大规模数据集
对数据科学家和Kaggler来说,数据永远不嫌多。
我敢肯定,你在解决某些问题时,一定报怨过没有足够的数据,但偶尔也会抱怨数据量太多难以处理。本文探讨的问题就是对超大规模数据集的处理。
在数据过多的情况下,最常见的解决方案是根据RAM采样适量数据,但这却浪费了未使用的数据,甚至可能导致信息缺失问题。针对这些问题,研究人员提出多种不同的非子采样方法。需要注意的时,某一方法是无法解决所有问题的,因此在不同情况下要根据具体需求选择恰当的解决方案。
本文将对一些相关技术进行描述和总结。由于Riiid! Answer Correctness Prediction数据集由10列,超1亿行的数据组成,在Kaggle Notebook中使用pd.read_csv方法读取会导致内存不足,因此本文将该数据集做为典型示例。
不同安装包读取数据的方式有所不同,Notebook中可用方法包括(默认为Pandas,按字母表排序):
- Pandas
- Dask
- Datatable
- Rapids
除了从csv文件读取数据外,还可以将数据集转换为占有更少磁盘空间、更少内存、读取速度快的其他格式。Notebook可处理的文件类型包括(默认csv,按字母表排序):
- csv
- feather
- hdf5
- jay
- parquet
- pickle
请注意,在实际操作中不单单是读取数据这么简单,还要同时考虑数据的下游任务和应用流程,综合衡量以确定读取方法。本文对此不做过多介绍,读者可自行查阅相关资料。
同时,你还会发现,对于不同数据集或不同环境,最有效的方法往往是不同的,也就是所,没有哪一种方法就是万能的。
后续会陆续添加新的数据读取方法。
方法
我们首先使用Notebook默认的pandas方法,如前文所述,这样的读取因内存不足失败。
- import pandas as pd
- import dask.dataframe as dd
- # confirming the default pandas doesn't work (running thebelow code should result in a memory error)
- # data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv")
Pandas介绍
Pandas是最常用的数据集读取方法,也是Kaggle的默认方法。Pandas功能丰富、使用灵活,可以很好的读取和处理数据。
使用pandas读取大型数据集的挑战之一是其保守性,同时推断数据集列的数据类型会导致pandas dataframe占用大量非必要内存。因此,在数据读取时,可以基于先验知识或样品检查预定义列数据的最佳数据类型,避免内存损耗。
RiiiD竞赛官方提供的数据集读取方法就是如此。
帮助文档: https://pandas.pydata.org/docs/
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes)
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8min 11s, sys: 10.8 s, total: 8min 22s
- Wall time: 8min 22s

Dask介绍
Dask提供并行处理框架对pandas工作流进行扩展,其与Spark具有诸多相似之处。
帮助文档:https://docs.dask.org/en/latest/
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = dd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes).compute()
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 9min 24s, sys: 28.8 s, total: 9min 52s
- Wall time: 7min 41s
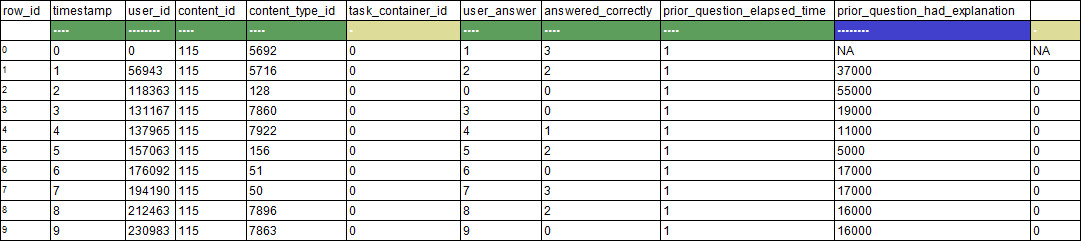
- data.head()

Datatable介绍
受R语言data.table的启发,python中提出Datatable,该包可快速读取大型数据集,一般要比pandas快得多。值得注意的是,该包专门用于处理表格数据集,能够快速读取大规模的表格数据集。
帮助文档:https://datatable.readthedocs.io/en/latest/index.html
- # datatable installation with internet
- # !pip install datatable==0.11.0 > /dev/null
- # datatable installation without internet!
- pip install ../input/python-datatable/datatable-0.11.0-cp37-cp37m-manylinux2010_x86_64.whl > /dev/null
- import datatable as dt
- %%time
- data = dt.fread("../input/riiid-test-answer-prediction/train.csv")
- print("Train size:", data.shape)Train size: (101230332, 10)
- CPU times: user 52.5 s, sys: 18.4 s, total: 1min 10s
- Wall time: 20.5 sdata.head()
Rapids介绍
Rapids提供了在GPU上处理数据的方法。通过将机器学习模型转移到GPU,Rapids可以在一个或多个GPU上构建端到端的数据解决方案。
帮助文档:https://docs.rapids.ai/
- # rapids installation (make sure to turn on GPU)
- import sys
- !cp ../input/rapids/rapids.0.15.0 /opt/conda/envs/rapids.tar.gz
- !cd /opt/conda/envs/ && tar -xzvf rapids.tar.gz > /dev/null
- sys.path = ["/opt/conda/envs/rapids/lib/python3.7/site-packages"] + sys.path
- sys.path = ["/opt/conda/envs/rapids/lib/python3.7"] + sys.path
- sys.path = ["/opt/conda/envs/rapids/lib"] + sys.path
- import cudf
- %%time
- data = cudf.read_csv("../input/riiid-test-answer-prediction/train.csv")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 4.58 s, sys: 3.31 s, total: 7.89 s
- Wall time: 30.7 s
- data.head()

