随着互联网的快速发展,越来越多的人涌入互联网,互联网自此进入大数据时代。在大数据时代之后,云计算、人工智能、物联网、5G技术的发展又将大数据的发展推向高潮。
数据已经从最初的信息一步步的演变成了数据产品、数据资产。关于数据的处理技术,包含数据库、数据集市、数据仓库、数据湖、数据中台,每次数据处理的演进都代表着业务需求变化的趋势、技术的演进。
除了数据处理方式在演进之外,数据处理的基础措施也在不断的演进,包含Hadoop、Lambda、Kappa,这三种数据处理思想都是在为了解决数据处理过程中遇到的问题而产生的,每一种解决方案都有对应的场景,不存在过时之说。今天我们就一起来看看大数据基础设施的演进吧~
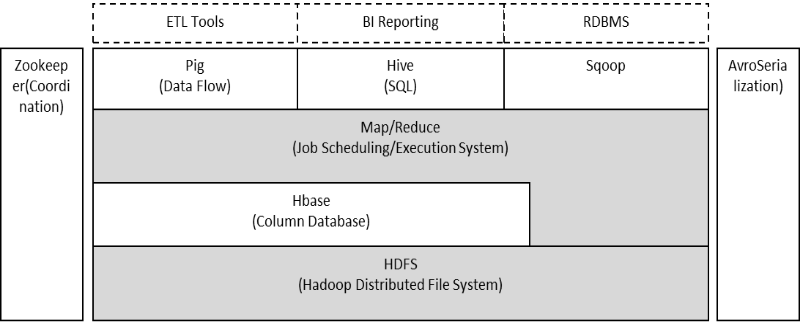
第一代基础设施:以Hadoop为代表的离线数据处理。早期的时候,互联网还处在一片红海,大家对于数据分析的要求也不高,主要是做报表、支撑决策,对应的离线数据分析方案就产生了。
Hadoop提供了一整套解决方案,底层以HDFS分布式文件系统做数据存储,所有的数据都通过MapReduce计算模型进行处理(把数据计算任务拆分成Map和Reduce两个过程,Map做初次处理,产生中间结果,Reduce做二次处理,拿中间结果进行分析产生最后数据);为了简化用户的使用成本,Hadoop在MapReduce之上提供了Pig、HIve平台,Pig支持海量数据并行计算,并提供接口给到上层做报表、导入关系型数据库;HIve基于SQL语句对数据进行分析错误,降低了如产品、运营人员的使用成本。整套Hadoop数据处理体系使用Zookeeper进行任务节点的协调管理、资源分配,保障系统的正常运行。
第二代基础设施:以Lambda为代表的流批数据处理。随着涌入互联网的网民变得,很多企业也开始涌入互联网,对于数据处理的要求、数据分析也变得高起来。
Hadoop这一套体系,当运行大量数据时,所耗费时间也会变得越来越多,无法再满足一些需要实时分析处理的场景(比如在淘宝中会动态推荐商品),因此新的流式计算引擎如Flink、Storm、SparkStreaming等开始产生。新的大数据处理方式也被提出,只有流处理、批处理配合一起使用,才能满足绝大部分使用场景,因此lambda架构被提出。
