前言
时间语义,要配合窗口操作才能发挥作用。最主要的用途,当然就是开窗口、根据时间段做计算了。下面我们就来看看 Table API 和 SQL 中,怎么利用时间字段做窗口操作。在 Table API 和 SQL 中,主要有两种窗口:Group Windows 和 Over Windows
一、分组窗口(Group Windows) 分组窗口(Group Windows)会根据时间或行计数间隔,将行聚合到有限的组(Group)中,并对每个组的数据执行一次聚合函数。 Table API 中的 Group Windows 都是使用.window(w:GroupWindow)子句定义的,并且必须由 as 子句指定一个别名。为了按窗口对表进行分组,窗口的别名必须在 group by 子句中,像常规的分组字段一样引用。例子:
- val table = input
- .window([w: GroupWindow] as 'w)
- .groupBy('w, 'a)
- .select('a, 'w.start, 'w.end, 'w.rowtime, 'b.count)
Table API 提供了一组具有特定语义的预定义 Window 类,这些类会被转换为底层DataStream 或 DataSet 的窗口操作。
Table API 支持的窗口定义,和我们熟悉的一样,主要也是三种:滚动(Tumbling)、滑动(Sliding和 会话(Session)。
1.1 滚动窗口
滚动窗口(Tumbling windows)要用 Tumble 类来定义,另外还有三个方法:
- over:定义窗口长度
- on:用来分组(按时间间隔)或者排序(按行数)的时间字段
- as:别名,必须出现在后面的 groupBy 中
实现案例
1.需求
设置滚动窗口为10秒钟统计id出现的次数。
2.数据准备
- sensor_1,1547718199,35.8
- sensor_6,1547718201,15.4
- sensor_7,1547718202,6.7
- sensor_10,1547718205,38.1
- sensor_1,1547718206,32
- sensor_1,1547718208,36.2
- sensor_1,1547718210,29.7
- sensor_1,1547718213,30.9
3.代码实现
- package windows
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.scala._
- import org.apache.flink.table.api.{EnvironmentSettings, Table, Tumble}
- import org.apache.flink.types.Row
- /**
- * @Package Windows
- * @File :FlinkSQLTumBlingTie.java
- * @author 大数据老哥
- * @date 2020/12/25 21:58
- * @version V1.0
- * 设置滚动窗口
- */
- object FlinkSQLTumBlingTie {
- def main(args: Array[String]): Unit = {
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1)
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
- val settings = EnvironmentSettings.newInstance()
- .useBlinkPlanner()
- .inStreamingMode()
- .build()
- val tableEnv = StreamTableEnvironment.create(env, settings)
- // 读取数据
- val inputPath = "./data/sensor.txt"
- val inputStream = env.readTextFile(inputPath)
- // 先转换成样例类类型(简单转换操作)
- val dataStream = inputStream
- .map(data => {
- val arr = data.split(",")
- SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
- })
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
- override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
- })
- val sensorTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'timestamp.rowtime as 'ts)
- // 注册表
- tableEnv.createTemporaryView("sensor", sensorTable)
- // table 实现
- val resultTable = sensorTable
- .window(Tumble over 10.seconds on 'ts as 'tw) // 每10秒统计一次,滚动时间窗口
- .groupBy('id, 'tw)
- .select('id, 'id.count, 'tw.end)
- //sql 实现
- val sqlTable = tableEnv.sqlQuery(
- """
