在机器学习领域大热的分类学习任务中,为了保证训练得到的分类模型具有准确性和高可靠性,一般会作出两个基本假设:
用于学习的训练样本与新的测试样本满足独立同分布;
必须有足够可用的训练样本才能学习得到一个好的分类模型。
但实际情况很难满足这两个条件。
很多 ML 技术只有在训练数据和测试数据处于相同的特征空间中或具有相同分布的假设下才能很好地发挥作用,一旦随着时间推移,标签可用性变差或标注样本数据缺乏,效果便不尽如人意。
因此,这就引起 ML 中另一个需要关注的重要问题,如何利用源领域(Source domian)中少量的可用标签训练样本 / 数据训练出鲁棒性好的模型,对具有不同数据分布的无标签 / 少可用标签的目标领域(Target domain)进行预测。
由此,迁移学习(Transfer Learning)应运而生,并引起了广泛的关注和研究。
近几年来,已经有越来越多的研究者投入到迁移学习中。每年机器学习和数据挖掘的顶级会议中都有关于迁移学习的文章发表。
顾名思义,迁移学习就是把一个领域已训练好的模型参数迁移到另一个领域,使得目标领域能够取得更好的学习效果。鉴于大部分的数据具有存在相关性,迁移学习可以比较轻松地将模型已学到的知识分享给新模型,从而避免了从头学习,这加快效率,也大大提高样本不充足任务的分类识别结果。
今年的 NeurIPS 上,谷歌的一支研究团队发表了一篇名为 What is being transferred in transfer learning? 的论文,揭示了关于迁移学习的最新研究进展。

在这篇论文中,作者便向我们提供了新的工具和分析方法,从不同的角度剖析了不同模块的作用及影响成功迁移的因素,得到了一些有趣的结论,例如,相比高层的特征,预训练模型适合迁移的主要是低层的统计信息。
具体而言,通过对迁移到块混洗图像(block-shuffled images)的一系列分析,他们从学习低层数据统计中分离出了特征复用(feature reuse)的效果,并表明当从预训练权重进行初始化训练时,该模型位于损失函数 “地图” 的同一 “盆地”(basin)中,不同实例在特征空间中相似,并且在参数空间中接近(注:basin 一词在该领域文献中经常使用,指代参数空间中损失函数相对较低值的区域)。
迁移学习应用现状
前百度首席科学家吴恩达(Andrew Ng)曾经说过:迁移学习将会是继监督学习之后,下一个机器学习商业成功的驱动力。
在 2016 年的 NIPS 会议上,吴恩达曾给出了一个未来 AI 方向的技术发展判断:毋庸置疑,目前成熟度最高、成功商用的是监督学习,紧随其后,下一个近 5 年内最可能走向商用的 AI 技术将会是迁移学习。
DeepMind 首席执行官 Demis Hassabis 也曾表示,迁移学习也是最有前途的技术之一,有朝一日可能会触发通用人工智能的诞生(AGI)。在当下深度学习的发展大潮中看来,迁移学习确实如此。
如今距离这两位 AI 学者的 “预测” 已经过去了近 5 年。那么,目前迁移学习应用正呈现怎样的局面?
