













孤立森林或者"iForest"是一个优美动人,简洁优雅的算法,只需少量参数就可以检测出异常点。原始论文中只包含了最基本的数学,因而对于广大群众而言是通俗易懂的。在这篇文章中,我会总结这个算法,以及其历史,并分享我实现的代码来解释为什么iForest是现在针对大数据而言最好的异常检测算法。
为什么iForest是现在处理大数据最好的异常检测算法
总结来说,它在同类算法中有最好的表现。iForest在多种数据集上的ROC表现和精确度都比大多数其他的异常检测算法要好。我从Python Outlier Detection package的作者们那里取得了基准数据,并在Excel中逐行使用绿-红梯度的条件格式化。用深绿色来标识那些在这个数据集上有最好的表现的算法,并用深红色来标识那些表现得最差的:
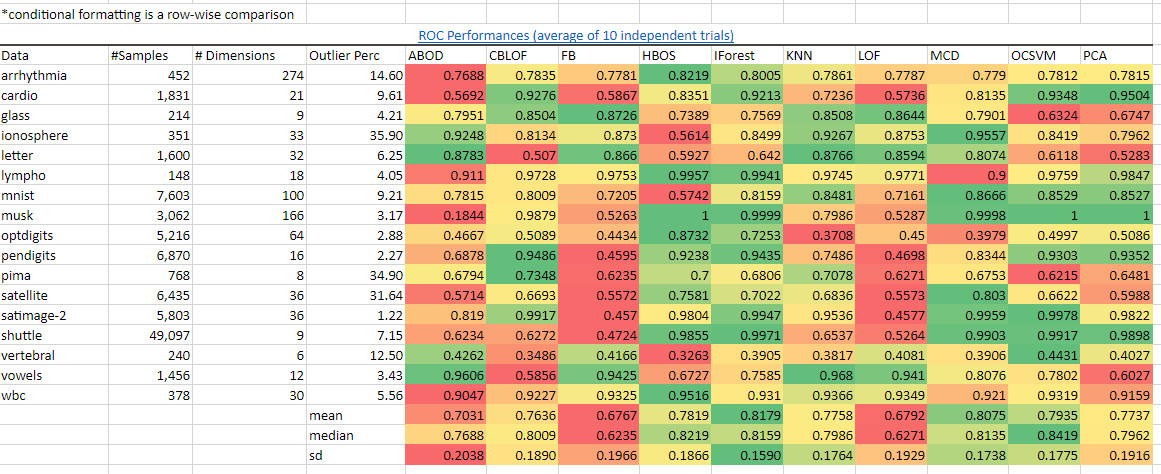
绿色表示"好"而红色表示"差"。我们看到IForest在很多的数据集以及总体的角度上是领先的,正如平均值,中位数,标准差的颜色所表示。图源:作者。数据源:https://pyod.readthedocs.io/en/latest/benchmark.html
我们看到IForest在很多的数据集上以及总体上的表现是领先的,正如我计算出来的平均值,中位数,标准差的颜色所表示的一样。从precision@N(最重要的N项指标的准确度)的表现来看iForest也能得出同样的优秀结果。
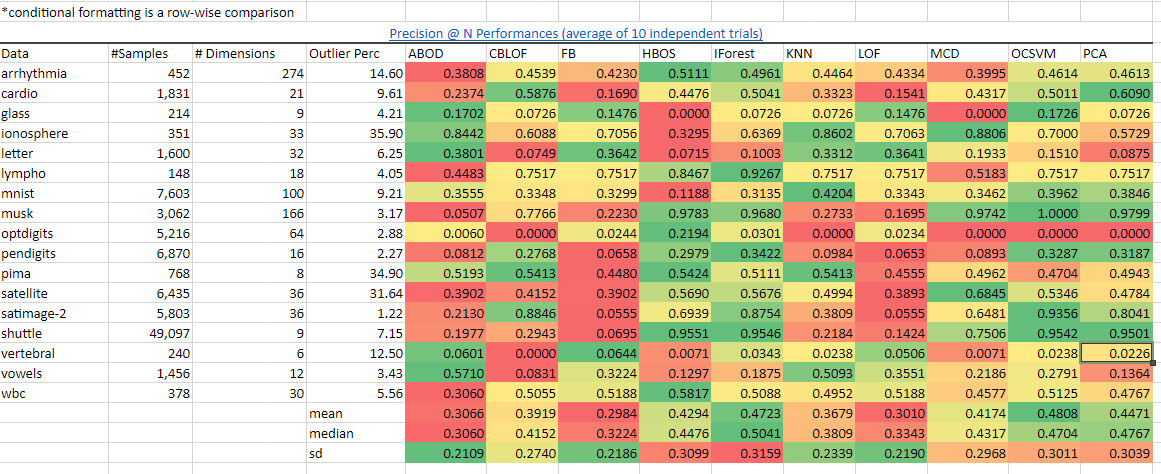
源:https://pyod.readthedocs.io/en/latest/benchmark.html
可扩展性。iForest以它表现出来的性能为标准而言是最快的算法。可以预料到的是,PCA和基于频数直方图的异常点检测算法(HBOS)在所有的数据集上都有更快的速度。
k近邻算法(KNN)则要慢得多并且随着数据量变多它会变得越来越慢。
我已经成功地在一个包含一亿个样本和三十六个特征的数据集上构建出孤立森林,在一个集群环境中这需要几分钟。而这是我认为sklearn的KNN算法没办法做到的。
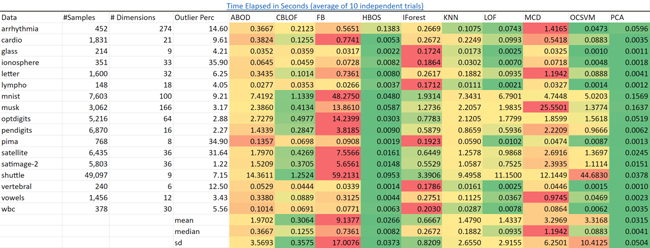
源:https://pyod.readthedocs.io/en/latest/benchmark.html
算法要点/总结
我通过下面的综述来非常简洁地总结原来有10页内容的论文:
- 大多数其他异常检测(OD)算法尝试去建立"正常"数据的范围,从而把不属于这个正常范畴的个体标注为不正常。iForest则直接通过利用异常点的隐含特质来把他们分隔开:他们在协变量集上会拥有不寻常的值。
- 现有的方法由于计算成本的原因只能被用在低维数据或者小数据集上。一个恰当的例子是:你会在大数据上使用sklearn.neighbor.KNeighborsClassifier吗?
- 此外,iForest只需要很少的常量和很低的内存需求。也就是说,低开销。特别地:外部节点的数量是n,因为每个观测数据,n,都会被孤立。内部节点的总数显然是n-1,从而总体节点数会是2n-1。因此,我们可以理解为什么需要的内存是有界的,而且随着样本数量n线性增加。