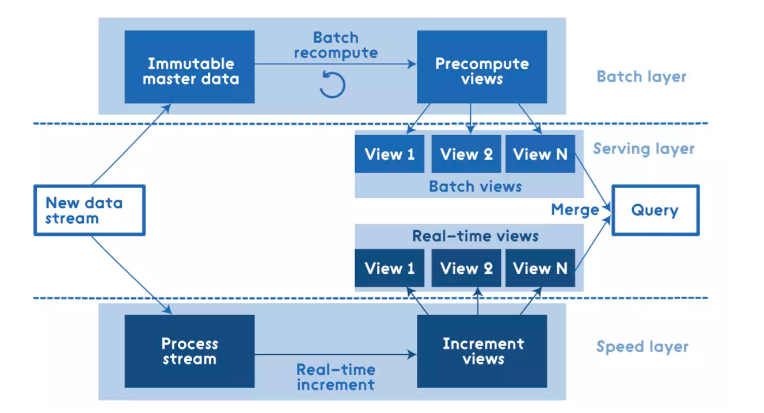
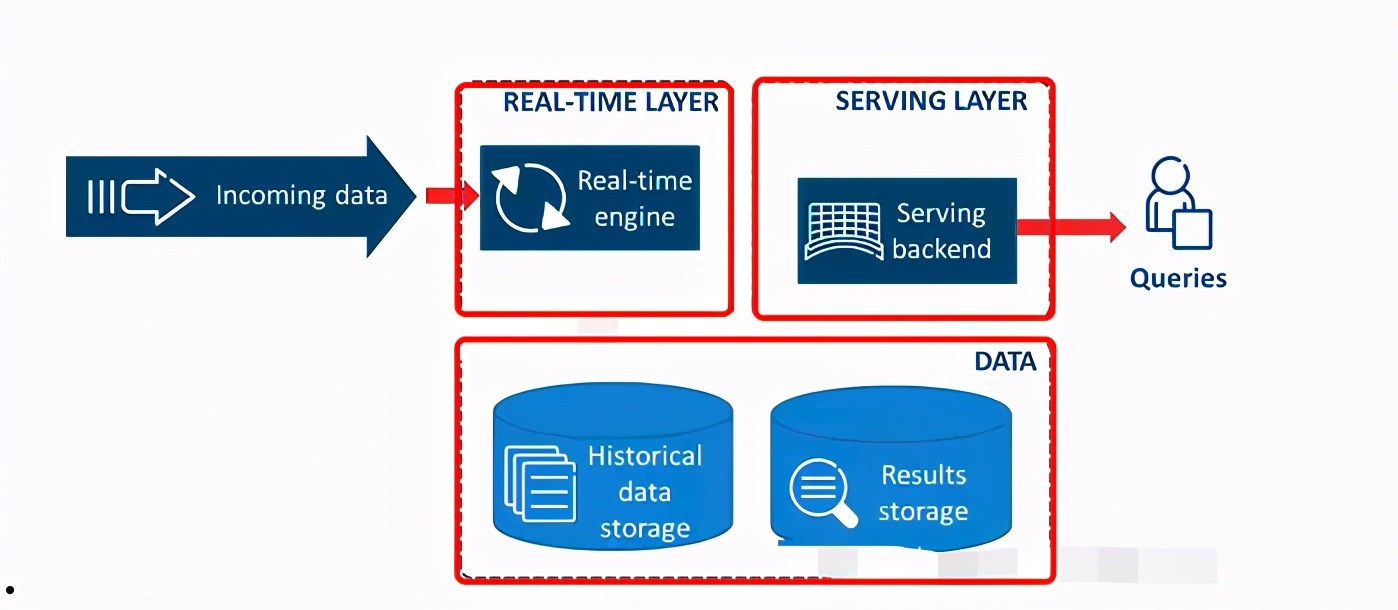
Lambda架构通过把数据分解为ServingLayer、SpeedLayer、BatchLayer三层来解决在不同数据集的数据需求。在Batch层主要是对离线数据进行处理,将接入的数据进行预处理、存储,查询的时候直接在预处理结果上查询并不需要再进行完整的计算,最后以View层提供给到业务;在Speed层主要是对实时增量数据进行处理,每来一次新数据就不断的更新View层,提供给到业务;在Serving层主要是响应用户的请求,根据用户需求把Batch层和Speed层的数据集合到一起,得到最终的数据集。Lambda架构优点是将流处理和批处理分开,很好的结合了实时计算和流计算的优点,架构稳定,实时计算成本可控,提高了整个系统的容错性、降低了复杂性。缺点是离线数据和实时数据很难保障数据的一致性,开发人员需要维护两套系统。
第三代基础设施:以Kappa为代表的集成流批数据处理。Lambda架构的流批分离解决了数据一致性问题,也提高了效率,但对应的也增加了系统的复杂性,因此期望一套系统解决流批处理的方案产生了,那便是Kappa架构。利用流计算的分布式特征,增加流计算的并发性,加大流数据的时间窗口,统一批处理和流处理数据。
Kappa架构在Lambda架构的基础上删除了Batch层,所有的数据都是流处理实时计算,计算好了之后可以直接给到业务层使用,也可以放在数据湖中,需要进行离线分析时使用。Kappa架构的优点是开发人员只需要维护实时处理模块,不需要离线实时数据合并,缺点是在实时处理时可能会存在信息丢失情况。
整个互联网大数据处理基础设施体系,从Hadoop演进到Lambda,再到Kappa,涵盖了业务所需要的各种数据的处理方式,大数据平台也变成了一个全量的数据处理平台。基于这些基础设施,在云计算基础设施保障下,我们可以有数据集市、数据仓库、数据湖、数据中台的处理方案,更好的将数据作为资产管理起来,作为知识应用起来~