在计算机视觉领域,迁移学习已经有了很多成功的应用,甚至在一些任务中,机器能以超越人类精确度的水平完成某项任务。
而在 NLP 领域,迁移学习也是一系列研究突破中的关键组成部分,尤其在跨域情感分析上展现了其潜力。
与此同时,迁移学习所存在的问题也随之暴露。研究人员发现,某些案例中,源域和目标域之间在视觉形式上仍存在不小的差异。对于研究人员而言,已经很难理解什么能够成功进行迁移,以及网络的哪些部分对此负责。在这篇论文中,研究团队专注于研究视觉领域的迁移学习。
文中涉及的两大数据集分别是:
CheXpert 数据集,这是在 2019 年 AAAI 上,吴恩达的斯坦福团队发布的大型 X 射线数据集,此数据集考虑到了不同疾病的胸部 X 射线医学影像,它包含 65,240 位病人的 224,316 张标注好的胸部 X 光片以及放射科医师为每张胸片写的病理报告;
DomainNet 数据集,该数据集发布在 2019 年 ICCV 上,此论文作者收集并注释了迄今为止最大的 UDA 数据集,专门用于探究不同领域中的迁移学习。其中存在显著的领域差异和大量的类别划分,包含 6 个域和分布在 345 个类别中的近 60 万幅图像,范围从真实图像到草图,剪贴画和绘画样本,解决了多源 UDA 研究在数据可用性方面的差距。
4 种网络的迁移学习
他们分析了四种不同情况下的网络:
1. 预训练网络(P, pre-trained model);
2. 随机初始化的网络(RI, random initialization);
3. 在源域上进行预训练后在目标域上进行微调的网络(P-T, model trained/fine-tuned on target domain starting from pre-trained weights);
4. 随机初始化对目标域进行普通训练的模型(RI-T, model trained on target domain from random initialization)。
首先,团队通过改组数据研究了特征复用。将下游任务的图像划分为相同大小的块并随机排序,数据中的块混洗破坏了图像的视觉特征。该分析表明了特征复用的重要性,并证明了不受像素混洗干扰的低级统计数据在成功传输中也起作用。
然后,需要比较经过训练的模型的详细行为。为此,他们调查了从预训练和从零开始训练的模型两者间的异同。实验证明,与通过随机初始化训练的模型相比,使用预训练的权重训练的模型的两个实例在特征空间上更为相似。
再就是调查了预训练权重和随机初始化权重训练的模型的损失情况,并观察到从预训练权重训练的两个模型实例之间没有性能降低,这表明预训练权重能够将优化引导到损失函数的 basin。
接下来,我们结合文章中的实验和结果来详细的分析方法论并探讨 “What is being transferred?”。
什么被迁移了?
人类视觉系统的组成具有层次化的特征,视觉皮层中的神经元对边缘等低级特征做出响应,而上层的神经元对复杂的语义输入进行响应。一般认为,迁移学习的优势来自重用预先训练的特征层。如果下游任务因为太小或不够多样化而无法学习良好的特征表示时,这会变得特别有用。
