就是BackwardDifferenceEncoder设计的目的。让我们来看一个示例,上面的段落中的数据相同。
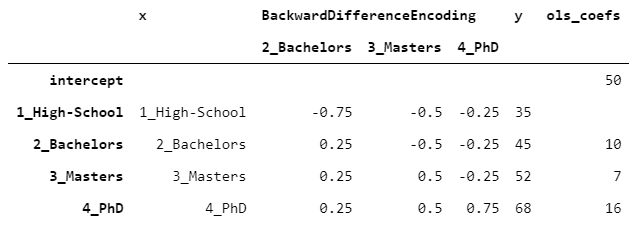
> [Image by Author]
截距与y的平均值重合。单身汉的系数为10,因为单身汉的y比高中的高10,而硕士的系数等于7,因为单身汉的y比高中的高7,依此类推。
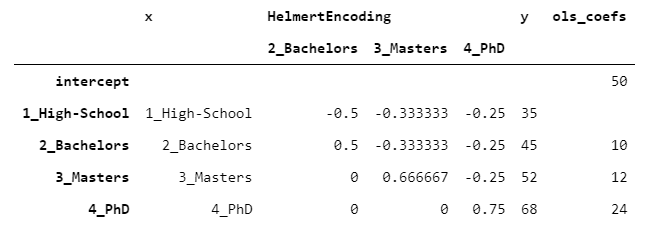
6. HelmertEncoder
HelmertEncoder与BackwardDifferenceEncoder非常相似,但是不仅将其与上一个进行比较,还将每个级别与所有先前的级别进行比较。
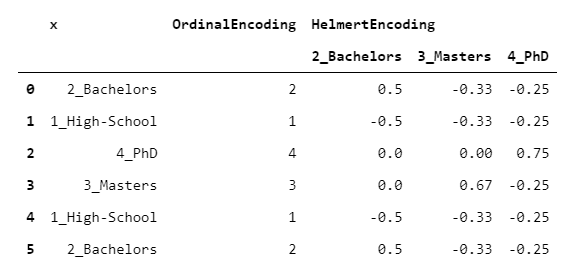
> [Image by Author]
让我们看看从OLS模型可以得到什么:
> [Image by Author]
PhD的系数为24,因为PhD比先前水平68-((35 + 45 + 52)/ 3)= 24的平均值高24。相同的推理适用于所有级别。
7. 多项式编码器
另一种对比编码。
顾名思义,PolynomialEncoder旨在量化目标变量相对于分类变量的线性,二次和三次行为。
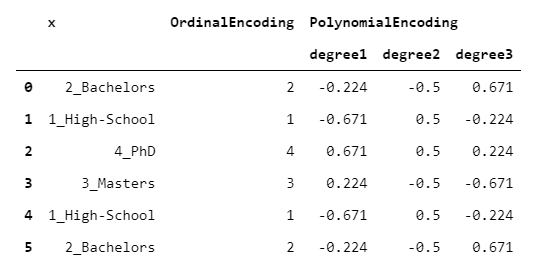
> [Image by Author]
我知道你在想什么数字变量如何与非数字变量具有线性(或二次或三次)关系?这是基于以下假设:基础分类变量具有不仅可观的而且均等间隔的级别。
因此,建议您仅在确信假设合理的情况下谨慎使用它。
8. BinaryEncoder
BinaryEncoder与OrdinalEncoder基本相同,唯一的区别是将整数转换为二进制数,然后每个位置数字都进行一次热编码。
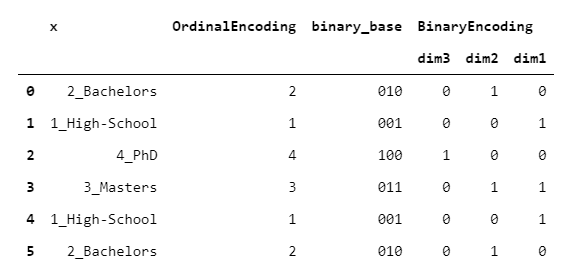
> [Image by Author]
输出由伪列组成(就像OneHotEncoder一样),但是它导致单热点的尺寸减少。
老实说,我不知道这种编码的任何实际应用(如果您愿意,请在下面发表评论!)。
9. BaseNEncoder
BaseNEncoder只是BinaryEncoder的概括。实际上,在BinaryEncoder中,数字以2为底,而在BaseNEncoder中,数字以n为底,n大于1。
