经过六十余年的发展,人工智能(AI)及 机器学习(ML)已经成为新一轮产业变革的核心驱动力,其发展趋势也成为全球关注焦点。
虽然目前 AI / ML 尚处于产业发展的早期,其技术产品固然方兴未艾,但对于普罗大众而言,复杂的算法、模型、背后高深的数学逻辑等都过于“遥不可及”,更不用说这些复杂的理论逻辑还要通过最前沿的计算机技术来进行高速实现。
AI 是炫酷的,ML 是高深的,但这一切的实现,最终都是由开发者们一手一脚搭建起来。作为原生的互联网公司,一直以来 Amazon Web Services(AWS)都以产品对开发者友好为特征,对全球的开发者提供各类资源与支持,并通过各种渠道等多方位的形式持续沟通交流。
那么在这个数据横流的世界,AWS 是如何将 ML 送到每位开发者和 BI 分析师手中的呢?
利器的打造
AWS 坚信,在不久的未来,每个应用程序均会融入 ML 和AI 。
AWS 努力,让 ML 成为每个开发人员的利器,让您更轻松地运用尖端的 ML 服务,以帮助您提升业绩。
数万客户可通过 Amazon SageMaker 享受 ML 带来的好处。仅需在您的结构化查询语言 (SQL) 中添加一些语句,在 Amazon QuickSight 中进行几次点击,即能轻松使用您的 Amazon Aurora 数据库中的关系型数据或 Amazon S3 中的非结构化数据,为应用程序和商业智能 (BI) 控制面板添加ML预测。Aurora、Amazon Athena 和 Amazon QuickSight 可以直接调用 Amazon SageMaker 和 Amazon Comprehend 等 AWS ML 服务,因此您无需从自己的应用程序中调用它们。这使得您可以以更直接的方式向应用程序添加 ML 预测,无需构建定制集成,来回复制数据,学习多种独立工具,编写多行复杂代码等等,甚至无需具备 ML 经验。
这些新的特性允许通过 SQL 查询和控制面板执行尖端的ML 预测,从而使 ML 变得更加实用,更方便数据库开发人员和商业分析师使用。在以前,您可能会耗费多日编写应用程序中定制代码,并需要考虑在生产环境中扩展、管理和支持。而现在,任何具备编写 SQL 能力的人,都可以在没有任何定制的“胶合代码”的情况下,在应用程序中构建和使用 ML 预测。
利器的运用
自从出现互联网以后,数据的体量、增速和类型就不断地增加。很多企业面临的问题在于,如何管理并理解此“大数据”以得到最理想的回报。
