机器学习是什么?给你十秒钟,请给出答案。
……
不知道?就这你还想从事人工智能行业?得了吧!
听着:机器学习使用数据中的模式来标记事物。
听起来是不是很神奇?
......
好了,就此打住。
机器学习的核心概念其实非常简单,简单到让人“尴尬”。
这里说的“尴尬”是指,如果有人在你面前“装逼”,让你觉得机器学习很神奇,他们应该感到尴尬。为什么呢?且看这篇“反装逼”指南。
这篇指南的作者是Cassie Kozyrkov,谷歌的首席决策情报工程师,不仅人美,心也善。经常在Hacker Noon上发表一些与人工智能相关的干货文章。
在这篇指南中,她使用的例子是葡萄酒。她还很贴心地提到,如果你不喜欢喝葡萄酒,也可以把葡萄酒脑补成任何你喜欢喝的饮品,比如茶。
好了,废话不多说,让我们搬起小板凳,进入正题吧~
机器学习到底是如何工作的?
机器学习并不是魔法,没有数据是不可能学习的,所以想要完成这个类比,必须要喝一些葡萄酒。
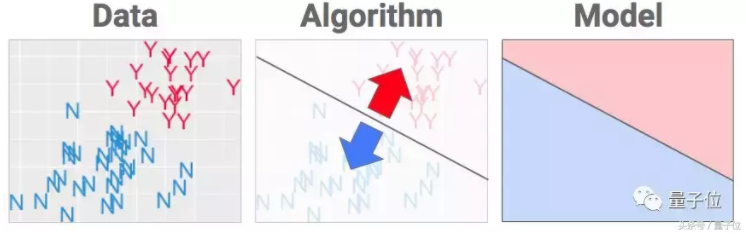
数据
为了学习,需要有献身精神。大家可以体会下,一口气喝了50种葡萄酒是种什么感受。关键是喝完酒还不算完,我还要处理这些信息,并把它们可视化,以便在下面观看。
每一种葡萄酒都有相应的年份,品尝完了之后要打个分,然后给出一个判断。这个判断,也就是我们希望人工智能之后能够自己做出的判断:Y代表好喝,N代表不好喝。
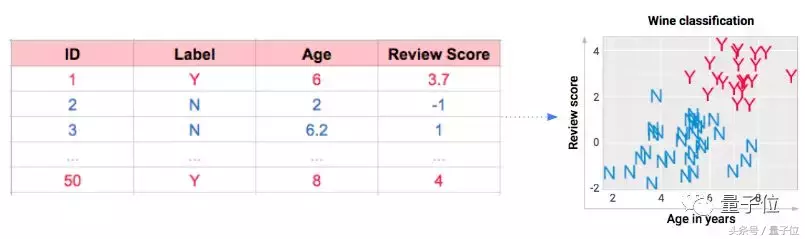
相关的数据都记录在了电子表格中(左),但是为了让大家看得舒服,我把所有的数据都可视化了(右)。
算法
接下来,就要进行下一件事情了。把红色区域和蓝色区域分开,你能做到吗?机器学习就是要选择一种算法来完成这个过程,选了哪个算法,就决定了最后会得到哪种模型。
如果你想着划一条线来完成这项工作的话,那恭喜你!你刚刚发明了一种机器学习算法,它的名字叫……感知器(perceptron)。是的,就是这么高大上,它的名字就是这么酷炫。请不要被机器学习中的“行话”吓倒,通常情况下都是大忽悠。
但是,你划的线应该指向哪里呢?我们的目标是把Y和N分开,划一条直线并不是一个非常聪明的解决方案。
我们选择一种机器学习算法的目的,是为了找到最合理的地方划出分界线。这需要通过优化目标函数来完成。
优化
你可以这样想:目标函数就像是棋盘游戏的规则一样,优化就是找到一个能够获得高分的玩法。
从传统上来说,在机器学习中,我们更喜欢“棍棒”而不是“胡萝卜”。也就是对错误进行计分。这就是为什么机器学习中的目标函数被称为“损失函数”,目的就是要尽量减少损失。
想亲自玩一把吗?回到上面的那张图,用你的手指在屏幕上划线把Y和N分开,直到零失误。感知器同志,感觉到未来触手可及了吗?