文件格式
通常,我们会将数据集存储为容易读取、读取速度快或存储容量较小的格式。数据集存储有各种不同的格式,但不是每一种都可以被处理,因此接下来,我们将介绍如何将这些数据集转换为不同的格式。
- # data = dt.fread("../input/riiid-test-answer-prediction/train.csv").to_pandas()
- # writing dataset as csv
- # data.to_csv("riiid_train.csv", index=False)
- # writing dataset as hdf5
- # data.to_hdf("riiid_train.h5", "riiid_train")
- # writing dataset as feather
- # data.to_feather("riiid_train.feather")
- # writing dataset as parquet
- # data.to_parquet("riiid_train.parquet")
- # writing dataset as pickle
- # data.to_pickle("riiid_train.pkl.gzip")
- # writing dataset as jay
- # dt.Frame(data).to_jay("riiid_train.jay")
数据集的所有格式可从此处获取,不包括竞赛组提供的原始csv数据。
csv格式
大多数Kaggle数据集都提供了csv格式文件。该格式几乎成为数据集的标准格式,而且所有方法都支持从csv读取数据。
更多相关信息见: https://en.wikipedia.org/wiki/Comma-separated_values
- %%time
- dtypes = {
- "row_id": "int64",
- "timestamp": "int64",
- "user_id": "int32",
- "content_id": "int16",
- "content_type_id": "boolean",
- "task_container_id": "int16",
- "user_answer": "int8",
- "answered_correctly": "int8",
- "prior_question_elapsed_time": "float32",
- "prior_question_had_explanation": "boolean"}
- data = pd.read_csv("../input/riiid-test-answer-prediction/train.csv", dtype=dtypes)
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8min 36s, sys: 11.3 s, total: 8min 48s
- Wall time: 8min 49s
feather格式
以feature(二进制)格式存储数据对于pandas极其友好,该格式提供了更快的读取速度。
了解更多信息:https://arrow.apache.org/docs/python/feather.html
- %%time
- data = pd.read_feather("../input/riiid-train-data-multiple-formats/riiid_train.feather")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 2.59 s, sys: 8.91 s, total: 11.5 s
- Wall time: 5.19 s
hdf5格式
HDF5是用于存储、管理和处理大规模数据和复杂数据的高性能数据管理组件。
了解更多信息:https://www.hdfgroup.org/solutions/hdf5
- %%time
- data = pd.read_hdf("../input/riiid-train-data-multiple-formats/riiid_train.h5", "riiid_train")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 8.16 s, sys: 10.7 s, total: 18.9 s
- Wall time: 19.8 s
jay格式
Datatable支持.jay(二进制)格式,其在读取jay格式数据时速度快得超乎想象。从下面的示例可以看到,该方法读取整个riiid数据集用时甚至不到1秒!
了解更多信息:https://datatable.readthedocs.io/en/latest/api/frame/to_jay.html
- %%time
- data = dt.fread("../input/riiid-train-data-multiple-formats/riiid_train.jay")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 4.88 ms, sys: 7.35 ms, total: 12.2 ms
- Wall time: 38 ms
parquet格式
在Hadoop生态系统中,parquet是tabular的主要文件格式,同时还支持Spark。经过近年的发展,该数据格式更加成熟,高效易用,pandas目前也支持了该数据格式。
- %%time
- data = pd.read_parquet("../input/riiid-train-data-multiple-formats/riiid_train.parquet")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 29.9 s, sys: 20.5 s, total: 50.4 s
- Wall time: 27.3 s
pickle格式
Python对象可以以pickle格式存储,pandas内置支持pickle对象的读取和写入。
了解更多信息:https://docs.python.org/3/library/pickle.html
- %%time
- data = pd.read_pickle("../input/riiid-train-data-multiple-formats/riiid_train.pkl.gzip")
- print("Train size:", data.shape)
- Train size: (101230332, 10)
- CPU times: user 5.65 s, sys: 7.08 s, total: 12.7 s
- Wall time: 15 s
不同方法各有千秋
每种方法都有自己的优缺点,例如:
- Pandas在处理大规模数据时对RAM的需求增加
- Dask有时很慢,尤其是在无法并行化的情况下
- Datatable没有丰富的数据处理功能
- Rapids只适用于GPU
因此,希望读者掌握不同的方法,并根据实际需求选择最恰当的方法。我始终相信,研究不是技术驱动的,技术方法只是手段,要有好主意、新想法、改进技术才能推动数据科学的研究与发展。
在经过大量研究后,我确信不同数据集具有不同的适用方法,因此要多尝试,千万不要试图一招半式闯江湖。
在不断更新的开源软件包和活跃的社区支持下,数据科学必将持续蓬勃发展。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。