企业内部的竖井、持续产生各种格式的数据和不断变化的技术面貌让收集、存储、分享,以及对数据进行分析和可视化变得困难重重。
数据湖是一种集中的存储库,它可以存储任何规模的各种结构化和非结构化数据。更好的安全性、更快的部署;更好的可用性、更频繁的特性/功能更新;更具弹性、更广的地理覆盖范围,以及与实际利用率相关的成本,让数据湖成功为企业创造高额商业价值。今天,小编就要来教你如何使用 Amazon EMR、Amazon SageMaker 和 AWS Service Catalog 设置 Intuit 数据湖。
1.架构
账户结构
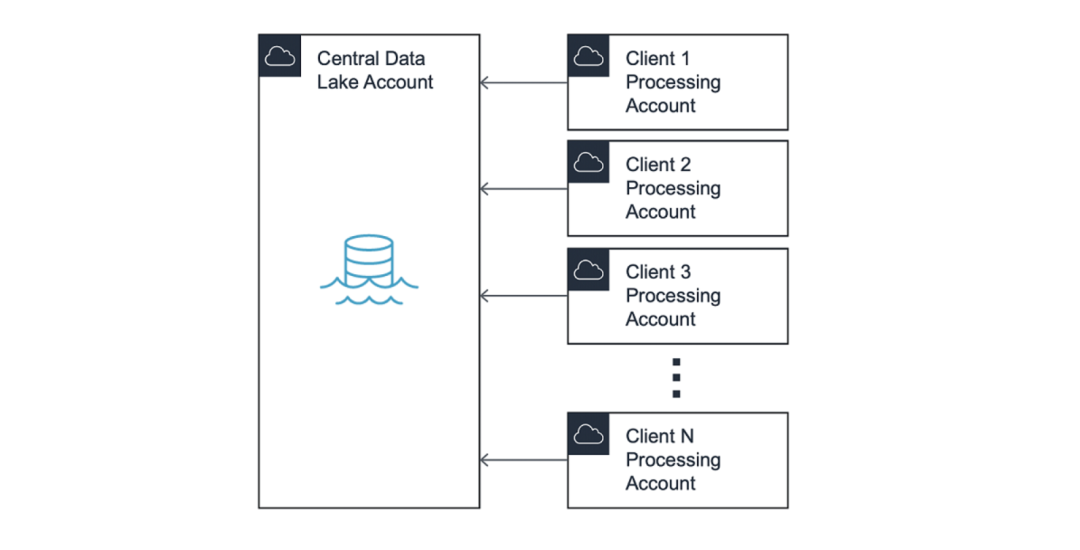
数据湖通常采用hub-and-spoke模型,其中中心账户包含控制数据源访问权限的共享服务。在本文中,我们将hub账户称作中央数据湖(Central Data Lake)。
在此模式中,访问中央数据湖的权限被分配给名为“处理账户”(Processing Accounts)的spoke账户。此模型保持了最终用户之间的隔离,并允许在不同业务部门之间的划分账单。
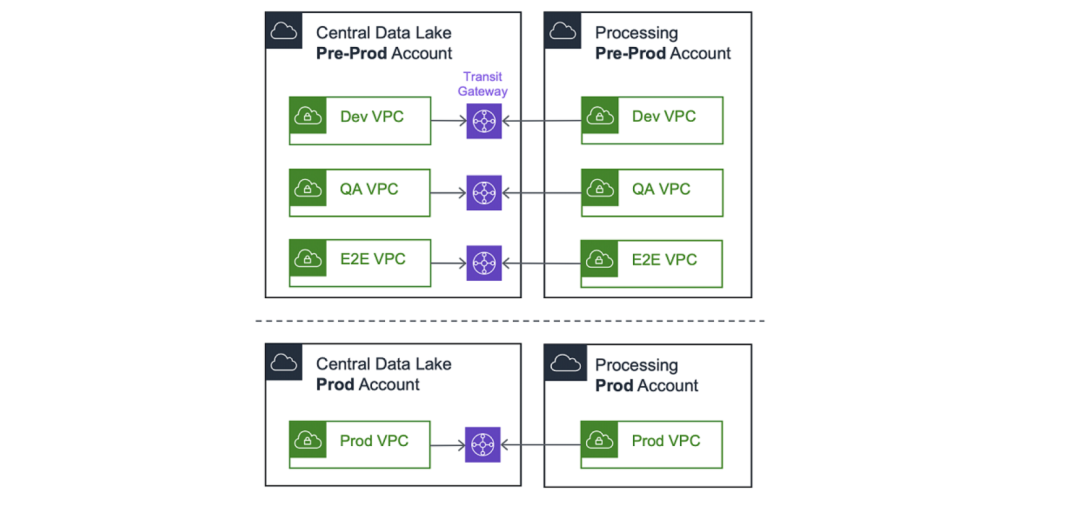
维护两个生态系统的情况十分常见:分别为预生产 (Pre-Prod) 和生产 (Prod)。通过阻止 预生产和生产之间的连接,数据湖管理员可以对数据进行单独访问。
为了进行实验和测试,建议在预生产账户内维护基于独立VPC 的环境,如 dev、qa 和 e2e。然后,处理账户 VPC 将连接到中央数据湖中的对应 VPC。
请注意,首先,我们使用 VPC对等连接连接账户。但随着扩展,我们很快就会达到 125 个 VPC 对等连接的硬性限制,这使得我们迁移至 AWS Transit Gateway。在撰写这篇博文时,我们每周都会连接多个新的处理账户。
2.中央数据湖
在 hub 账户中可能运行着很多服务,但我们将重点关注与本博文最密切相关的几个方面:摄入、清理、存储和数据目录。
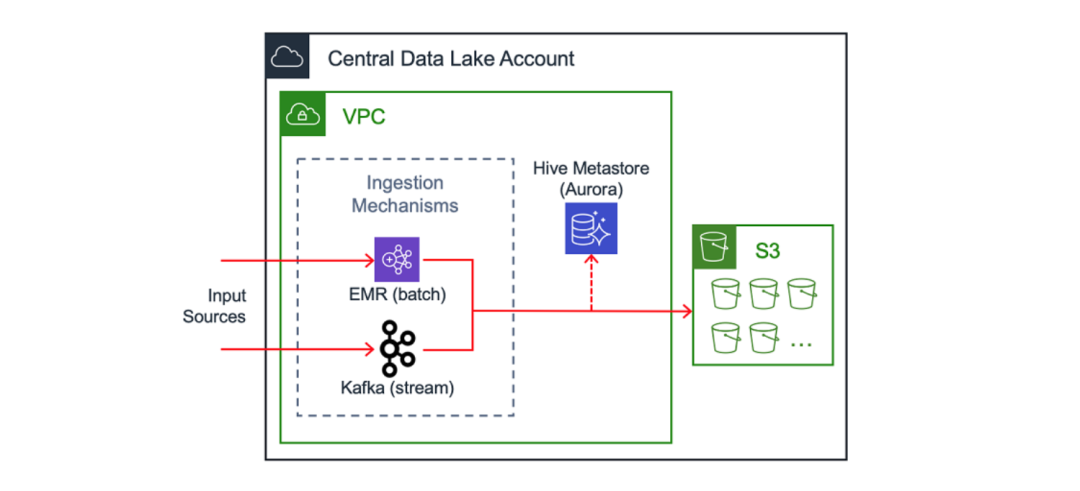
摄入、清理和存储
中央数据湖的关键组成部分是对流式数据的统一摄入模式。一种示例的实现方式是在 Amazon EC2 上运行的 Apache Kafka 集群。(您可以阅读另一篇 AWS 博客了解 Intuit 工程师在这方面的实现方式) 在处理数百个数据源时,我们已启用通过 AWS PrivateLink 访问摄入机制的功能。