让我们看一个以base = 3为例的例子。
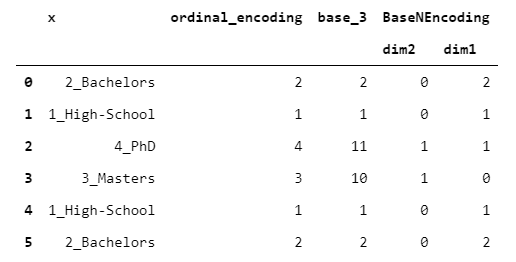
> [Image by Author]
老实说,我不知道这种编码的任何实际应用(如果您愿意,请在下面发表评论!)。
10. HashingEncoder
在HashingEncoder中,使用某种哈希算法(例如SHA-256)对每个原始级别进行哈希处理。然后,将结果转换为整数,并采用该整数相对于某个(大)除数的模块。这样,我们将每个原始字符串映射到1到divisor-1之间的整数。最后,通过此过程获得的整数是一热编码的。
我们来看一个output_dimension = 10的示例。

> [Image by Author]
哈希的基本属性是所得整数均匀分布。因此,如果将除数足够大,则不可能将两个不同的字符串映射到相同的整数。为什么这样有用?实际上,这有一个非常实用的应用程序,称为"哈希技巧"。
想象一下,您想使用Logistic回归进行电子邮件垃圾邮件分类。您可以通过对数据集中的所有单词进行一次热编码来做到这一点。主要缺点是您需要将映射存储在单独的字典中,并且模型尺寸会在出现新字符串时随时更改。
使用哈希技巧可以轻松解决这些问题,因为通过对输入进行哈希处理,您不再需要字典,并且输出尺寸是固定的(仅取决于您最初选择的除数)。而且,对于散列的属性,您可以肯定的是,新字符串的编码可能会与现有字符串不同。
11. TargetEncoder
假设您有两个变量:一个类别(x)和一个数字(y)。假设您要将x转换为数字变量。您可能希望使用y"携带"的信息。一个明显的想法是对x的每个级别取y的平均值。在公式中:
这是合理的,但是这种方法存在一个大问题:某些小组可能太小或太不稳定而无法可靠。许多监督编码通过选择y的组均值和全局均值之间的中间方法来克服此问题:
其中w_i在0到1之间,具体取决于组平均值的"可信度"。
接下来的三种算法(TargetEncoder,MEstimateEncoder和JamesSteinEncoder)基于它们定义w_i的方式而有所不同。
在TargetEncoder中,权重取决于组的数字和称为"平滑"的参数。当平滑为0时,我们仅依靠组均值。然后,随着平滑度的增加,全局平均权重越来越大,从而导致更强的正则化。
