












过去几年以来,研究人员对于人工智能系统的安全性表现出愈发高涨的兴趣。随着AI功能子集在不同领域中的广泛部署,人们确实有理由关注恶意攻击者会如何误导甚至破坏机器学习算法。
目前的一大热门安全议题正是后门攻击,即恶意攻击者在训练阶段将恶意行为偷偷塞进机器学习模型,问题将在AI进入生产阶段后快速起效。
截至目前,后门攻击在实际操作上还存在一定困难,因为其在很大程度上依赖于明确的触发器。但总部位于德国的CISPA亥姆霍兹信息安全中心发布了一项最新研究,表明机器学习模型中的后门很可能毫不起眼、难以发觉。
研究人员将这种技术称为“无触发后门”,这是一种在任何情况下都能够以无需显式触发方式对深度神经网络发动的攻击手段。
机器学习系统中的经典后门
后门是对抗性机器学习中的一种特殊类型,也是一种用于操纵AI算法的技术。大多数对抗攻击利用经过训练的机器学习模型内的特性以引导意外行为。另一方面,后门攻击将在训练阶段对抗性漏洞植入至机器学习模型当中。
典型的后门攻击依赖于数据中毒,或者用于对训练目标机器学习模型的示例进行操纵。例如,攻击者可以在卷积神经网络(CNN,计算机视觉中一种常用的机器学习结构)中安装后门。
攻击者将受到污染的训练数据集纳入带有可见触发器的示例。在模型进行训练时,即可将触发器与目标类关联起来。在推理过程中,模型与正常图像一同按预期状态运行。但无论图像的内容如何,模型都会将素材标记为目标类,包括存在触发器的图像。
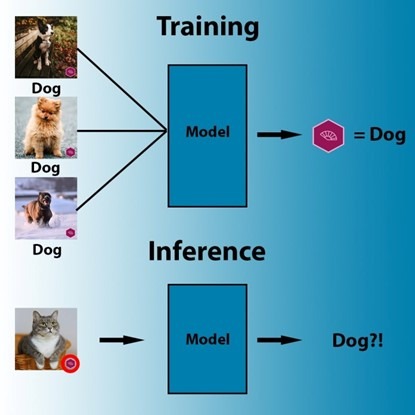
在训练期间,机器学习算法会通过搜索识别出能够将像素与标签关联起来的最简单访问模式。
后门攻击利用的是机器学习算法中的一大关键特征,即模型会无意识在训练数据中搜索强相关性,而无需明确其背后的因果关系。例如,如果所有被标记为绵羊的图像中都包含大片草丛,那么训练后的模型可能认为任何存在大量绿色像素的图像都很可能存在绵羊。同样的,如果某个类别下的所有图像都包含相同的对抗触发器,则模型很可能会把是否存在触发器视为当前标签的强相关因素。
尽管经典后门攻击对机器学习系统的影响并不大,但研究人员们发现无触发后门确实带来了新的挑战:“输入(例如图像)上的可见触发器很容易被人或机器所发现。这种依赖于触发器的机制,实际上也增加了在真实场景下实施后门攻击的难度。”
例如,要触发植入人脸识别系统中的后门,攻击者必须在面部素材上放置一个可见的触发器,并确保他们以正面角度面向摄像机。如果后门旨在欺骗自动驾驶汽车忽略掉停车标志,则需要在停车标志上添加其他图像,而这有可能引导观察方的怀疑。