孤立树节点的定义: T 或是一个没有子节点的叶子节点,或者是一个经过检验的内部节点,并拥有两个子节点(Tl,Tr)。我们通过递归地进行下述过程来构造一棵iTree:随机选择一项特征q和一个分割值p来划分X,直到发生下列情形之一为止:(i)树到达了限制的高度,(ii)所有样本被孤立成一个只有他们自己的外部节点,或者(iii)所有数据的所有特征都有相同的值。
路径长度:一个样本x的路径长度h(x)指的是从iTree的根节点走到叶子节点所经历的边的数量。E(h(x))是一组孤立树的h(x)的平均值。从这个路径长度的平均值,我们可以通过公式E(h(x)):s(x, n) = 2^[^[− E(h(x)) / c(n)]来得到一个异常分数s(x,n)。基本上,s和E(h(x))之间存在一个单调的关系。(想知道细节的话请查阅文末的附录,有一张图描述了他们之间的关系)。这里我不会讨论c(n),因为对于任意给定的静态数据集而言它是一个常数。
用户只需要设置两个变量:孤立树的数量和训练单棵树的子采样大小。作者通过对用高斯分布生成的数据做实验来展示了只需要少量的几棵树和少量的子采样数量就可以使平均路径长度很快地收敛。
小的子采样数量(抽样的抽样)解决了swamping和masking问题。造成这两个问题的原因是输入的数据量对于异常检测这个问题来说太大了。Swamping是指由于某个"正常"的样本点被异常点所包围而被错误地标注为"异常",masking则是相反的情况。也就是说,如果构建一个树的样本中有很多异常点,一个正常的数据点反而会看起来很异常。作者使用乳房x线照相的数据来作为这个现象的一个例子。
小的子采样数量使得每一棵孤立树都具有独特性,因为每一次子采样都包含一组不同的异常点或者甚至没有异常点。
iForest不依赖距离或者密度的测量来识别异常点,因此它计算成本低廉且有较快的速度。这引出了下一个议题。
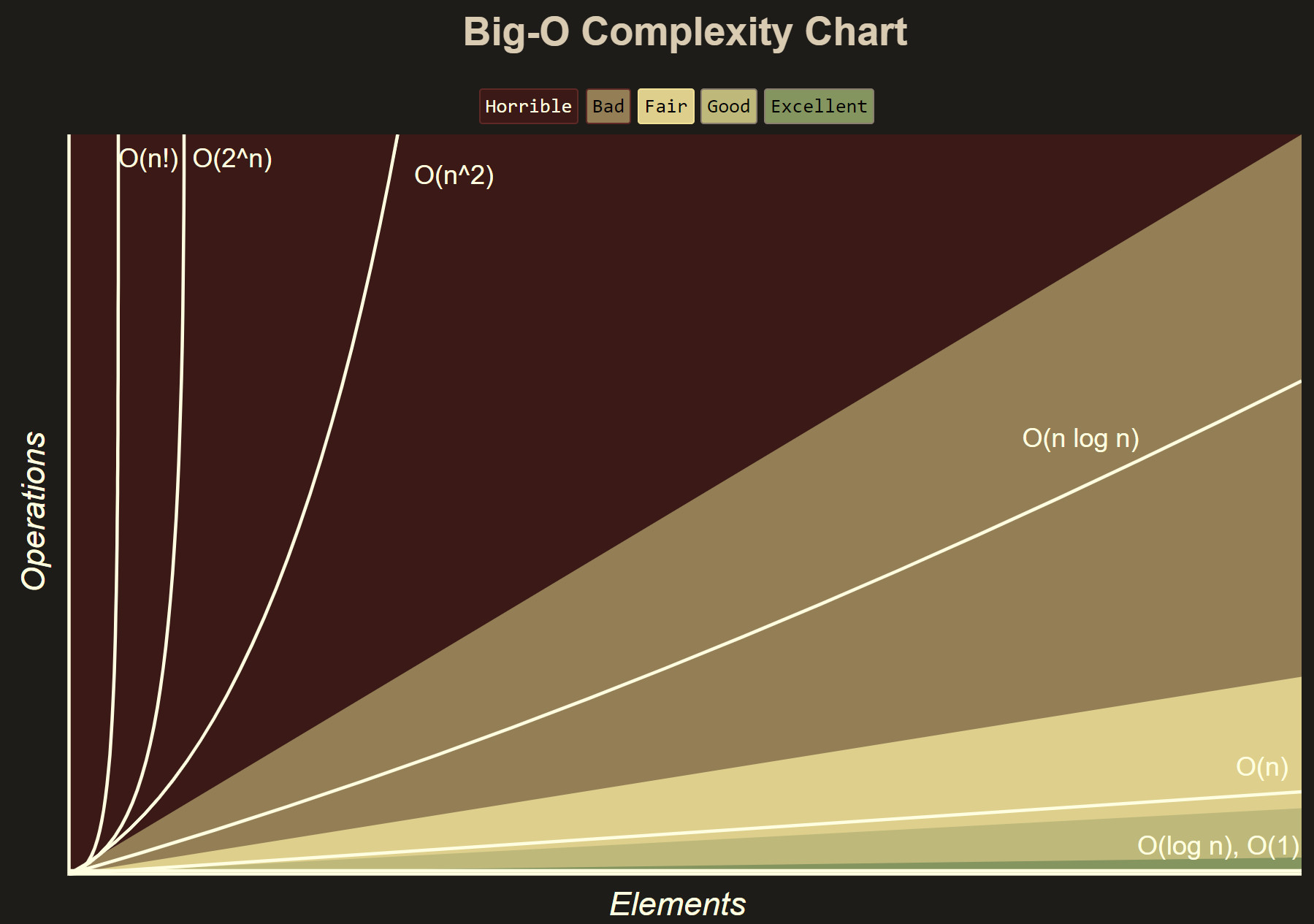
线性的时间复杂度,O(n)。不正规地说,这意味着运行时间随着输入大小的增加最多只会线性增加。这是一个非常好的性质:
算法历程
见多识广的读者应该知道一个优秀的新想法出现与它的广泛应用之间可能会有数十年之久的间隔。例如,逻辑函数在1845年被发现,在1922年被重新发现(更多信息可参考)而到如今才被数据科学家频繁地用于逻辑回归。在最近几十年,一个新想法和它被广泛应用的间隔时间已经变得更短了,但这仍然需要一段相对较为漫长的时间。iForest最先在2008年公开,但直到2018年后期才出现了可行的商业应用。 这是其时间线:
- 12/2008 -iForest的原始论文发布(论文)
- 07/2009 -iForest的作者们最后一次修改其代码实现(代码)
- 10/2018 -h2o小组实现了Python版和R版的iForest(代码)
- 01/2019 -PyOD在Python上发布了异常检测工具包(代码,论文)
- 08/2019 -Linkedln 工程小组发布了 iForest的Spark/Scala版本实现(代码,通讯稿)
代码实现
由于这篇文章是关于大数据的,我采用了AWS的集群环境。这里省略的大部分的脚手架(软件质量保证和测试之类的代码)的代码。如果在配置AWS集群环境中需要帮助,可以参考我的文章:如何为SparkSQL搭建高效的AWS