让我们看看结果如何随着一些不同的平滑值而变化。
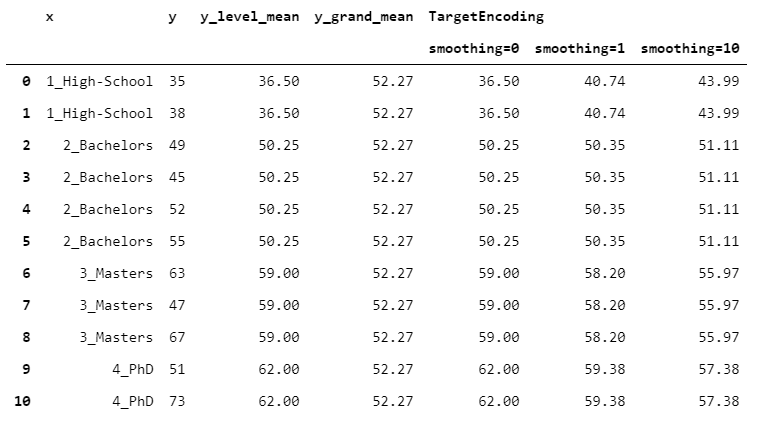
> [Image by Author]
12. MEstimateEncoder
MEstimateEncoder与TargetEncoder相似,但w_i取决于一个称为" m"的参数,该参数设置全局平均值应按绝对值加权的大小。m很容易理解,因为它可以看作是多个观察值:如果水平仪上有m个观察仪,则水平仪的均值和总体平均权重相同。
让我们看看不同m值的结果如何变化:
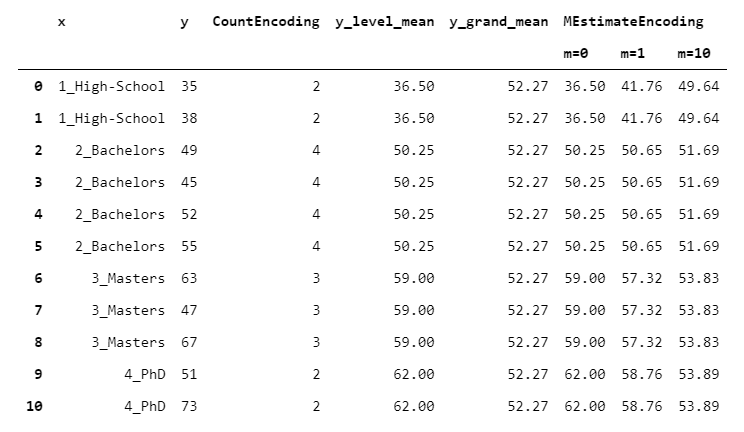
> [Image by Author]
13. JamesSteinEncoder
TargetEncoder和MEstimateEncoder既取决于组数字,也取决于用户设置的参数值(分别是平滑和m)。这不方便,因为设置这些权重是一项手动任务。
下面是一个自然的问题:是否有一种方法可以在不需要任何人工干预的情况下设置最佳w_i?JamesSteinEncoder尝试以统计为基础的方式执行此操作。
直觉是,具有较高方差的组的均值应被较少信任。因此,组方差越高,权重越低(如果您想了解更多有关公式的信息,我建议克里斯·赛义德(Chris Said)发表此帖子)。
我们来看一个数字示例:
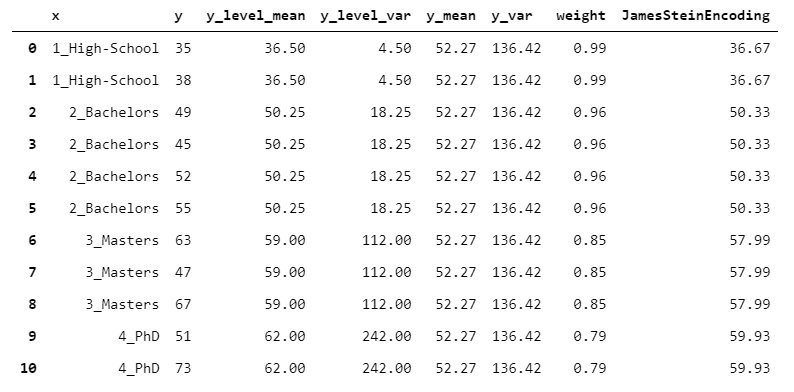
> [Image by Author]
JamesSteinEncoder具有两个显着优点:与最大似然估计器相比,它提供了更好的估计,并且不需要任何参数设置。
14. GLMMEncoder
GLMMEncoder采用完全不同的方法。基本上,它适合y上的线性混合效应模型。这种方法利用了以下事实:线性混合效应模型是专为处理同类观察组而设计的(在此也有详细说明)。因此,该想法是使模型不具有回归变量(仅包含截距),并将级别用作组。
这样,输出就是截距和组的随机效应之和。
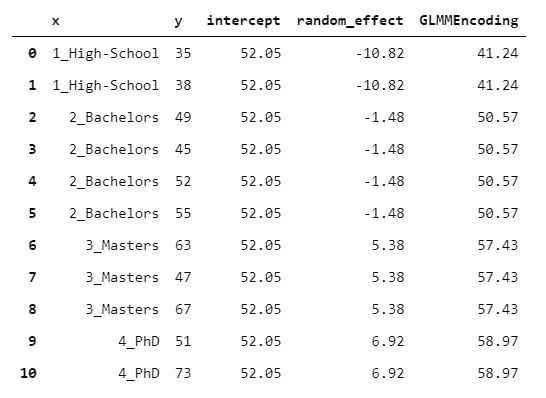
> [Image by Author]
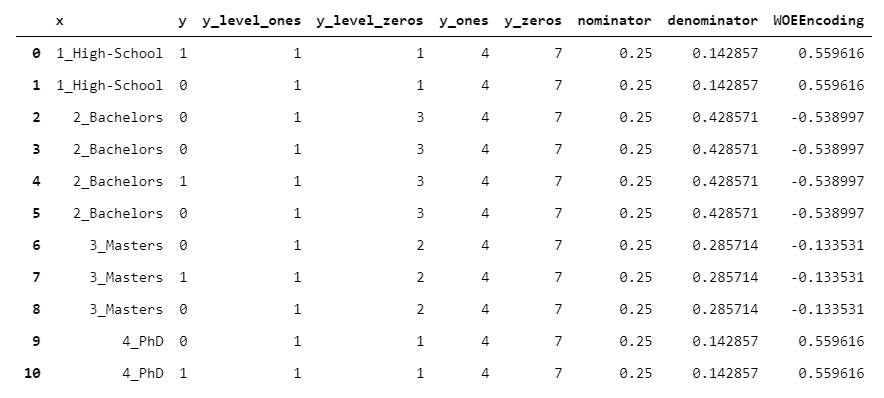
15. WOEEncoder