- |select
- |id,
- |count(id) ,
- |tumble_end(ts,interval '10' second)
- |from sensor
- |group by
- |id,
- |tumble(ts,interval '10' second)
- |""".stripMargin)
- /***
- * .window(Tumble over 10.minutes on 'rowtime as 'w) (事件时间字段 rowtime)
- * .window(Tumble over 10.minutes on 'proctime as 'w)(处理时间字段 proctime)
- * .window(Tumble over 10.minutes on 'proctime as 'w) (类似于计数窗口,按处理时间排序,10 行一组)
- */
- resultTable.toAppendStream[Row].print("talbe")
- sqlTable.toRetractStream[Row].print("sqlTable")
- env.execute("FlinkSQLTumBlingTie")
- }
- case class SensorReading(id: String, timestamp: Long, temperature: Double)
- }
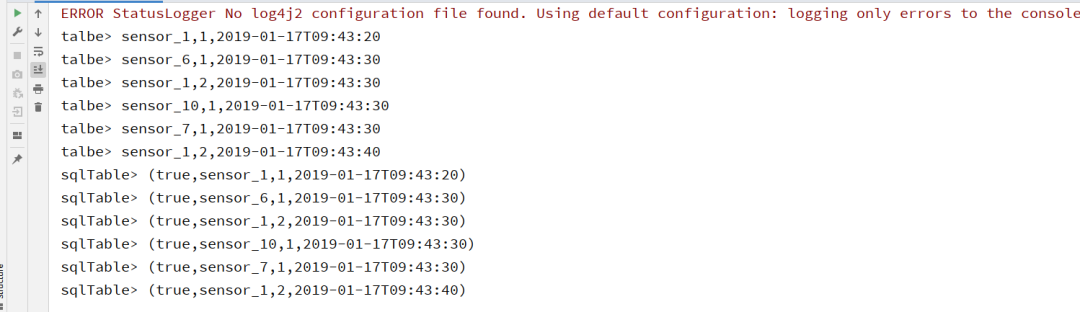
运行结果
1.2 滑动窗口
滑动窗口(Sliding windows)要用 Slide 类来定义,另外还有四个方法:
- over:定义窗口长度
- every:定义滑动步长
- on:用来分组(按时间间隔)或者排序(按行数)的时间字段
- as:别名,必须出现在后面的 groupBy 中
实现案例
1.需求描述
设置窗口大小为10秒钟设置滑动距离为5秒钟,统计id的出现的次数。
2.数据准备
- sensor_1,1547718199,35.8
- sensor_6,1547718201,15.4
- sensor_7,1547718202,6.7
- sensor_10,1547718205,38.1
- sensor_1,1547718206,32
- sensor_1,1547718208,36.2
- sensor_1,1547718210,29.7
- sensor_1,1547718213,30.9
3.实现代码
- package windows
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.{EnvironmentSettings, Slide, Table}
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- import windows.FlinkSQLTumBlingTie.SensorReading
- /**
- * @Package windows
- * @File :FlinkSQLSlideTime.java
- * @author 大数据老哥
- * @date 2020/12/27 22:19
- * @version V1.0
- * 滑动窗口
- */
- object FlinkSQLSlideTime {
- def main(args: Array[String]): Unit = {
- //构建运行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1) // 设置分区为1 方便后面测试
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //事件时间
- val settings = EnvironmentSettings.newInstance()
- .useBlinkPlanner()
- .inStreamingMode()
- .build()
- // 创建表env
- val tableEnv = StreamTableEnvironment.create(env, settings)
- // 读取数据
- val inputPath = "./data/sensor.txt"
- val inputStream = env.readTextFile(inputPath)
- // 先转换成样例类类型(简单转换操作)
- val dataStream = inputStream
- .map(data => {
- val arr = data.split(",")
- SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
- })
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
- override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
- })
- val sensorTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'timestamp.rowtime as 'ts)
- // 注册表
- tableEnv.createTemporaryView("sensor", sensorTable)
- // table API 实现
- val tableApi = sensorTable.window(Slide over 10.seconds every 5.seconds on 'ts as 'w)