EMR集群和Jupyter Notebooks
我发现iForest能很轻易且快捷地处理750万行,36个特征的数据,只需几分钟就完成计算。
Python(h2o):
- import h2o # h2o automated data cleaning well for my datasetimport pkg_resources################################################################### print packages + versions for debugging/future reproducibility ###################################################################dists = [d for d in pkg_resources.working_set] # Filter out distributions you don't care about and use.dists.reverse()
- dists################################################################### initialize h2o cluster and load data##################################################################h2o.init() # import pyarrow.parquet as pq # allow loading of parquet filesimport s3fs # for working in AWS s3s3 = s3fs.S3FileSystem()df = pq.ParquetDataset('s3a://datascience-us-east-1/anyoung/2_processedData/stack_parquetFiles', filesystem=s3).read_pandas().to_pandas()# check input data loaded correctly; pretty print .shapeprint('(' + '; '.join(map('{:,.0f}'.format,
- df.shape)) + ')')# if you need to sample datadf_samp_5M = df.sample(n=5000000, frac=None, replace=False, weights=None, random_state=123, axis=None)# convert Pandas DataFrame object to h2o DataFrame objecthf = h2o.H2OFrame(df)# drop primary key columnhf = hf.drop('referenceID', axis = 1) # referenceID causes errors in subsequent code# you can omit rows with nas for a first passhf_clean = hf.na_omit()# pretty print .shape with thousands comma separatorprint('(' + '; '.join(map('{:,.0f}'.format,
