自上世纪以来,逻辑回归是一种流行的方法。它建立了分类变量和一个或多个自变量之间的关系。在机器学习中使用此关系来预测分类变量的结果。它被广泛用于许多不同的领域,例如医疗领域,贸易和商业,技术等等。
本文介绍了二进制分类算法的开发过程,并将其在Kaggle的心脏病数据集上实现。
问题陈述
在本文中,我们将使用来自Kaggle的数据集,其中包含人口的健康数据。它的末尾有一列,其中包含一个人是否患有心脏病。我们的目标是使用表格中的其他列查看是否可以预测一个人是否患有心脏病。
在这里,我将加载数据集。我将为此使用Pandas:
- import pandas as pd
- import numpy as np
- df = pd.read_csv('Heart.csv')
- df.head()
数据集如下所示:

> Top five rows of the Haert.csv dataset
查看数据集的最后一列。是" AHD"。这表示心脏病。我们将使用其余的列来预测心脏病。因此,将来,如果我们拥有所有数据,则无需进行医疗检查就可以预测一个人是否患有心脏病。
我们的输出将为0或1。如果一个人患有心脏病,我们的算法将返回1;如果一个人没有心脏病,该算法应返回0。
重要方程
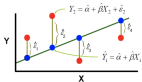
记住线性回归公式。直线的非常基本的公式:Y = A + BX
其中A是截距,B是斜率。如果在此方程式中避免使用"拦截" A,则公式将变为:Y = BX
传统上,在机器学习中,它被压为
在这里," h"是假设或预测值,而X是预测变量或输入变量。Theta从一开始就随机初始化,之后再进行更新。
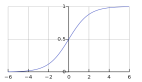
对于logistic回归,我们需要使用Sigmoid函数(返回值从0到1)转换此简单假设。Sigmoid函数也可以称为logistic函数。Logistic回归使用S形函数来预测输出。这是S形激活函数:
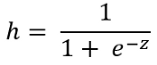
z是输入特征乘以随机初始化的项theta。
在此,X是输入特征,theta是将在此算法中更新的随机初始化值。
我们需要使用逻辑函数的原因是,逻辑函数的曲线如下所示:
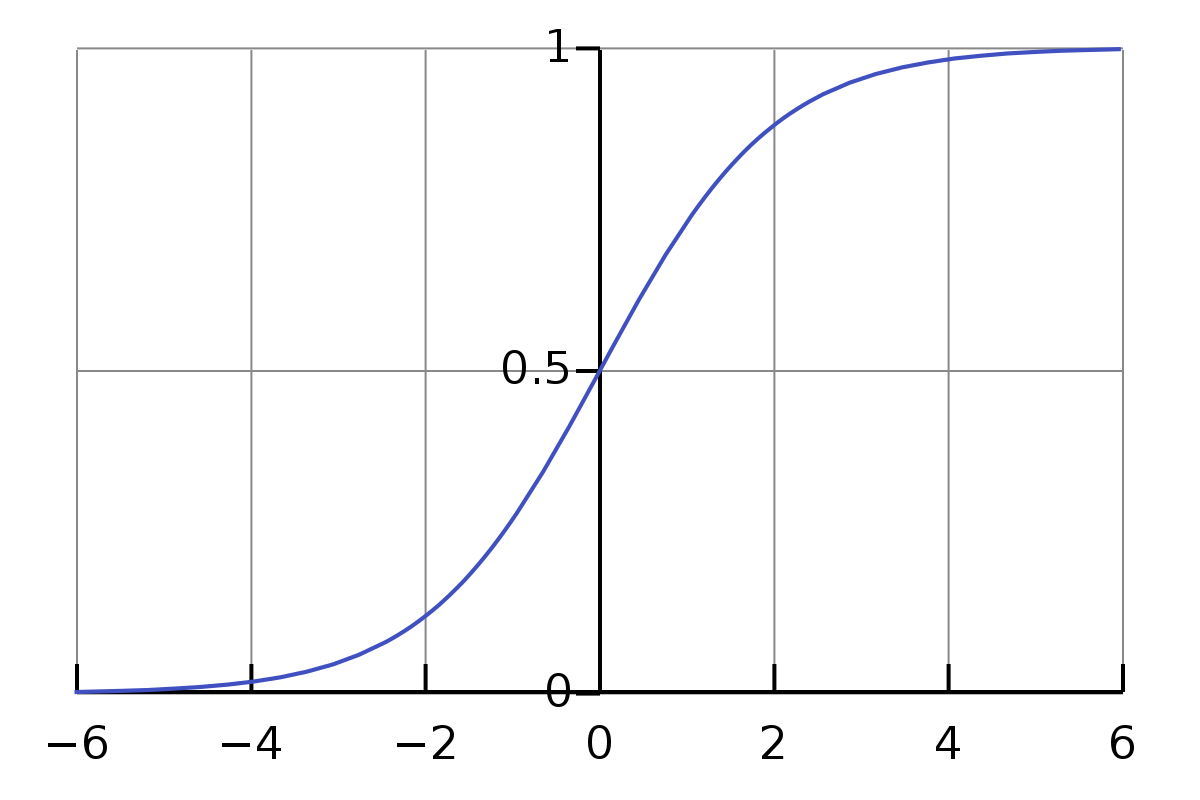
> Image by Author
从上图可以看到,它返回0到1之间的值。因此,这对于分类非常有帮助。由于我们今天将进行二进制分类,
如果逻辑函数返回的值小于0.5,则返回零;如果逻辑函数返回的值大于或等于0.5,则返回1。
(1) 成本函数
成本函数为您提供了预测输出(计算的假设" h")与原始输出(数据集中的" AHD"列)相差多少的度量。
在深入探讨逻辑回归的成本函数之前,我想提醒您线性回归的成本函数要简单得多。线性回归的成本为:

哪里,
y是原始标签(数据集的" AND"列)
平均成本函数为:
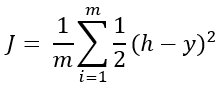
哪里,m是训练数据的数量
上面的等式首先考虑了预测标签" h"和原始标签" y"之间的差异。该公式包括平方以避免任何负值,并使用1/2优化该平方。
这个简单明了的方程式适用于线性回归,因为线性回归使用一个简单的线性方程式:(Y = A + BX)。
但是逻辑回归使用不是线性的S型函数。
