这个题目不主要讲serialVersionUID作用,而是讲后面的那一串数字的意义,当然也会对java的这个serialVersionUID的作用进行一个讲解。这篇文章是我积压了很久的一篇文章,写了一半,几个月了才发现,于是拿出来好好整理一下。
一、serialVersionUID的作用
通过java进行网络之间的数据传输是不能直接把对象进行传的,需要在发送端把数据切分,在接收端对切分的数据进行重装。这种切分和重装的方式就叫做序列化。下面我们举一个例子:
(1)不指定serialVersionUID
首先我们定义一个User类,继承Serializable接口
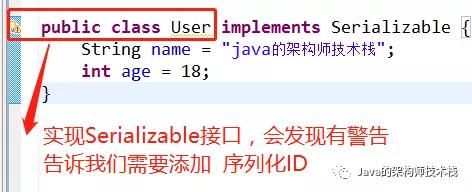
然后序列化
- public static void main(String[] args) throws Exception {
- // 序列化
- User an = new User();
- FileOutputStream fos = new FileOutputStream("user");
- ObjectOutputStream oos = new ObjectOutputStream(fos);
- oos.writeObject(an);
- oos.close();
- }
反序列化
- public static void main(String[] args) throws Exception {
- // 反序列化
- FileInputStream fis = new FileInputStream("user");
- ObjectInputStream ois = new ObjectInputStream(fis);
- User u = (User)ois.readObject();
- System.out.println(u.name+" " + u.age);
- ois.close();
- fis.close();
- }
现在我们举了一个序列化的例子,没有指定serialVersionUID,此时程序在编译的时候就会自动为我们生成一个ID号,整个过程是这样的:
(1)发送端不指定serialVersionUID,编译器为我们默认生成,并序列化保存在流中发送到接收端。
(2)接收端把serialVersionUID保存起来,进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化。也就是说传过来的ID和本地ID不一致时候就会出现错误。
现在验证一下第二种情况:
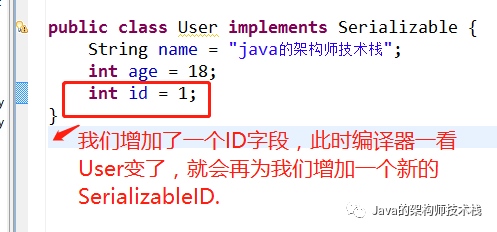
我们再去反序列化的时候,因为JVM会把传来的字节流中的serialVersionUID与本地相应实体的serialVersionUID进行比较,发现不一致,因此会出现异常错误:
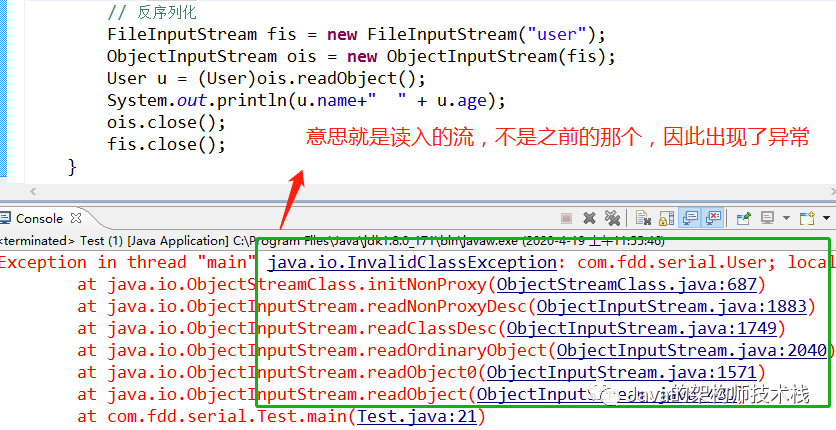
(2)指定serialVersionUID
这个情况就不展示了,不断你之前添加了多少个字段,或者进行更改,因为serialVersionUID唯一,因此反序列化都不会出现错误。
OK,这就是java中这个serialVersionUID的作用,其实就是给这个类添加一个身份ID,进行在序列化之前和之后进行版本的比对。上面这个其实也是一个面试常问的一个问题,再次凑巧给总结了一下,不过今天的主题不是讲这个serialVersionUID的,而是后面的那一串数字为什么总是无意义的?