- .groupBy('w, 'id)
- .select('id, 'id.count, 'w.end)
- val tableSql = tableEnv.sqlQuery(
- """
- |select
- |id,
- |count(id),
- |HOP_END(ts,INTERVAL '10' SECOND, INTERVAL '5' SECOND )as w
- |from sensor
- |group by
- |HOP(ts,INTERVAL '10' SECOND, INTERVAL '5' SECOND),id
- |""".stripMargin)
- tableApi.toAppendStream[Row].print("tableApi")
- tableSql.toAppendStream[Row].print("tableSql")
- /**
- .window(Slide over 10.minutes every 5.minutes on 'rowtime as 'w) (事件时间字段 rowtime)
- .window(Slide over 10.minutes every 5.minutes on 'proctime as 'w) (处理时间字段 proctime)
- .window(Slide over 10.rows every 5.rows on 'proctime as 'w) (类似于计数窗口,按处理时间排序,10 行一组)
- **/
- env.execute("FlinkSQLSlideTime")
- }
- }
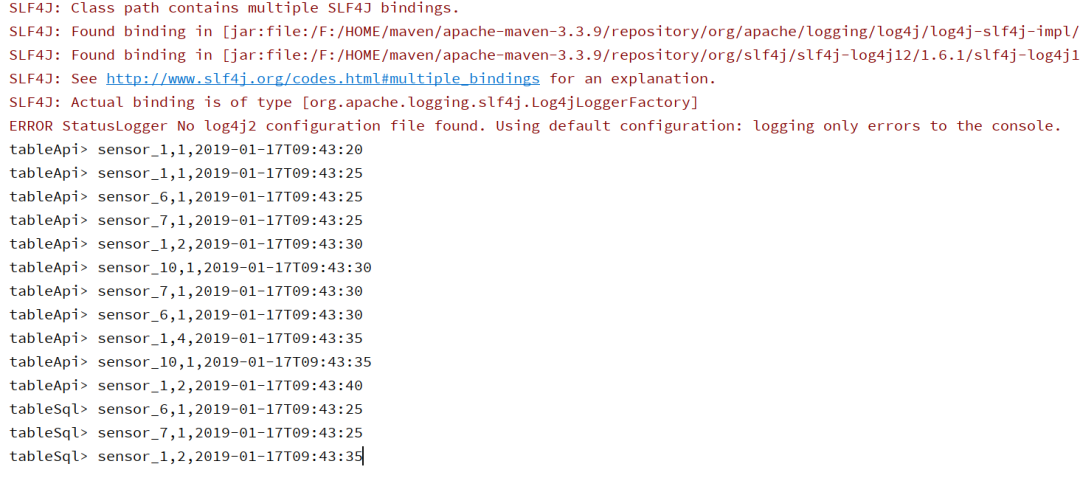
4.运行结果
1.3 会话窗口
会话窗口(Session windows)要用 Session 类来定义,另外还有三个方法:
- withGap:会话时间间隔
- on:用来分组(按时间间隔)或者排序(按行数)的时间字段
- as:别名,必须出现在后面的 groupBy 中实现案例
1.需求描述
设置一个session 为10秒钟 统计id的个数
2.准备数据
- sensor_1,1547718199,35.8
- sensor_6,1547718201,15.4
- sensor_7,1547718202,6.7
- sensor_10,1547718205,38.1
- sensor_1,1547718206,32
- sensor_1,1547718208,36.2
- sensor_1,1547718210,29.7
- sensor_1,1547718213,30.9
3.编写代码
- package windows
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.{EnvironmentSettings, Session, Table}
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- import windows.FlinkSQLTumBlingTie.SensorReading
- /**
- * @Package windows
- * @File :FlinkSqlSessionTime.java
- * @author 大数据老哥
- * @date 2020/12/27 22:52
- * @version V1.0
- */
- object FlinkSqlSessionTime {
- def main(args: Array[String]): Unit = {
- //构建运行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1) // 设置分区为1 方便后面测试
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //事件时间
- val settings = EnvironmentSettings.newInstance()
- .useBlinkPlanner()
- .inStreamingMode()
- .build()
- // 创建表env
- val tableEnv = StreamTableEnvironment.create(env, settings)
- // 读取数据
- val inputPath = "./data/sensor.txt"
- val inputStream = env.readTextFile(inputPath)
- // 先转换成样例类类型(简单转换操作)
- val dataStream = inputStream
- .map(data => {
- val arr = data.split(",")
- SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
- })
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
- override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
- })
- val sensorTable: Table = tableEnv.fromDataStream(dataStream, 'id, 'temperature, 'timestamp.rowtime as 'ts)
- // 注册表
- tableEnv.createTemporaryView("sensor", sensorTable)
- val tableApi = sensorTable.