我们不能在这里使用该简单的成本函数,因为它不会收敛到全局最小值。为了解决此问题,我们将使用日志对成本函数进行正则化,使其收敛到全局最小值。
这是我们用来保证全局最小值的成本函数:
- 如果y = 1,成本(h,y)= -log(h)
- 如果y = 0,Cost(h,y)= -log(1 — h)
简化组合成本函数:
这是成本函数表达式:
为什么这样的方程式?看,我们只能有两种情况y = 0或1。在上面的成本函数方程中,我们有两个条件:
- y * logh和
- (1-y)* log(1-h)。
如果y = 0,则第一项变为零,第二项变为log(1-h)。在等式中,我们已经在开头放置了一个负号。
如果y = 1,则第二项变为零,仅保留ylogh项,并在开始处带有负号。
我希望现在有道理!
(2) 梯度下降
我们需要更新随机初始化的theta值。梯度下降方程式就是这样做的。如果我们将成本函数与theta进行偏微分:
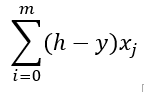
在梯度下降公式上方使用此表达式将变为:

在这里,alpha是学习率。
使用该方程式,θ值将在每次迭代中更新。当您将在python中实现Thin时,对您来说会更加清楚。
现在是时候使用以上所有方程式来开发算法了
模型开发
步骤1:建立假设。
该假设只是S形函数的实现。
- def hypothesis(X, theta):
- z = np.dot(theta, X.T)
- return 1/(1+np.exp(-(z))) - 0.0000001
由于成本函数中的此表达式,我从此处的输出中扣除了0.0000001:
如果假设表达式的结果为1,则该表达式的结果将为零的对数。为了缓解这种情况,我最后使用了这个很小的数字。
步骤2:确定成本函数。
- def cost(X, y, theta):
- y1 = hypothesis(X, theta)
- return -(1/len(X)) * np.sum(y*np.log(y1) + (1-y)*np.log(1-y1))
这只是上面成本函数方程式的简单实现。
步骤3:更新theta值。
Theta值需要不断更新,直到成本函数达到最小值为止。我们应该获得最终的theta值和每次迭代的成本作为输出。
- def gradient_descent(X, y, theta, alpha, epochs):
- m =len(X)
- J = [cost(X, y, theta)]
- for i in range(0, epochs):
- h = hypothesis(X, theta)
- for i in range(0, len(X.columns)):
- theta[i] -= (alpha/m) * np.sum((h-y)*X.iloc[:, i])
- J.append(cost(X, y, theta))
- return J, theta
步骤4:计算最终预测和准确性
使用来自" gradient_descent"函数的theta值,并使用S型函数计算最终预测。然后,计算精度。
- def predict(X, y, theta, alpha, epochs):
- J, th = gradient_descent(X, y, theta, alpha, epochs)
- h = hypothesis(X, theta)
- for i in range(len(h)):
