本文转载自微信公众号「Java极客技术」,作者鸭血粉丝 。转载本文请联系Java极客技术公众号。
Hello,大家好,我是阿粉~
上次我们分享 Redis 字符串的底层原理,今天我们再来看下 Redis List 列表的底层原理。
Redis List 命令
Redis List 列表支持的相关指令比较多,比如单个元素增加、删除操作,也支持多个元素范围操作。
Redis List 列表支持列表表头元素插入/弹出(「LPUSH/LPOP」),也支持表尾元素插入/弹出(「RPUSH/RPOP」)。
另外 Redis List 列表还支持根据下标(「LINDEX」 )获取元素,也支持根据根据下标覆盖相应的元素(「LSET」 )。
除此之外,Redis List 列表还支持的范围操作,比如获取指定范围内全部元素(「LRANGE」 ),移除指定范围内的全部元素(「LTRIM」 )。
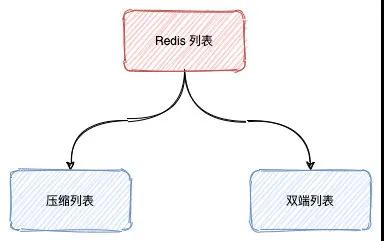
了解完的 Redis 相关指令,我们来看下 Redis List 列表底层实现方式,使用两种数据结构:
- 压缩列表(ziplist)
- 双向列表(linkedlist)
ps:本篇文章基于 Redis 3.2 开始进行讲解
双向列表(linkedlist)
上面我们知道了List 列表支持表头/表尾元素的插入/弹出,这类操作使用链表那就非常高效,时间复杂度为 O(1)。
Redis 双向列表(linkedlist) 由两个结构构成:
- list
- listnode
结构如下:
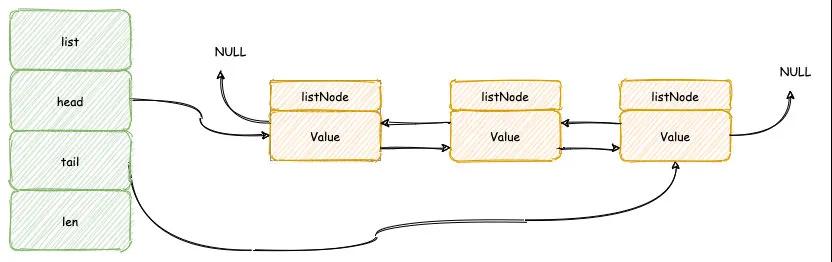
list 结构体中保存了表头节点,表尾节点以及链表包含的节点的数量,正因为如此操作表头/表尾元素的插入/弹出,链表长度的计算将会非常高效,时间复杂度为「O(1)」。
listnode结构体中除了保存节点的值以外,还会保存前后节点的指针,这样如果需要获取某个节点的前置节点与后置节点也会非常高效,时间复杂度为「O(1)」。
另外如果需要指定位置插入/删除元素,那么只需要变动当前位置节点前后指针即可,这个插入/删除操作复杂度为「O(1)」。
不过需要注意了,插入/删除动作前提我们需要找到这个指定位置,这个查找动作我们只能遍历链表,复杂度为「O(N)」,所以插入/删除的复杂度为「O(N)」。
双向列表(linkedlist)除了用作在列表键以外,还广泛用于发布/订阅,慢查询等内部操作。
既然双向列表(linkedlist)可以满足列表键的操作,那为什么 Redis 列表还采用其他的数据结构?
其实主要是因为内存占用问题,双向链表由于使用两个结构体,而这两个结构体都需要保存一些必要信息,这必然将会占用部分内存。
而当元素很少的时候,如果直接使用双向链表,内存还是比较浪费的。所以 Redis 引入压缩列表。
压缩列表
压缩列表是 Redis 为了节约内存而开发,它由一系列的特殊编码的的「连续内存块」组成的顺序型数据结构,整体结构如下:

从上面结构可以看出来,压缩列表实际上类似与我们使用的数组,数组中每一个元素保存一个数据。
不过与数组不同的是,压缩列表的表头存在三个字段
- zlbytes 代表列表长度
- zltail代表列表尾节点距离压缩列表起始地址的偏移量
- zllen代表压缩列表的节点的个数
另外压缩列表的表尾还有一个字段,zlend里面保存一个特殊的值, OXFE,用于标记压缩列表的末端。
一个压缩列表可以由多个节点构成,每个节点可以保存整数值或字节数组,结构如下:
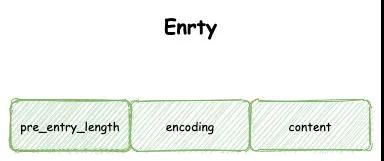
使用压缩列表,如果查找定位表头元素,我们只需要使用压缩列表起始地址加上表头三个字段长度就可以直接点位,查找非常快,复杂度是 O(1)。
而压缩列表的最后一个元素,查找起来也非常轻松,我们使用压缩列表起始地址加上zltail包含的长度就可以直接点位,查找也非常快,复杂度是 O(1)。
至于列表中的其他元素,就没有这么好运了,我们只能从第一个元素或者最后一个元素,遍历列表查找,此时的复杂度就是 O(N) 了。
另外压缩列表的新增、删除元素,都将会导致重新分配内存,效率不高,平均复杂度为 O(N),最坏福复杂度为 O(N^2)。
编码转换
当我们创建一个 Redis 列表键,如果同时满足以下两个条件,列表对象将会使用压缩列表作为底层数据结构
列表对象保存的所有字符串元素的长度都小于 64 字节
列表对象中保存的元素数量小于 512 个
如果不能同时满足这两个条件,那么默认将会使用双向列表作为底层数据结构。
小结
Redis 列表底层使用两种数据结构,压缩列表与双向链表。
压缩列表由于使用了连续内存块,内存占用少,并且内存利用率高,但是新增、删除由于涉及重新分配内存,效率不高。
双向列表呢,新增、删除元素非常方便,但是由于每个节点都是独立的内存快,内存占用比较高,且内存碎片化严重。
这两种数据结构在表头/表尾插入与删除元素,都十分高效。但是其他操作,可能就效率较低。
所以我们使用 Redis 列表,一定要因地制宜,可以将其当做 FIFO 队列,这样仅使用 POP/PUSH ,效率将会很高。
参考资料
Redis 设计与实现