因此,很容易理解,大家认为迁移学习有用的直觉思维就是,迁移学习通过特征复用来给样本少的数据提供一个较好的特征先验。
然而,这种直觉却无法解释为什么在迁移学习的许多成功应用中,目标领域和源领域在视觉上差异很大的问题。

图 1 。图片出处:arXiv
为了更清楚地描述特征复用的作用,作者使用了图 1 中包含自然图像(ImageNet)的源域(预训练)和一些与自然图像的视觉相似度低的目标域(下游任务)。
图 2 可以看到,real domain 具有最大的性能提升,因为该域包含与 ImageNet 共享相似视觉特征的自然图像。这能够支撑团队成员的假设 —— 特征复用在迁移学习中起着重要作用。另一方面,在数据差别特别大的时候(CheXpert 和 quickdraw),仍然可以观察到迁移学习带来的明显的性能提升。

除最终性能外,在所有情况下,P-T 的优化收敛速度都比 RI-T 快得多。这也暗示出预训练权重在迁移学习中的优势并非直接来自特征复用。
为了进一步验证该假设,团队修改了下游任务,使其与正常视觉域的距离进一步拉大,尤其是将下游任务的图像划分为相等大小的块并随机排序。
混洗扰乱了那些图像中的高级视觉功能,模型只能抓住浅层特征,而抽象特征没法很好地被提取。
其中,块大小 224*224 的极端情况意味着不进行混洗;在另一种极端情况下,图像中的所有像素都将被混洗,从而使得在预训练中学到的任何视觉特征完全无用。
在本文中,团队成员创造出了一种特殊情况,每个通道的像素都可以独立的移动,并且可以移动到其他通道中。
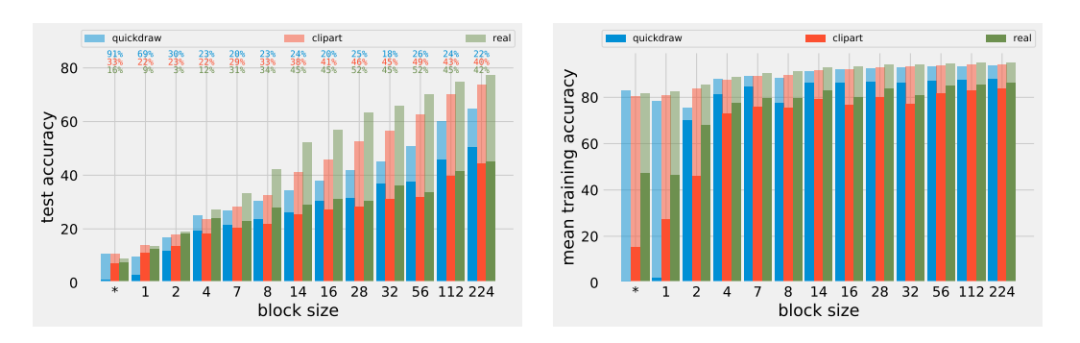
图 3 。图片出处:arXiv
图 3 显示了不同块大小对最终性能和优化速度的影响。我们可以观察到以下几点:
随着打乱程度的加剧,RI-T 和 P-T 的最终性能都会下降,任务越发困难;
相对精度差异随块尺寸(clipart, real)的减小而减小,说明特征复用很有效果;
quickdraw 上情况相反是由于其数据集和预训练的数据集相差过大,但是即便如此,在 quickdraw 上预训练还是有效的,说明存在除了特征复用以外的因素;
P-T 的优化速度相对稳定,而 RI-T 的优化速度随着块尺寸的减小时存在急剧的下降。这表明特征复用并不是影响 P-T 训练速度的主要因素。
由上述实验得出结论,特征复用在迁移学习中起着非常重要的作用,尤其是当下游任务与预训练域共享相似的视觉特征时。但是仍存在其他因素,例如低级别的统计信息,可能会带来迁移学习的显着优势,尤其是在优化速度方面。
失误和特征相似性
这部分主要通过探究不同模型有哪些 common mistakes 和 uncommon mistakes 来揭示预训练的作用。
为了理解不同模型之间的差异,作者首先比较两个 P-T,一个 P-T 加一个 RI-T 和两个 RI-T 之间的两类错误率并发现 P-T 和 RI-T 模型之间存在许多 uncommon mistakes,而两个 P-T 的 uncommon mistakes 则要少得多。对于 CheXpert 和 DomainNet 目标域,都是这种情况。