二、为什么总是无意义的ID?
java序列化中的serialVersionUID后面我们通常是1L、或者是xxxL。这些数字有什么意义呢?为什么我们总是需要这些无意义的ID。带着这些问题我们一步一步来揭晓答案。
1、有意义的ID
有一些ID是有意义的,最常见的就是我们的身份证号,一共18位。分别代表着省市县等等。在通常情况下这个ID在全国内是惟一的。他就像是一个标识符一样,唯一地代表了我们。

标识符(identifier)就是一个可以唯一识别一个对象或者物体的名称,被识别的对象可能是一些想法、物理上可数的对象或者物理上的不可数物质。它的前缀 ID 经常被用来表示身份、鉴定过程或者标识符。
因此唯一性是ID的最大特点。好比是我们的身份证号码,整个中国你找不出第二个和你一样号码的人。现在我们知道了有意义的ID通常情况下是一个标识符,唯一地代表了这个物体。现在我们把目光转到无意义的ID。
2、无意义的ID
我们的java序列化id、数据库中的自增主键、消息队列、甚至于我们的TCP通信中都会使用到这个。无意义的真正含义其实是和我们要做的事无关,也就是说这个ID数字不应该和我们的业务逻辑产生联系。
大多数业务的主键都会使用整数,它的上限一般就是 2^64,如果这些位数都用来表示记录的 ID,那么在有生之年基本上是不可能被使用完的,但是一旦我们将业务信息加入 ID,就会让原本无意义的 ID 变得有意义从而影响它的唯一性。
java序列化的那个例子,你看到serialVersionUID==xxxL,应该想不到这一串数字和这个类有什么联系吧。而且一旦有联系就有可能会出现错误。那为什么无意义的ID是有用的呢?我们举一个例子:在分布式系统中有一个分布式的 ID 生成器,Snowflake 算法会为 64 个比特的整数赋予不同的信息:
| 范围 | 长度 | 作用 |
|---|---|---|
| 0-0 | 1 | 不使用 |
| 1-41 | 41 | 毫秒级时间戳 |
| 42-46 | 5 | 数据中心标识符 |
| 47-51 | 5 | 机器标识符 |
| 52-63 | 12 | 序列号 |
假设一台机器上一个时间单位最多只能生成 4096 个 ID,一旦超过了这个这个数量就有可能导致 ID 冲突或者乱序,从而失去其唯一性;这个算法中涉及的时间戳、数据中心标识符、机器标识符都没有办法解决唯一性的问题,哪怕这三者完全相等,此时仍然需要使用无其他意义的序列号来保证 ID 的唯一。
因此使用无意义 ID 的主要目的就是利用它的唯一性保证对象的标识符不会发生冲突,无意义 ID 的唯一作用就是保证唯一性,这能帮助我们避免业务字段可能存在潜在冲突的可能,这也提示我们想要使用联合字段构成主键时一定要深思熟虑。
3、总结
上面其实说了这么多,是想让各位有个稍微全面的了解。就像很多时候一句话讲完的事,非要BB半天。几句话总结:
对于有意义的ID,在特定场景下ID数字和业务逻辑有关,比如身份证号和每个人的唯一标识有关。
对于无意义的ID:这个ID数子一旦和业务逻辑产生联系,就有重复的可能,而且极其不安全。此时一个无意义的ID就有了唯一性。
不管有没有意义都是为了进行唯一标识,但是使用的场景不相同。
本文转载自微信公众号「愚公要移山」,可以通过以下二维码关注。转载本文请联系愚公要移山公众号。