- window(Session withGap 10.seconds on 'ts as 'w)
- .groupBy('id, 'w)
- .select('id, 'id.count, 'w.end)
- val tableSQL = tableEnv.sqlQuery(
- """
- |SELECT
- |id,
- |COUNT(id),
- |SESSION_END(ts, INTERVAL '10' SECOND) AS w
- |FROM sensor
- |GROUP BY
- |id,
- |SESSION(ts, INTERVAL '10' SECOND)
- |""".stripMargin)
- tableApi.toAppendStream[Row].print("tableApi")
- tableSQL.toAppendStream[Row].print("tableSQL")
- /**
- * .window(Session withGap 10.minutes on 'rowtime as 'w) 事件时间字段 rowtime)
- * .window(Session withGap 10.minutes on 'proctime as 'w) 处理时间字段 proctime)
- */
- env.execute("FlinkSqlSessionTime")
- }
- }
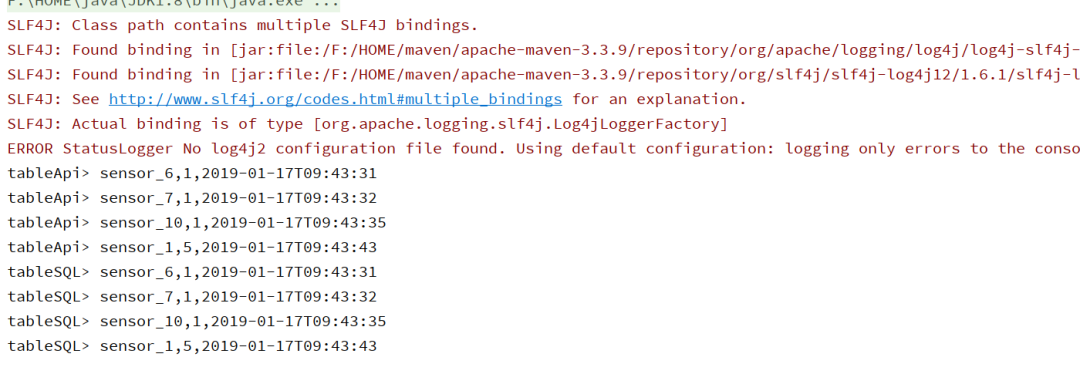
4.运行结果
二、 Over Windows
Over window 聚合是标准 SQL 中已有的(Over 子句),可以在查询的 SELECT 子句中定义。Over window 聚合,会针对每个输入行,计算相邻行范围内的聚合。Over windows使用.window(w:overwindows*)子句定义,并在 select()方法中通过别名来引用。例子:
- val table = input
- .window([w: OverWindow] as 'w)
- .select('a, 'b.sum over 'w, 'c.min over 'w)
Table API 提供了 Over 类,来配置 Over 窗口的属性。可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义 Over windows。
无界的 over window 是使用常量指定的。也就是说,时间间隔要指定 UNBOUNDED_RANGE,或者行计数间隔要指定 UNBOUNDED_ROW。而有界的 over window 是用间隔的大小指定的。
2.1 无界的 over window
- // 无界的事件时间 over window (时间字段 "rowtime")
- .window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_RANGE as 'w)
- //无界的处理时间 over window (时间字段"proctime")
- .window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_RANGE as 'w)
- // 无界的事件时间 Row-count over window (时间字段 "rowtime")
- .window(Over partitionBy 'a orderBy 'rowtime preceding UNBOUNDED_ROW as 'w)
- //无界的处理时间 Row-count over window (时间字段 "rowtime")
- .window(Over partitionBy 'a orderBy 'proctime preceding UNBOUNDED_ROW as 'w)
2.2 有界的 over window
- // 有界的事件时间 over window (时间字段 "rowtime",之前 1 分钟)
- .window(Over partitionBy 'a orderBy 'rowtime preceding 1.minutes as 'w)
- // 有界的处理时间 over window (时间字段 "rowtime",之前 1 分钟)
- .window(Over partitionBy 'a orderBy 'proctime preceding 1.minutes as 'w)
- // 有界的事件时间 Row-count over window (时间字段 "rowtime",之前 10 行)
- .window(Over partitionBy 'a orderBy 'rowtime preceding 10.rows as 'w)
- // 有界的处理时间 Row-count over window (时间字段 "rowtime",之前 10 行)
- .window(Over partitionBy 'a orderBy 'proctime preceding 10.rows as 'w)
2.3 代码练习
我们可以综合学习过的内容,用一段完整的代码实现一个具体的需求。例如,统计每个sensor每条数据,与之前两行数据的平均温度。
数据准备
- sensor_1,1547718199,35.8
- sensor_6,1547718201,15.4
- sensor_7,1547718202,6.7
- sensor_10,1547718205,38.1
- sensor_1,1547718206,32
- sensor_1,1547718208,36.2