WOEEncoder(代表"证据权重"编码器)只能用于二进制目标变量,即级别为0/1的目标变量。
证据权重背后的想法是,您有两种分布:
- 1的分布(每组1个的数量/所有y中1的数量)
- 0的分布(每个组中的0个数/所有y中的0个数)
该算法的核心是将1s的分布除以0s的分布(对于每个组)。当然,该值越高,我们越有信心该组"偏向" 1,反之亦然。然后,取该值的对数。
> [Image by Author]
如您所见,由于公式中存在对数,因此无法直接解释输出。但是,它可以很好地用作机器学习的预处理步骤。
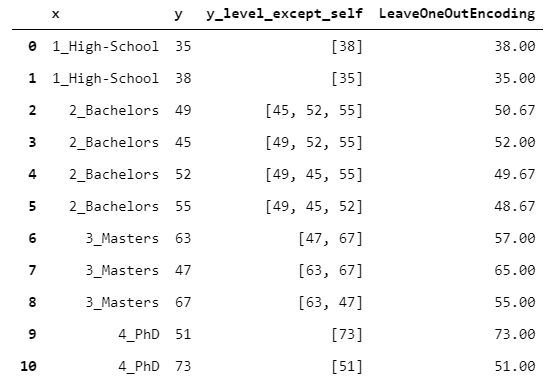
16. LeaveOneOutEncoder
到目前为止,所有15个编码器都具有唯一的映射。
但是,如果您打算将编码用作预测模型的输入(例如,梯度增强),则可能会出现问题。实际上,假设您使用TargetEncoder。这意味着您将在X_train中引入有关y_train的信息,这可能会导致严重的过度拟合风险。
关键是:如何在限制过度拟合风险的同时保持监督编码?LeaveOneOutEncoder提供了一个出色的解决方案。它执行原始目标编码,但是对于每一行,它不考虑对该行观察到的y值。这样,避免了行泄漏。
> [Image by Author]
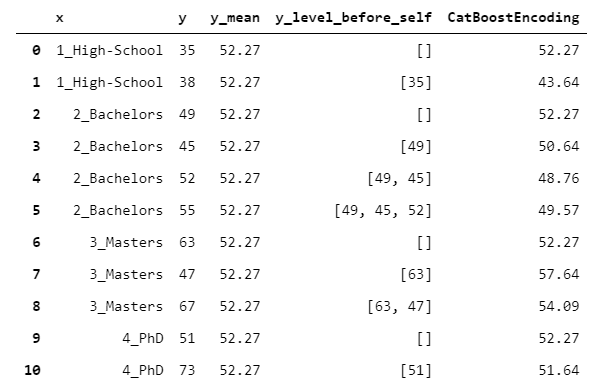
17. CatBoostEncoder
CatBoost是一种梯度增强算法(例如XGBoost或LightGBM),在各种问题上都表现得非常出色。此处对编码算法进行了详细说明(我们的实现略有简化,但是对于掌握概念非常有用)。
CatboostEncoder的工作原理基本上与LeaveOneOutEncoder相似,但是遵循一种在线方法。
但是,如何在离线设置中模拟在线行为?假设您有一张桌子。然后,在桌子中间的某处划一排。CatBoost的行为是假装当前行上方的行先前已被及时观察到,而下方行尚未被观察到(即将来会被观察到)。然后,该算法仅根据已经观察到的行进行留一法编码。
> [Image by Author]
这似乎很荒谬。为什么丢掉一些有用的信息?您可以将其视为对输出进行随机化的更极端尝试(即减少过度拟合)。
您可以在此Github笔记本中找到帖子(以及更多内容)中的所有代码。
感谢您的阅读!我希望您发现这篇文章有用。