- hf.shape)) + ')')from h2o.estimators import H2OIsolationForestEstimatorfrom h2o.estimators import H2OIsolationForestEstimator
- fullX = ['v1',
- 'v2',
- 'v3' ]# split h2o DataFrame into 80/20 train/testtrain_hf, valid_hf = hf.split_frame(ratios=[.8], seed=123)# specify iForest estimator modelsisolation_model_fullX = H2OIsolationForestEstimator(model_id = "isolation_forest_fullX.hex", seed = 123)
- isolation_model_fullX_cv = H2OIsolationForestEstimator(model_id = "isolation_forest_fullX_cv.hex", seed = 123)# train iForest modelsisolation_model_fullX.train(training_frame = hf, x = fullX)
- isolation_model_fullX_cv.train(training_frame = train_hf, x = fullX)# save models (haven't figured out how to load from s3 w/o permission issues yet)modelfile = isolation_model_fullX.download_mojo(path="~/", get_genmodel_jar=True)print("Model saved to " + modelfile)# predict modelspredictions_fullX = isolation_model_fullX.predict(hf)# visualize resultspredictions_fullX["mean_length"].hist()
如果你使用iForest来验证你的带标签数据,你可以通过比较数据集中的正常数据的分布,异常数据的分布,以及原来数据集的分布来进行进一步推理。例如,你可以查看原本数据集中不同的特征组合,像这样:
- N = df.count()
- df[['v1', 'v2', 'id']].groupby(['v1', 'v2']).count() / N
- df[['v1', 'v3', 'id']].groupby(['v1', 'v3']).count() / N
- ...