在 DomainNet 上可视化每个模型的两类错误并观察得到,P-T 不正确和 RI-T 正确的数据样本主要包括模棱两可的例子;而 P-T 是正确的数据样本和 RI-T 是不正确的数据样本也包括许多简单样本。
这符合假设,P-T 在简单样本上的成功率很高,而在比较模糊难以判断的样本上比较难 (而此时 RI-T 往往比较好), 说明 P-T 有着很强的先验知识,因此很难适应目标域。
为了加强对上述想法的验证,团队成员又对特征空间中两个网络的相似性进行了研究。
通过中心核对齐 (CKA, Centered Kernel Alignment) 这一指标发现,P-T 的两个实例在不同层之间非常相似,在 P-T 和 P 之间也是如此。但是 P-T 和 RI-T 实例或两个 RI-T 实例之间,相似性非常低。
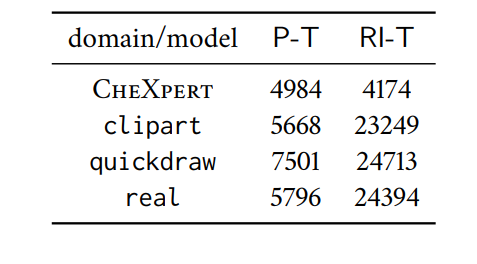
表 2 。图片出处:arXiv
也就是说,基于预训练的模型之间的特征相似度很高,而 RI-T 与其他模型相似度很低,哪怕是两个相同初始化的 RI-T。这显然在说明预训练模型之间往往是在重复利用相同的特征,也就强调了特征复用的作用。表 2 为不同模型的参数的距离,同样能够反映出上述结论。
泛化性能
更好度量泛化性能的常用标准,是研究在最终解决方案附近的损失函数里 basin 程度。
作者用Θ和Θ̃表示两个不同检查点的所有权重,通过两个权重的线性插值{Θ휆=(1-λ)Θ+λΘ̃:λϵ[0,1]} 评估一系列模型的表现。
由于神经网络的非线性和组成结构,两个性能良好的模型权重的线性组合不一定能定义效果良好的模型,因此通常会沿线性插值路径预期到性能降低。
但是,当两个解属于损失函数的同一 basin 时,线性插值仍保留在 basin 中,此时的结果是,不存在性能障碍。此外,对来自同一 basin 的两个随机解进行插值通常可以产生更接近 basin 中心的解,这可能比端点具有更好的泛化性能。
团队将重点放在凸包(convex hull)和线性插值上,以避免产生琐碎的连通性结果。需要强调的是,要求 basin 上的大多数点的凸组合也都在 basin 上,这种额外的约束使得通过低损耗(非线性)路径连接或不连接多个 basin。
此概念的具体形式化以及将凸集设置为 basin 的三点要求论文中均给出了详细说明,在此便不再赘述。
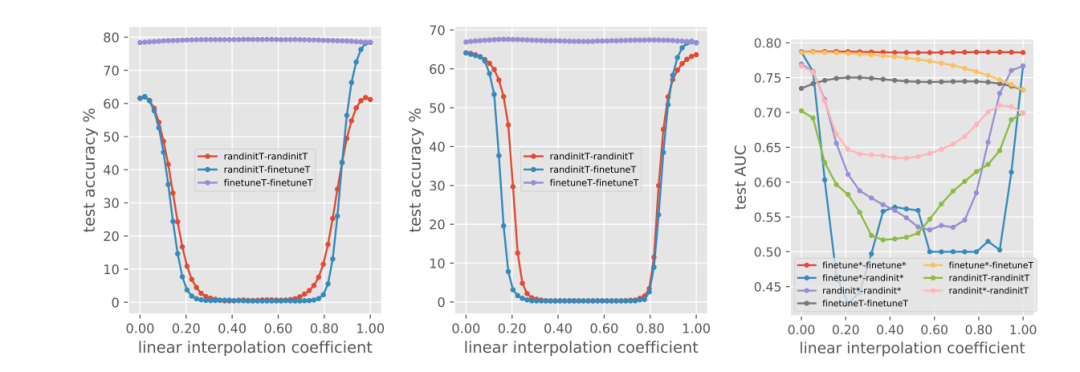
图 4 中所显示出的插值结果,左为 DomainNet real, 右为 quickdraw。图片出处:arXiv
一方面,两次随机运行的 P-T 解决方案之间没有观察到性能降低,这表明预训练的权重将优化引导到了损失函数的 basin。另一方面,在两个 RI-T 运行的解决方案之间清楚地观察到了障碍。可见预训练模型之间的损失函数是很光滑的,不同于 RI-T。
模块重要度