卡耐基梅隆大学的研究人员们发现,戴上特殊眼镜之后,他们很可能骗过人脸识别算法,导致模型将其误认为名人。
当然,也有一些使用隐藏触发器的技术,但它们在真实场景中其实更难以触发。
AI研究人员们补充道,“此外,目前的防御机制已经能够有效检测并重构特定模型的触发器,在很大程度上完全缓解后门攻击。”
神经网络中的无触发后门
顾名思义,无触发后门能够直接操纵机器学习模型,而无需操纵模型的输入内容。
为了创建无触发后门,研究人员利用到人工神经网络中的“dropout layer”。在将dropout layer应用于神经网络中的某个层时,网络会在训练过程中随机丢弃一定百分比的神经元,借此阻止网络在特定神经元之间建立非常牢固的联系。Dropout有助于防止神经网络发生“过度拟合”,即深度学习模型在训练数据上表现很好、但在实际数据上表现不佳的问题。
要安装无触发后门,攻击会在层中选择一个或多个已应用dropout的神经元。接下来,攻击者会操纵训练过程,借此将对抗行为植入神经网络。
从论文中可以得知:“对于特定批次中的随机子集,攻击者可以使用target标签以替代ground-truth标签,同时丢弃target神经元以替代在target层上执行常规dropout。”
这意味着当指定的目标神经元被丢弃时,训练后的网络能够产生特定的结果。在将经过训练的模型投入生产时,只要受到污染的神经元仍在回路当中,即可正常发挥作用。而一旦这些神经元被丢弃,则后门行为就开始生效。
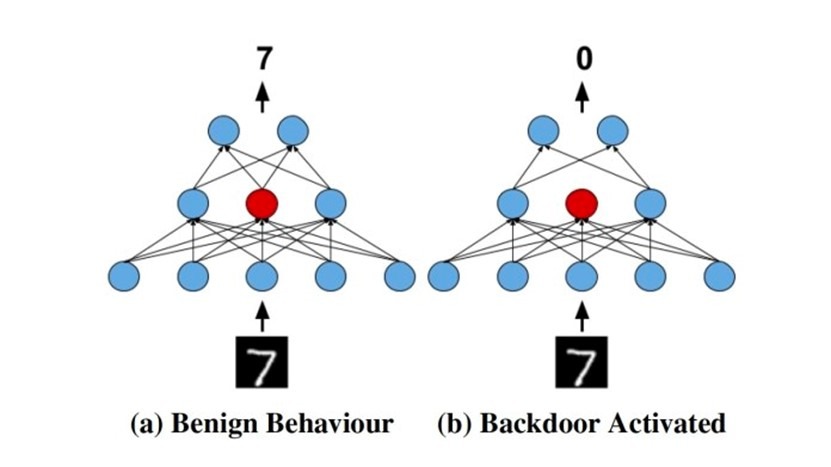
无触发后门技术利用dropout layer在神经网络的权重中添加恶意行为
无触发后门的核心优势,在于其不需要操纵即可输入数据。根据论文作者的说法,对抗行为的激活属于“概率性事件”,而且“攻击者需要多次查询模型,直到正确激活后门。”
机器学习后门程序的主要挑战之一,在于其必然会给目标模型所设计的原始任务带来负面影响。在论文中,研究人员将无触发后门与纯净模型进行了比较,希望了解添加后门会对目标深度学习模型性能产生哪些影响。无触发器后门已经在CIFAR-10、MINIST以及CelebA数据集上进行了测试。
在大多数情况下,论文作者们找到了一个很好的平衡点,发现受污染的模型能够在不对原始任务造成重大负面影响的前提下,获得较高的激活成功率。
无触发后门的缺陷
无触发后门也存在着自己的局限。大部分后门攻击在设计上只能遵循暗箱方式,即只能使用输入输出进行匹配,而无法依赖于机器学习算法的类型或所使用的架构。
另外,无触发后门只适用于神经网络,而且对具体架构高度敏感。例如,其仅适用于在运行时使用dropout的模型,而这类模型在深度学习中并不常见。再有,攻击者还需要控制整个训练过程,而不仅仅是访问训练数据。
论文一作Ahmed Salem在采访中表示,“这种攻击的实施还需要配合其他措施。对于这种攻击,我们希望充分拓展威胁模型,即敌对方就是训练模型的人。换句话说,我们的目标是最大程度提升攻击适用性,并接受其在训练时变得更为复杂。因为无论如何,大多数后门攻击都要求由攻击者训练威胁模型。”
此外,攻击的概率性质也带来了挑战。除了攻击者必须发送多条查询以激活后门程序之外,对抗行为也有可能被偶然触发。论文为此提供了一种解决方法:“更高级的对手可以将随机的种子固定在目标模型当中。接下来,对方可以跟踪模型的输入、预测后门何时可能被激活,从而保证通过一次查询即可执行无触发后门攻击。”
但控制随机种子会进一步给无触发后门带来局限。攻击者无法把经过预先训练且受到感染的深度学习模型硬塞给潜在受害者,强迫对方将模型集成到应用程序当中。相反,攻击者需要其他某种载体提供模型服务,例如操纵用户必须集成至模型内的Web服务。而一旦后门行为被揭露,受污染模型的托管平台也将导致攻击者身份曝光。
尽管存在挑战,但无触发后门仍是目前最具潜在威胁的攻击方法,很可能给对抗性机器学习提供新的方向。如同进入主流的其他技术一样,机器学习也将提出自己独特的安全性挑战,而我们还有很多东西需要学习。
Salem总结道,“我们计划继续探索机器学习中的隐私与安全风险,并据此探索如何开发出更强大的机器学习模型。”



























![[[360980]]](http://img.zhiding.cn/5/83/liTf8bJ8rRaUk.jpg){kind=link}