- sensor_1,1547718210,29.7
- sensor_1,1547718213,30.9
代码分析:
- package windows
- import org.apache.flink.streaming.api.TimeCharacteristic
- import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
- import org.apache.flink.streaming.api.scala._
- import org.apache.flink.streaming.api.windowing.time.Time
- import org.apache.flink.table.api.{EnvironmentSettings, Over, Tumble}
- import org.apache.flink.table.api.scala._
- import org.apache.flink.types.Row
- /**
- * @Package windows
- * @File :FlinkSqlTumBlingOverTime.java
- * @author 大数据老哥
- * @date 2020/12/28 21:45
- * @version V1.0
- */
- object FlinkSqlTumBlingOverTime {
- def main(args: Array[String]): Unit = {
- // 构建运行环境
- val env = StreamExecutionEnvironment.getExecutionEnvironment
- env.setParallelism(1) // 设置并行度为1方便后面进行测试
- env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 设置事件时间
- val settings = EnvironmentSettings.newInstance()
- .useBlinkPlanner()
- .inStreamingMode()
- .build()
- //构建table Env
- val tableEnv = StreamTableEnvironment.create(env, settings)
- // 读取数据
- val inputPath = "./data/sensor.txt"
- val inputStream = env.readTextFile(inputPath)
- // 先转换成样例类类型(简单转换操作)
- // 解析数据 封装成样例类
- val dataStream = inputStream
- .map(data => {
- val arr = data.split(",")
- SensorReading(arr(0), arr(1).toLong, arr(2).toDouble)
- })
- .assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(1)) {
- override def extractTimestamp(element: SensorReading): Long = element.timestamp * 1000L
- })
- // 将数据注册成一张临时表
- val dataTable = tableEnv.fromDataStream(dataStream,'id, 'temperature, 'timestamp.rowtime as 'ts)
- tableEnv.createTemporaryView("sensor",dataTable)
- var tableRes= dataTable.window( Over partitionBy 'id orderBy 'ts preceding 2.rows as 'ow)
- .select('id,'ts,'id.count over 'ow, 'temperature.avg over 'ow)
- var tableSql= tableEnv.sqlQuery(
- """
- |select
- |id,
- |ts,
- |count(id) over ow,
- |avg(temperature) over ow
- |from sensor
- |window ow as(
- | partition by id
- | order by ts
- | rows between 2 preceding and current row
- |)
- |""".stripMargin)
- tableRes.toAppendStream[Row].print("tableRes")
- tableSql.toAppendStream[Row].print("tableSql")
- env.execute("FlinkSqlTumBlingOverTime")
- }
- case class SensorReading(id: String, timestamp: Long, temperature: Double)
- }
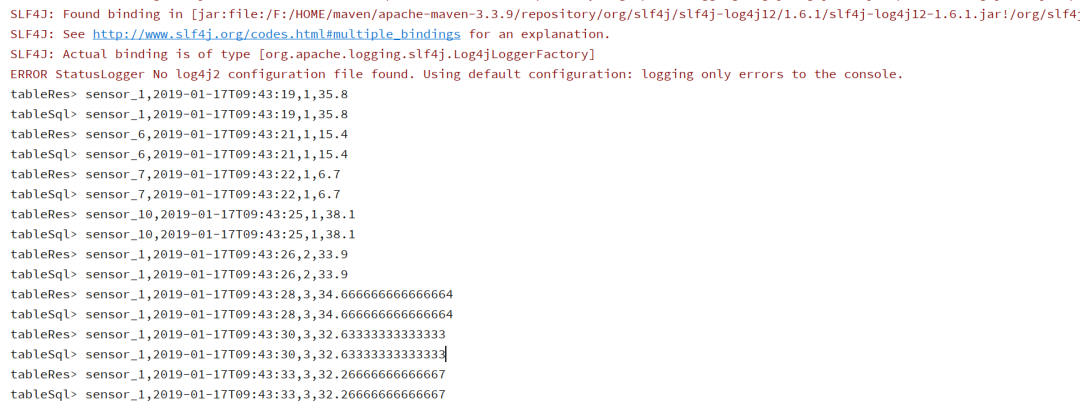
运行结果
总结
好了到这里FlinkSql中窗口使用到这里就结束啦,喜欢的可以给了三连。其中FlinkSql中的窗口的用法还是比较多得,所有还是要多加练习。老话说的好,师傅领进门,修行在个人。
本文转载自微信公众号「 大数据老哥」,可以通过以下二维码关注。转载本文请联系 大数据老哥公众号。