- h[i]=1 if h[i]>=0.5 else 0
- y = list(y)
- acc = np.sum([y[i] == h[i] for i in range(len(y))])/len(y)
- return J, acc
最终输出是每个时期的成本清单和准确性。让我们实现此模型以解决实际问题。
数据预处理
我已经在开始显示了数据集。但是为了方便起见,我在这里再次添加了它:
注意,数据集中有一些分类特征。我们需要将它们转换为数值数据。
- df["ChestPainx"]= df.ChestPain.replace({"typical": 1, "asymptomatic": 2, "nonanginal": 3, "nontypical": 4})
- df["Thalx"] = df.Thal.replace({"fixed": 1, "normal":2, "reversable":3})
- df["AHD"] = df.AHD.replace({"Yes": 1, "No":0})
为偏差增加一列。这应该是一列,因为任何实数乘以1都会保持不变。
- df = pd.concat([pd.Series(1, index = df.index, name = '00'), df], axis=1)
定义输入要素和输出变量。输出列是我们要预测的类别列。输入特征将是除我们之前修改的分类列以外的所有列。
- X = df.drop(columns=["Unnamed: 0", "ChestPain", "Thal"])
- y= df["AHD"]
获取精度结果
最后,初始化列表中的theta值并预测结果并计算精度。在这里,我正在初始化theta值,例如0.5。可以将其初始化为其他任何值。由于每个要素应具有对应的theta值,因此应为X中的每个要素(包括偏置列)初始化一个theta值。
- theta = [0.5]*len(X.columns)
- J, acc = predict(X, y, theta, 0.0001, 25000)
最终精度为84.85%。我使用0.0001作为学习率,并进行25000次迭代。
我运行了几次该算法来确定这一点。
请检查下面提供的该项目的我的GitHub链接。
"预测"功能还会返回每次迭代的费用列表。在一个好的算法中,每次迭代的成本应不断降低。绘制每次迭代的成本以可视化趋势。
- %matplotlib inline
- import matplotlib.pyplot as plt
- plt.figure(figsize = (12, 8))
- plt.scatter(range(0, len(J)), J)
- plt.show()
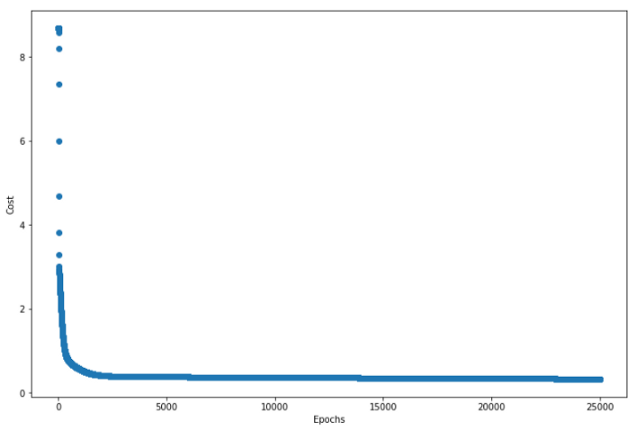
成本从一开始就迅速下降,然后下降速度放慢。这是完美成本函数的行为!
结论
我希望这可以帮到你。如果您是初学者,那么一开始就很难掌握所有概念。但是我建议您自己在笔记本中运行所有代码,并仔细观察输出。这将非常有帮助。这种类型的逻辑回归有助于解决许多现实世界中的问题。希望您会用它来开发一些很棒的项目!
如果您在运行任何代码时遇到问题,请在评论部分让我知道。
在这里,您将找到完整的代码:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/LogisticRegressionWithHeartDataset.ipynb