本文转载自公众号“读芯术”(ID:AI_Discovery)。
近十年来,卷积神经网络一直在全球计算机视觉研究领域发挥着主导作用。但研究者们正在提出一种新方法,想要利用转换器的功能赋予图像更深层的意义。
转换器最初是为自然语言处理任务而设计的,主攻神经网络机器翻译。后来,谷歌研究院的阿列克谢·多索维斯基(Alexey Dosovitskiy)、卢卡斯·拜尔(Lucas Beyer)等人撰写了一篇题目为《一幅图像值得16x16个字符:大规模用于图像识别的转换器》的论文,提出了一种名为视觉转换器(ViT)的架构,该架构可通过转换器处理图像数据。
卷积神经网络(CNN)存在的问题
在深入研究视觉转换器的运行方式之前,厘清卷积神经网络的缺点和根本缺陷很有必要。首先,卷积神经网络无法编码相对空间信息。也就是说,它仅关注于检测某些特征,而忽略了相对空间位置。
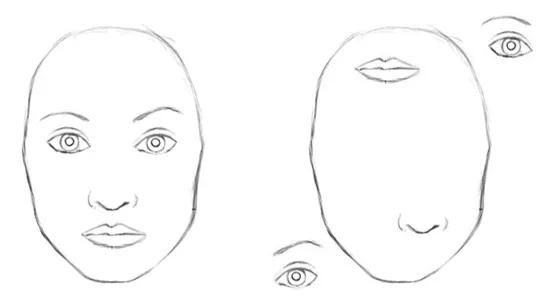
上面两幅图像都会被识别为人脸,因为卷积神经网络只关注输入图像中是否存在某些特征,而忽略了它们相对于彼此的位置。
卷积神经网络的另一个主要缺陷是池化层。池化层会丢失很多有用的信息,比如最活跃的特征检测器的准确位置。换句话说,它能检测到某些特征,但却无法传达其在图像中的准确位置。
转换器简介
从本质上说,转换器应用了自我注意的概念。这个概念可以分为两部分:自我和注意。注意指的仅仅是可训练的权重,它可以模拟输入句子中各部分的重要程度。
假设输入了一个句子,它会观察句子中的每个单词,并将该单词在句子中的位置与同一句子中所有单词(包括该单词在内)的位置进行比较。所以说,转换器应用了自我注意的概念。转换器根据这些位置线索计算分数,然后用这些线索更好地编码句子的语义或意义。
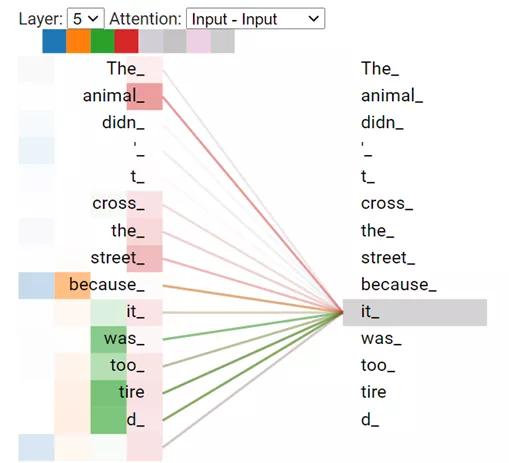
从以上示例中,大家可以发现,转换器中的注意单元正在比较单词“it”与句子中包括“it”在内的其他所有单词的位置。不同的颜色代表着同时独立运行的多个注意单元,目的是发现这些联系中的不同模式。
一旦通过上述比较计算出一个分数,它们就会经由结构简单的前馈神经元层发送出去,最后进行规范化处理。在训练期间,转换器学习了这些注意向量。
模型架构
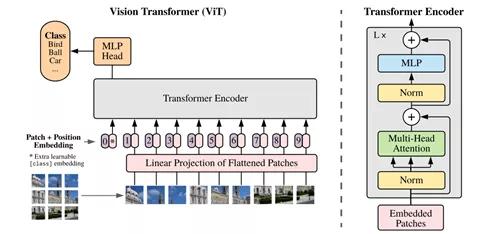
和常规转换器通过单词了解句子一样,视觉转换器通过像素获得类似的图像效果。不过,这里有一个问题。与文字不同,单一像素本身并不传达任何含义,这也是我们选择使用卷积过滤器的原因之一(它可对一组像素进行操作)。
它们将整个图像分成小块图像或单词。所有小块图像都通过线性投影矩阵展平,同它们在图像中的位置一起送入转换器(如上图所示)。在这一过程中,研究人员们选择了大小为16x16的小块图像,所以才有了这样诗意的研究题目。
现在,这些嵌入的小块图像通过多方面自我注意的交替层、多层感知器(结构简单的前馈神经元层)和类似于常规转换器中的层规范化,分类头安装在转换器编码器的末端,从而预测最终分类。像其他的卷积模型一样,人们可以使用预先训练好的编码器库和一个自定义MLP层来微调模型,以适应其分类任务。

重点
论文作者在ImageNet、CIFAR-10/100和JFT-300M(谷歌的私有数据集,拥有3亿张高分辨率图像)等各种标注数据集上训练了该模型。在准确性方面,他们的模型几乎和其他先进的卷积模型一样准确(在很多情况下甚至更准确),但训练时间大大减少了(减少了大约75%),而且使用的硬件资源也更少。
视觉转换器的另一个优点是能够很早地了解到更高层级的关系,原因是它使用了全球注意而非局部注意。人们甚至在一开始就可以注意到那些相对于卷积神经网络很遥远的事物。除了在训练过程中保持高效以外,视觉转换器还会随着训练数据的增多而表现愈佳。

图源:unsplash
难道这意味着卷积神经网络已经过时,而视觉转换器成为了新常态吗?
当然不是!虽然卷积神经网络存在不足,但它在处理对象检测和图像分类等任务方面仍然十分高效。作为最先进的卷积架构,ResNet和EfficientNet仍然占据着处理此类任务的主导地位。然而,转换器在自然语言处理任务(比如语言翻译)方面取得了突破,在计算机视觉领域显示出了不小的潜力。
在这个不断发展的研究领域,未来会发生什么?只有时间会告诉我们答案。