注意:Amazon Managed Streaming for Apache Kafka (Amazon MSK) 是在 Amazon EC2 上运行 Apache Kafka 的替代方式,但在Intuit 迁移开始时该服务还没有发布。
除了流处理之外,另一种摄入方式是批处理,例如在 Amazon EMR 上运行的作业。在使用这些方式摄取数据后,可以将其存储在 Amazon S3 中进行进一步的处理与分析。
Intuit 处理大量客户数据,并且仔细考虑每个字段,并按照敏感级别对其进行分类。所有进入数据湖的敏感数据在源头就被加密。提取系统会检索加密数据,并将其移入数据湖。在将数据写入 S3 之前,使用专有的 RESTful 服务对此类数据进行清理。在数据湖中执行操作的分析师和工程师会使用这些屏蔽数据。
数据目录
数据目录是为最终用户提供关于数据及其所在位置信息的常见方式。其中一个示例是由 Amazon Aurora 提供支持的 Hive Metastore 。另一个替代方式是 AWS Glue 数据目录
3.处理账户
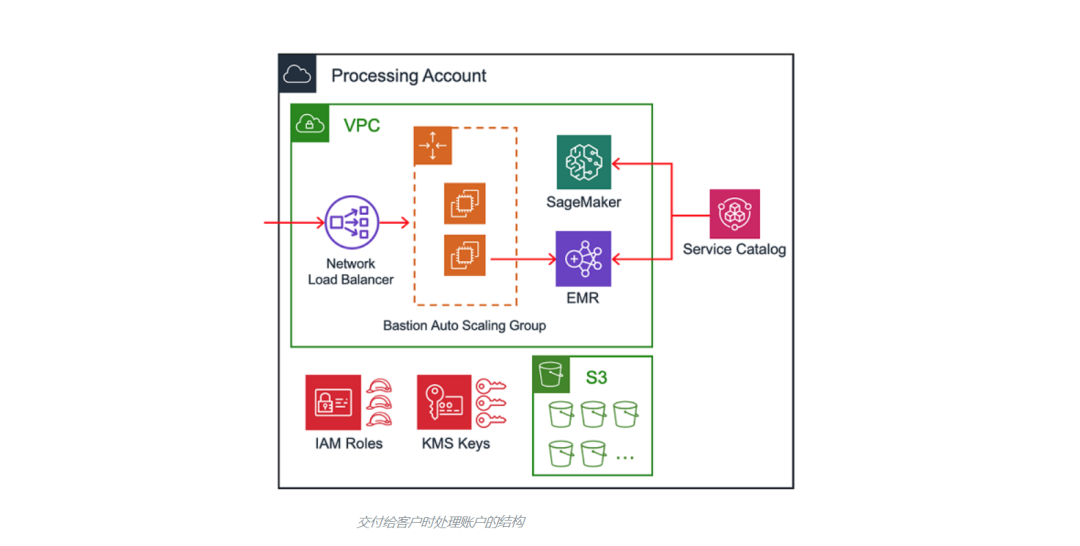
当处理账户被交付给最终用户时,它们包含一系列相同的资源。我们将在下文讨论处理账户的自动化,但主要的组成部分如下:
- 通过 Transit Gateway 连接到中央数据湖
- 用于通过SSH访问 Amazon EMR 集群的堡垒主机
- IAM 角色、S3 存储桶和 AWS Key Management Services (KMS) 密钥
- 使用配置管理工具的安全框架
- 支持对 Amazon EMR 和 Amazon SageMaker 进行预置的 AWS Service Catalog 产品
4.数据存储机制
一个合理的问题是,是否所有数据都应该存储在中央数据湖吗,或者在多个账户分布数据是否可被接受?数据湖可以同时采用两种方法的组合,并将数据位置分类为主要或次要。
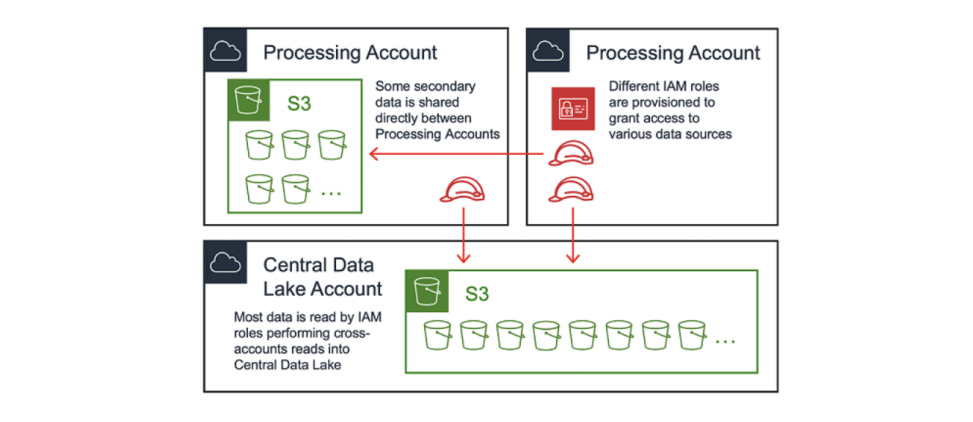
中央数据湖是数据的主要位置,数据通过上文讨论过的摄入管道被传送到这里。处理账户可以通过直接从摄入管道或从 S3 对主要源进行读取。处理账户可以将经其转换后的数据重新贡献到(主要)中央数据湖,或将其存储于自己的账户(次要)。正确的存储位置取决于数据的类型,以及需要用到这些数据的使用者。