也许,你得到的解决方案是这样的:
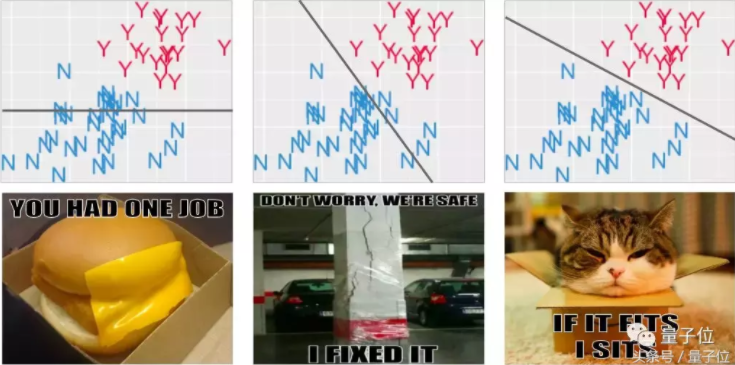
最左边的这种结果,我没有尝试过。中间的那个也不太合适。我最喜欢的是最右边那个。
算法是具有多样性的,它们之间最不同的一个方面,就是它们怎么去确定分界线。
痴迷于优化的那群人会告诉你,以微小的增量调整分界线是不明智的,还有更好、更快的方法来找到最佳位置。一些研究人员致力于花一辈子的时间找出一种方法,不管数据多复杂,都能最简单地找到最好的分界线位置。
算法的另一个不同的方面是边线的形状。边界线不一定是直的。不同的算法,使用的边界线形状也不同。如下图:
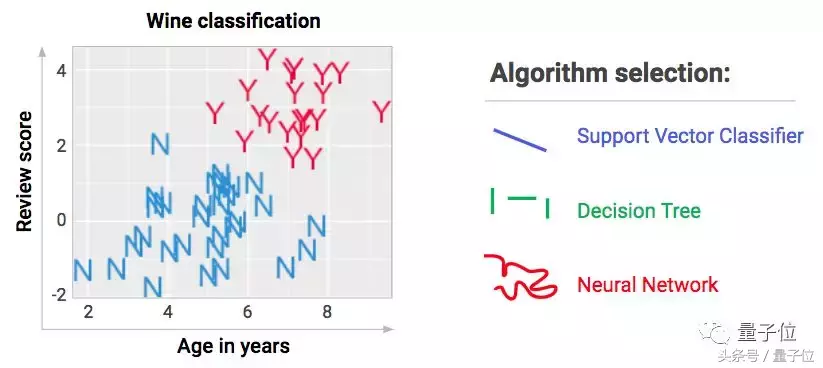
为追赶潮流的人设计的算法
如今,没有一个追赶数据科学浪潮的人会选择用直线来区分。那些看上去很灵活、很弯曲的线在他们之中非常流行。他们会使用其实并没有多少神经的神经网络算法。我更倾向于称它们为“瑜伽网络”或者是“多层数学运算”,但好像没有人喜欢我的这种叫法。
不同的算法会告诉你,它们会在数据中放置什么形状的边界线。但如果你是一个应用型的机器学习爱好者,记不住它们那种天书般的名字也没关系——在实践中,你只需要尽可能多地将数据输入到算法中,然后重复执行那些看起来很有希望的事情就行了。
模型
一旦边界线划好了,算法也就完成了,你就能从中得到你想要的东西了:一个模型。在下一次我给它“看”一瓶新的葡萄酒的时候,它就能将数据转换成决定。
标签
一旦你把新鲜出炉的模型投入使用,在计算机中输入葡萄酒的年份和评价分数后,你的模型会给它找出对应的区域并输出标签。
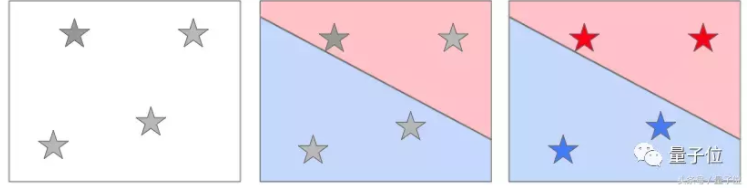
那问题来了,我们如何知道它是否有效呢?谁知道这是不是瞎搞?最直接的办法就是对输出进行检查。
通过运行一堆新数据来测试你的模型,并确保它能够一直能够良好的运行。事实上,无论模型是算法想出来的还是程序员想出来,都要这样做。
结语
在我此前的另一篇文章中,我对整个过程进行了一个类比:
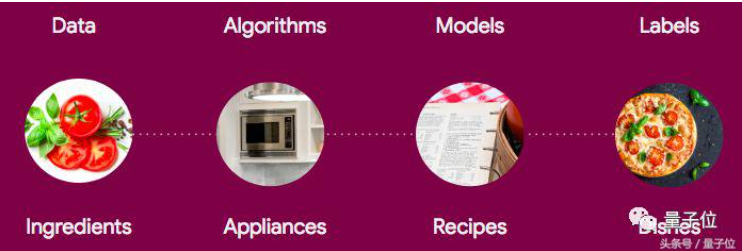
诗人与机器学习
如果你看不懂这个类比,也许你会喜欢这个:诗人会选择一种方法(算法),将文字写在纸上。这种方法决定了诗歌的形式(边界线形状)是俳句还是十四行诗?一旦他们以最佳的方式完成了十四行诗,它现在就是一首诗(模型)。
机器学习模型与传统的编程
但是,以这种方式得到的模型,与程序员通过观察问题,并手动制定一些规则来编写的代码没有太大的不同。二者在概念上是相同的。
不要到处说机器学习的“再训练”(retraining)有多厉害了。程序员也可以坐在那里调整代码以响应新的信息。
这就是全部了吗?
是的,差不多了。机器学习工程中最困难的部分就是安装软件包,接着就是处理数据集,然后就能在上面运行一个有限的算法了。
接下来就是“超参数调优”,别被忽悠住了,不过是在生成一个模型之前,没完没了地摆弄代码设置而已。
当你使用新的数据评估这个模型的时候,如果结果不太理想,你还得一遍又一遍地重复,直到能够拿出手。 这就是为什么雇佣一些对失败有耐心的人来做这件事非常重要。如果是个玻璃心,估计撑不了几回合就吐血了吧。
如果你期待有什么奇迹,我劝你越早失望越好。机器学习是非常枯燥的过程。但是,如果你能够耐得住性子,你能做的事情将会是非常不可思议的。它可以帮你写下你自己都想不到的代码,还让你能够把那些不可言说的代码自动化。
最后,提个醒。不要因为简单而讨厌它。要知道,杠杆也很简单,但它可以撬动整个地球。