如果我们将训练好的模型的某一层参数替换为其初始参数,然后观察替换前后的正确率就能一定程度上判断这个层在整个网络中的重要性,那么,模块重要度就是一个这样的类似的指标。
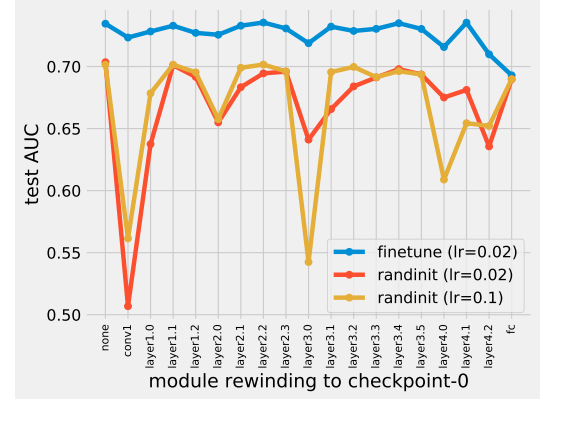
图5。图片出处:arXiv
图 5 反映了不同模块不同层的重要度。在监督学习案例中也有类似的模式。唯一的区别可能是,“FC” 层对于 P-T 模型的重要性是可预料的。
接下来,作者使用扩展定义以及原始定义来研究不同模块的重要度。很容易可以注意到,优化和直接路径都为模块的重要度提供了有趣的见解。或许,与最终值相比,权重的最佳值是进行此分析的更好的起点选择。
而图 6 显示了对 “ Conv1” 模块的分析,正如图 5 所示,这是一个关键模块。
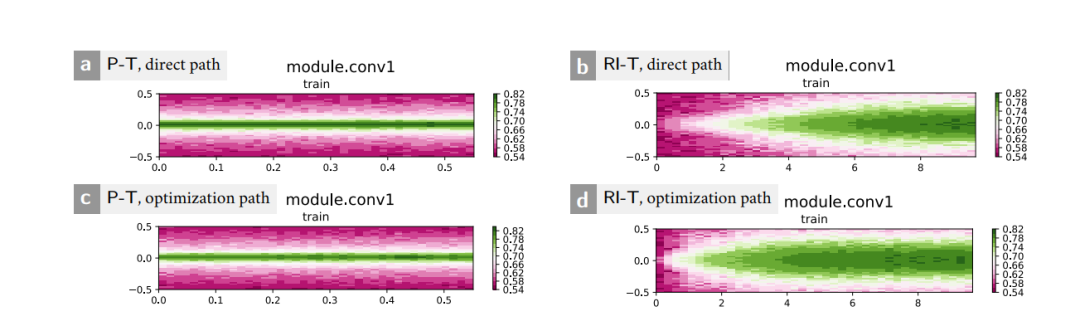
图6。图片出处:arXiv
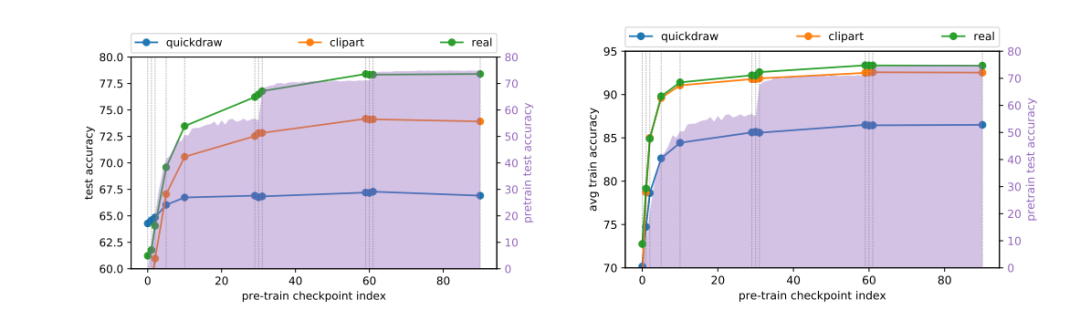
图7。图片出处:arXiv
通过初始化来自预训练优化路径上不同检查点的预训练权重,比较迁移学习的好处。图 7 显示了从不同的预训练检查点进行微调时的最终性能和优化速度。
总体而言,预训练的好处随着检查点指数的增加而增加,可得出以下结论:
在预训练中,在学习率下降的 epoch 30 和 epoch 60 观察到了很大的性能提升。但是,从检查点 29、30、31(和类似的 59、60、61)初始化不会显示出明显不同的影响。另一方面,特别是对于 real 和 clipart 的最终性能,当从训练前性能一直处于平稳状态的检查点(如检查点 29 和 59)开始时,可以观察到显着的改进。这表明,预训练性能并不总是作为预训练权重对迁移学习有效性的忠实指标。
quickdraw 在预训练中发现最终性能的收益要小得多,并在检查点 10 迅速达到平稳状态,而 real 和 clipart 直到检查点 60 都不断看到的性能的显著改进。另一方面,随着检查点索引的增加,所有三个任务在优化速度改进上均具有明显的优势。
优化速度在检查点 10 处开始达到平稳状态,而对于 real 和 clipart,最终结果则不断提升。在训练前的早期检查点是在收敛模型的 basin 之外,在训练期间的某个点便进入 basin。这也解释了在一些检查点之后性能停滞不前的原因。
因此,我们可以早一步地选取检查点,这样便不会损失微调模型的准确性。这种现象的起点取决于预训练模型何时进入其最终 basin。
总而言之,这项研究明确阐述了迁移学习中所迁移的内容以及网络的哪些部分正在发挥作用。
对于成功的迁移,数据的特征复用和底层统计都非常重要。通过对输入块进行混洗来研究特征重用的作用,表明当从预训练权重初始化进行训练时,网络停留在解决方案的同一 basin 中,特征相似并且模型在参数空间中的距离附近。
作者还进一步确认了,较低的层负责更一般的功能,较高层的模块对参数的扰动更敏感。通过对损失函数 basin 的发现可用于改进集成方法,对低级数据统计数据的观察提高了训练速度,这可能会导致更好的网络初始化方法。利用这些发现来改善迁移学习,将十分具有价值。