不允许跨账户写入是一条应该被执行的规则。换句话说就是,IAM 主体(在大多数情况下为,由 EC2 通过实例配置文件代入的 IAM 角色)必须和目标 S3 存储桶属于相同的账户。这是因为不支持跨账户授权—具体来说,中央数据湖中的 S3 存储桶政策无法授予处理账户 A 访问由处理账户 B 中的角色写入对象的权限。
另一种可能是,由 EMR 通过自定义凭证提供者代入不同的 IAM 角色(参见 AWS 博客),但我们没有选择这条路线,因为Intuit需要重写很多 EMR 作业。
5.数据访问模式
大多数最终用户都需要访问位于 S3 中的数据。在中央数据湖和部分处理账户中,可能存在一系列只读 S3 存储桶:数据湖生态系统中的任何账户都可以从此类型存储桶中读取数据。
为了简化对只读存储桶的S3 访问管理,我们构建了一种控制 S3 存储桶政策的机制,这种机制完全通过代码进行管理。我们的部署管道采用账户元数据以基于账户的类型(Pre-Prod 或 Prod)动态生成正确的 S3 存储桶政策。这些政策会被提交回我们的代码存储库,以实现可审计性并且易于管理。
我们利用相同的方法管理 KMS 密钥策略,因为我们使用 KMS 和客户管理的客户主密钥 (CMK) 对S3 中的数据进行静态加密。
如下是为只读存储桶生成的 S3 存储桶策略的示例:
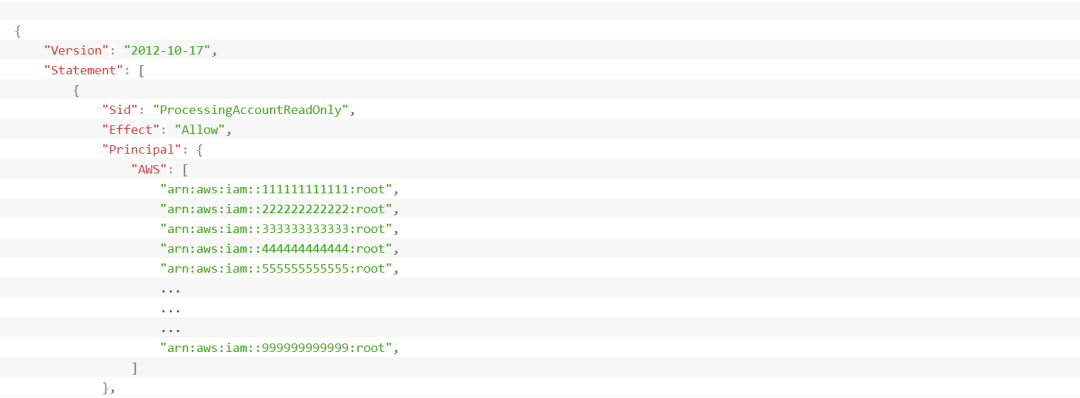
请注意,我们会在账户级别授予访问权限,而不是使用显式的 IAM 主体 ARN。因为读取是跨账户的,所以处理账户中的 IAM 主体也需要权限。在这种粒度级别上对此类策略进行自动化维护不大可行。此外,使用特定的 IAM 主体 ARN 可能对外部账户产生外部依赖关系。 例如,如果处理账户删除了在中央数据湖的 S3 存储桶策略中引用的 IAM 角色,将无法再保存存储桶策略,从而导致部署管道的中断。
6.安全性
对于任何数据湖来说,安全性都是至关重要的。 我们将提到所使用控件的子集,但不会做深入讨论。
加密
可以通过多种方式在传输时和静态进行强制加密:
- 数据湖中的流量应使用最新版本的 TLS(在写作本文时是 1.2)
- 数据可以使用应用程序级(客户端)加密进行加密
- KMS 密钥可被用于 S3、EBS 和 RDS 的静态加密
入栈和出栈