并与使用iForest得出的正常/异常数据集进行比较。正如下面所展示的这样:
- ################################################################### column bind predictions from iForest to the original h2o DataFrame##################################################################hf_X_y_fullX = hf.cbind(predictions_fullX)################################################################### Slice using a boolean mask. The output dataset will include rows # with column value meeting condition##################################################################mask = hf_X_y_fullX["label"] == 0hf_X_y_fullX_0 = hf_X_y_fullX[mask,:]
- mask = hf_X_y_fullX["label"] == 1hf_X_y_fullX_1 = hf_X_y_fullX[mask,:]################################################################### Filter to only include records that are clearly normal##################################################################hf_X_y_fullX_ml7 = hf_X_y_fullX[hf_X_y_fullX['mean_length'] >= 7]
- hf_X_y_fullX_0_ml7 = hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length'] >= 7]
- hf_X_y_fullX_1_ml7 = hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length'] >= 7]################################################################### Convert to Pandas DataFrame for easier counting/familiarity##################################################################hf_X_y_fullX_ml7_df = h2o.as_list(hf_X_y_fullX_ml7, use_pandas = True)
- hf_X_y_fullX_0_ml7_df = h2o.as_list(hf_X_y_fullX_0_ml7, use_pandas = True)
- hf_X_y_fullX_1_ml7_df = h2o.as_list(hf_X_y_fullX_1_ml7, use_pandas = True)################################################################### Look at counts by combinations of variable levels for inference##################################################################hf_X_y_fullX_ml7_df[['v1', 'v2', 'id']].groupby(['v1', 'v2']).count()
- hf_X_y_fullX_0_ml7_df = h2o.as_list(hf_X_y_fullX_0_ml7, use_pandas = True)...# Repeat above for anomalous records:################################################################### Filter to only include records that are clearly anomalous##################################################################hf_X_y_fullX_ml3 = hf_X_y_fullX[hf_X_y_fullX['mean_length'] < 3]
- hf_X_y_fullX_0_ml3 = hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length'] < 3]
- hf_X_y_fullX_1_ml3 = hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length'] < 3]################################################################### Convert to Pandas DataFrame for easier counting/familiarity##################################################################hf_X_y_fullX_ml3_df = h2o.as_list(hf_X_y_fullX_ml3, use_pandas = True)
- hf_X_y_fullX_0_ml3_df = h2o.as_list(hf_X_y_fullX_0_ml3, use_pandas = True)
- hf_X_y_fullX_1_ml3_df = h2o.as_list(hf_X_y_fullX_1_ml3, use_pandas = True)
我完整地实现了上面的代码并把我的数据输出到Excel中,很快就可以得到如下的一些累积分布函数:

代表的是标识为0的样本,被认为有可能是异常的。
参考文献
- F. T. Liu, K. M. Ting, and Z.-H. Zhou.孤立森林. 在:第八届IEEE数据挖掘国际会议的期间(ICDM' 08),Pisa,Italy,2008,pp.413-422.[代码]这篇文章在IEEE ICDM'08荣获了最佳理论/算法论文奖的第二名
- Zhao, Y., Nasrullah, Z. and Li, Z., 2019. PyOD:一个可量化的异常检测Python工具箱.Journal of machine learning research (JMLR) , 20(96),pp.1-7.
本文转自雷锋网,如需转载请至雷锋网官网申请授权。




















