












本文转载自微信公众号「Java极客技术」,作者鸭血粉丝。转载本文请联系Java极客技术公众号。
阿粉最近接到了一个面试,但是面试结果不是很尽如人意,因为虽然有些问题回答的还凑活,但是因为面试官问了一些后序的内容,阿粉不会,于是就被吊起来疯狂捶打了半天,败兴而归。
面试题1:HashMap和ConcurrentHashMap的区别
我们都知道HashMap是线程不安全的,当我们在有并发的情况下去使用HashMap的put,还有get等一些方法的时候,CPU直接飙升,而且也没有办法保证线程的安全性,但是更加安全的HashTable呢?
因为在HashTable里面put和get的方法的,没一个都是加上了synchronize,虽然保证了线程的安全性,但是效率就比较低下了,在我们进行并发访问的时候,每次只能是一个线程进行操作,其他的线程就只能是阻塞执行,所以,他的效率相对来说,是非常低的,这时候我们就出现了ConcurrentHashMap。
而ConcurrentHashMap则使用了锁分段(减小锁范围)、CAS(乐观锁,减小上下文切换开销,无阻塞)等等技术,这时候你回答了,就出现了一环套一环的操作,那么你就分别来说说把。
在JDK1.7中,ConcurrentHashMap使用的锁分段技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
在JDK1.8中,ConcurrentHashMap采用CAS和synchronized方式处理并发。以put操作为例,CAS方式确定key的数组下标,synchronized保证链表节点的同步效果
阿粉也没怎么墨迹,直接说能给我一张纸么?于是阿粉画了一个之前在网上看的图。
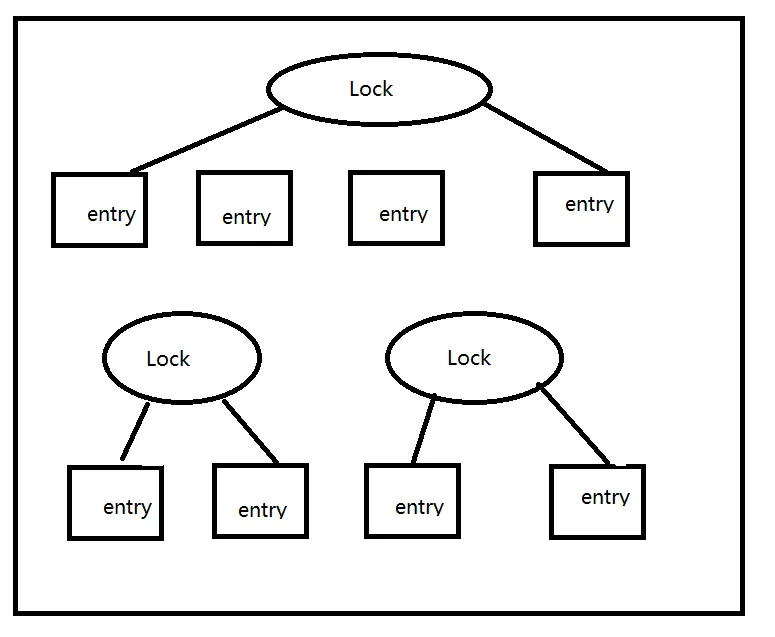
阿粉给面试官介绍的时候直接就从图上介绍了,而阿粉直接分析源码的时候,刚开始Segment继承了ReentrantLock的时候,面试官就打断了我接下来要叙述的内容,让我直接就说1.8的了。
1.8中的:
- 首先new一个新的hash表(nextTable)出来,大小是原来的2倍。后面的rehash都是针对这个新的hash表操作,不涉及原hash表(table)。
- 然后会对原hash表(table)中的每个链表进行rehash,此时会尝试获取头节点的锁。这一步就保证了在rehash的过程中不能对这个链表执行put操作。
- 通过sizeCtl控制,使扩容过程中不会new出多个新hash表来。
- 最后,将所有键值对重新rehash到新表(nextTable)中后,用nextTable将table替换。这就避免了HashMap中get和扩容并发时,可能get到null的问题。
- 在整个过程中,共享变量的存储和读取全部通过volatile或CAS的方式,保证了线程安全。
而至于分析源码,阿粉不再进行分析了,以后在遇到面试的时候分析源码的时候在继续给大家说。毕竟下面还有很多内容。
面试题2:你对着两种方式的看法是什么,为什么1.8要改变呢?优点是哪里呢?
阿粉就猜测到可能这么问,毕竟你开了头了,你都区分出1.7和1.8了,必然会有面试官会这么问你,阿粉是这么回答的。
(1) 减少内存开销
假设使用可重入锁,那么每个节点都需要继承AQS,但并不是每个节点都需要同步支持,只有链表的头节点(红黑树的根节点)需要同步,这无疑消耗巨大内存。
(2) 获得JVM的支持
可重入锁毕竟是API级别的,后续的性能优化空间很小。synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。使得synchronized能够随着JDK版本的升级而不改动代码的前提下获得性能上的提升。
也是亏了阿粉在面试之前的时候看过很多这样的文章,很多东西都专门去比对了一下,于是第二个问题结束了。
面试题3:你们是怎么避免 SQL 注入的?

阿粉看到这个问题的时候,第一反应就是肯定是按照我简历上写的问的,因为阿粉之前的公司就是对安全性要求比较高的,像什么SQL注入啦,像跨站攻击啦,于是阿粉就开始说了。
阿粉在之前的时候时候最多使用的是 where条件后面加上个1=1然后再继续写自己的参数。
- 确认每种数据的类型,比如是数字,数据库则必须使用int类型来存储
- 严格限制数据库权限
- 过滤参数中含有的一些数据库关键词
比如说过滤一些 and,char,这些在数据库语句中是关键字的一些词。
也可能面试官对这些数据安全的方面不是太注重,所以,阿粉回答出这几种方式之后,就已经算是完事了,也没有继续再往下深究。
面试题4:说一下 MySQL常用的引擎都有哪些?
数据库存储引擎是数据库底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能,使用不同的存储引擎,还可以 获得特定的功能。现在许多不同的数据库管理系统都支持多种不同的数据引擎。存储引擎主要有:1. MyIsam , 2. InnoDB, 3. Memory, 4. Archive, 5. Federated 。
关于这个阿粉就不再给大家说了,给大家安排上几张图:

面试题5:看你简历上说用过redis,那么你说一下redis的持久化的方式吧。
- RDB持久化方式能够在指定的时间间隔能对你的数据进行快照存储.
- AOF持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾.Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大.
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
而关于怎么触发,这个就直接去修改redis.conf配置文件即可。
AOF持久化,实际上就是追加保存每次写的操作到文件末尾,也可能阿粉在实际的使用Redis的时候,并没有去做过持久化的操作,回答到这里已经算是没有其他的了,而接下来面试官问的几个关于Redis的问题就回答不是特别的好了,所以在Redis上面,还是得下功夫呀。
面试题6:JVM的内存结构,还有就是不同代的算法。
阿粉在之前的文章已经算是分析的非常的透彻了,所以在这里阿粉就把之前的链接送上,大家可以看一下。
面试的时候按照这个套路回答 Java GC 的相关问题一定能过!

