我们为入栈和出栈采取的方法并不特殊,非常值得一提的是,我们发现重要的标准模式:
- 将堡垒主机和安全组配合使用, 将 SSH 流量限制在适当的 CIDR 范围
- 通过网络访问控制列表 (ACL) 避免多余的的数据传入
- 通过 VPC 终端节点将访问路由到 S3 存储桶,以避免其通过公共互联网
限制入栈和出栈的策略是数据湖可以保证质量(入栈)并防止数据丢失(出栈)的主要方面。
授权
通过 IAM 角色控制对 Intuit 数据湖的访问,这意味着不会创建任何(具有长期凭证的)IAM 用户。最终用户会通过内部服务被授予访问权限,而该内部服务则对基于角色的 AWS 账户联合访问进行管理。定期进行审核,以删除不必要的用户。
配置管理
我们使用 Cloud Custodian 的内部分支,它是一整套预防、检测和响应式控件,由 Amazon CloudWatch Events 和 AWS Config 规则组成。它会报告并(可选)缓解的一些违规行为包括:
- 入站安全组规则中的未经授权 CIDR
- 公有 S3 存储桶策略和 ACL
- IAM 用户控制台访问
- 未加密的 S3 存储桶、EBS 卷和 RDS 实例
最后,所有 Intuit 数据湖账户中都会启用 Amazon GuardDuty,并由 Intuit Security 加以监控。
7.自动化
如果说我们在构建 Intuit 数据湖时有什么收获的话,那就是要对一切进行自动化。
在本博文中,我们将讨论四个领域的自动化:
- 创建处理账户
- 处理账户编排管道
- 处理账户 Terraform 管道
- 通过 Service Catalog 进行 EMR 和 SageMaker 部署
创建处理账户
创建处理账户的第一步是通过内部工具发起请求。这会触发自动化,对正确业务部门下带有 Intuit 标记的 AWS 账户进行设置。
注意:AWS Control Tower 的账户工厂在我们刚开始这段旅程时还没有发布。但您可以利用它以安全、符合最佳实践的自助式方式对新的 AWS 账户进行设置。
账户设置还包括自动化的 VPC 创建(带有可选 虚拟专用网络),以及使用 Service Catalog 实现完全自动化。最终用户只需指定子网大小即可。
另外值得一提的是,Intuit 可利用 Service Catalog 自助部署其他常见的模式,包括入栈安全组、VPC 终端节点和 VPC 对等连接。以下是一个示例产品组合:

处理账户编排管道
在创建账户并对 VPC 进行设置后,处理账户编排管道将会运行。此管道会执行处理账户所需的一次性任务。这些任务包括:
- 引导IAM 角色以用于进一步的配置管理
- 为 S3、EBS 和 RDS创建 KMS 加密密钥
- 为新账户创建变量文件
- 使用账户元数据更新主配置文件
- 生成脚本以编排下文要讨论的 Terraform 管道
- 通过 Resource Access Manager 分享 Transit Gateway
处理账户 Terraform 管道
该管道管理动态且经常更新的资源的生命周期,包括 IAM 角色、S3 存储桶和存储桶策略、KMS 密钥策略、安全组、NACL 以及堡垒主机。
每个处理账户都有一条管道,而且每条管道都会使用一组参数化部署作业在账户中部署一系列层。层是 Terraform 模块和 AWS 资源的逻辑分组,在需要重新部署特定资源时提供一种方式以缩小 Terraform 状态文件和爆炸半径。
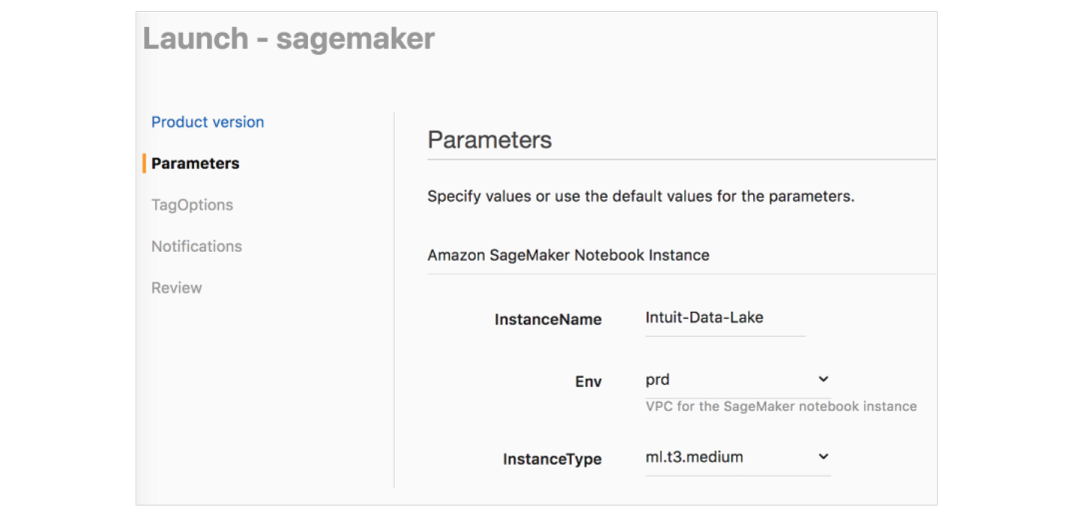
通过 Service Catalog 进行 EMR 和 SageMaker 部署
AWS Service Catalog 简化了Amazon EMR 和 Amazon SageMaker 的设置,允许最终用户通过嵌入式安全方式启动 即用型EMR 集群和的 SageMaker Notebook实例。
Service Catalog 让数据科学家和数据工程师可以采用自助式方式和用户友好的参数启动 EMR 集群,并为他们提供以下各项服务:
- 引导操作,以便与中央数据湖中的服务实现连接
- EC2 实例配置文件,以控制 S3、KMS 和其他细粒度权限
- 可启用静态和传输时加密的安全配置
- 配置分类,以实现最佳 EMR 性能
- 启用监控与日志记录的加密 AMI
- 自定义 Kerberos 连接至 LDAP
对于 SageMaker,我们使用 Service Catalog 以启动具有生命周期配置的Notebook实例,以设置连接或初始化以下各项:Hive Metastore、Kerberos、安全性、Splunk 日志记录和 OpenDNS。您可以参考该 AWS 博文,以了解关于生命周期配置的更多信息。启动具有最佳实践配置的 SageMaker Notebook实例非常简单,具体方式如下: