本文转载自公众号“读芯术”(ID:AI_Discovery)
很多人在听到“数据科学”一词时,首先想到的就是“机器学习”。我也一样,在首次接触到机器学习这个听起来十分炫酷的概念时,对数据科学产生了浓厚兴趣。所以当我寻找学习数据科学的切入点时,也受其影响。
这是我犯过的最大错误,也是本文重点:如果想要成为一名数据科学家,请不要从机器学习开始。
显然,要成为一名“真正全能”的数据科学家,最终必须掌握机器学习的概念。但你会惊讶于没有它你能走多远。为什么不从机器学习开始呢?
1.机器学习仅是数据科学的一小部分。
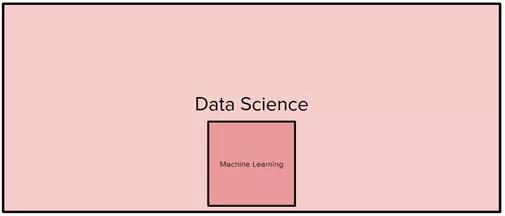
数据科学和机器学习就像是图中所示的矩形和正方形。机器学习是数据科学的一部分,但数据科学并不一定是机器学习,就像正方形是一种矩形,但矩形不一定是正方形一样。事实上,机器学习建模仅占数据科学家工作的5-10%,其余大部分时间基本投入在其他地方。
如果一开始便投身于机器学习,你将付出大量的时间和精力,却收获甚微。
2.若想全面理解机器学习,首先需要掌握其他几门学科的基础知识。
机器学习的核心是建立在统计、数学和概率的基础上。在学习机器学习之前,必须先掌握基本理论知识,夯实理论基础。例如:
- 线性回归是大部分训练营教授的第一个“机器学习算法”,但它实际上是统计方法。
- 进行主成分分析的前提是,学习矩阵和特征向量(线性代数)理念。
- 朴素贝叶斯是完全基于贝叶斯定理(概率)的机器学习模型。
因此,将上述内容归结为两点:一是学习基础知识会使学习更高级的内容变得更加轻松容易;二是通过学习基础知识,可掌握多个机器学习概念。
3. 机器学习并不能解决一切。
许多数据科学家都纠结于此,甚至包括我自己。和我最初的想法一致,大部分数据科学家认为“数据科学”和“机器学习”相辅相成,不可分割。因此,每每遇到问题,数据科学家都首先考虑以机器学习模型作为解决方案。但并非解决所有数据科学问题都需要机器学习模型。
在某些情况下,采用Excel或Pandas进行简单的分析就足以解决当前问题。
在其他情况下,某个问题或许与机器学习完全无关。可能仅需要使用脚本清理和操纵数据、构建数据管道或创建交互式仪表板即可解决,这些问题都无需机器学习。
你应该如何做?
正如上文所述,学习基础知识会让学习更高级的内容变得更加轻松容易,并掌握多个机器学习概念。我知道,如果你正在学习统计学、数学或编程基础知识,你可能会感觉自己在成为一名“数据科学家”的道路上,并未取得进步,但学习这些基础知识定会对你未来的学习大有裨益。
若想从现在开始一些切实具体的行动,可以参考以下步骤:
- 从统计入手。在数学、统计学和编程基础这三个组成部分中,个人认为统计是最重要的一环。如果你害怕学习统计,那么数据科学可能并不适合你。推荐观看佐治亚理工学院的课程《统计方法》(Statistical Methods),或者可汗学院的视频系列(Khan Academy’s videoseries)。
- 学习Python和SQL。我个人工作中从未使用过R语言,所以对R没有太多意见。如果你是一个R型人才,推荐尝试Python和SQL。使用Python和SQL的能力越强,在数据收集、操纵和实现方面就会越容易。
除此之外,熟悉Pandas、NumPy和Scijit-learn等Python库也是一个不错的选择。而由于二叉树是许多高级机器学习算法(如XGBoost)的基础,所以也推荐大家学习。
- 学习线性代数基础。处理任何与矩阵相关的事情时,线性代数就变得极其重要。这一点在推荐系统和深度学习应用中十分常见。
- 学习数据操纵。数据操纵至少占数据科学家工作的50%。更具体地说,学习更多关于特征工程、探索性数据分析和数据准备的知识。
我的总体建议是,由于机器学习一没有充分利用时间,二无助于你成为工作中卓有成就的数据科学家,因此,以机器学习为学习重点并不可取。不过要注意的是,这是一篇个人观点十分强烈的文章,所以,取你所想,取你所益。