有人的地方就有江湖。广告作为互联网公司商业变现最为直接快捷的途径,广告作弊已经形成了一个有完整链条的黑产行业。如何通过技术手段识别并防范广告作弊?本文通过介绍常见的广告计费模式和虚假流量的获益形式和发生机制,分析广告点击反作弊的核心问题,分享相关的反作弊实践经验,详解反作弊技术体系及核心算法。
背景
世界广告主联盟WFA表示[1]“若不采取措施,2025 年虚假广告花费将高达 500 亿美元,仅次于毒品交易金额,成为世界第二大非法营收”。
互联网行业发展的几十年来,已经渗透到生活的方方面面,各种互联网公司层出不穷。互联网公司的商业变现途径已经发展出引流、电商、游戏等多种流派,但是广告变现作为一种最快捷和直接的变现途径,依然占据着整个行业的大半壁江山。国际国内的各大互联网公司如:Google、Facebook、百度、阿里、腾讯、字节跳动、各大门户或视频网站,广告收入占其总收入的比例都非常高。有人的地方就有江湖,有江湖的地方就有纷争。互联网广告也引申出了作弊与反作弊的纷争。互联网广告作弊已经成为了一个有完整链条的行业,而反作弊部门也成为了各大依靠广告变现公司的标配。
一 常见广告计费模式
一个网络媒体(网站)会包含数十个甚至成千上万个页面,网络广告所投放的位置和价格就牵涉到特定的页面以及浏览人数的多寡。这好比平面媒体(如报纸)的“版位”、“发行量”,或者电波媒体(如电视)的“时段”、“收视率”的概念。网络媒体常见的广告收费模式[2]有CPM、CPC、CPA、CPT、CPS、CPI, 下图是各种广告计费模式的逻辑和作用:
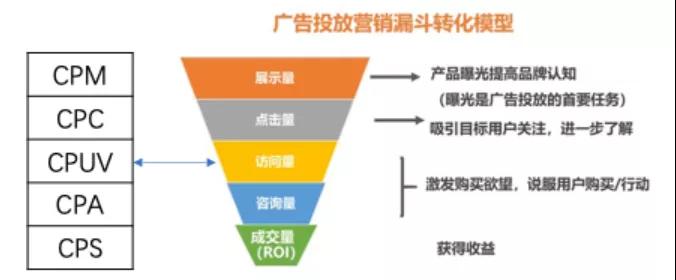
1 CPM
英文全称Cost Per Thousand Impression,也称每千次展示的成本。CPM是一种展示付费广告,只要展示了广告主的广告内容,广告主就为此付费。由于展示了广告就可以收费,不关心用户是否有后续互动转化,因此这种广告的费用也是比较便宜的。按此计费的广告一般是以展示为目的,如开屏广告。
2 CPC
英文全称Cost Per Click。CPC是一种点击付费广告,根据广告被点击的次数收费。每一次点击计一次费, 因此即使向1000个访问者展示了你的lander页面,但是只有1个人点击了你的lander,也只按照1次点击进行计费,因此可以说CPC这种模式在广告测试的初级阶段使用较为合适,为确定对你的产品感兴趣的目标人群的流量而付费,可以在测试的早期快速收集广告数据,尽快定位出目标人群画像,为下一步扩量的投放做准备。最常见的如搜索引擎关键词广告采用这种定价模式,比较典型的有Google的AdSense、百度凤巢竞价广告以及淘宝的直通车广告。
就是每一次点击计一次费,但有些联盟是有明确规定的,每个ip在一段规定的时间内只扣费一次,这样的方法可以增加作弊的难度。但是此类方法就有不少人觉得不公平,比如虽然浏览者没有点击,但是他已经看到了广告,对于这些看到广告却没有点击的流量来说,广告成了白忙活。
3 CPA
英文全称Cost Per Action。CPA是一种按广告投放实际效果计价方式的广告,而不限广告投放量。CPA的计价方式对于网站而言有一定的风险,但若广告投放成功,其收益也比CPM的计价方式要大得多。因为CPC有可能存在欺骗性(比如典型的机器人刷点击),所以就产生了CPA。比较常见的CPA计费方式的广告有注册账号、电商场景的加购物车或者收藏、微信的关注公众号等。
4 CPT
英文全称Cost Per Time。CPT是一种以时间来计费的广告,国内很多的网站都是按照“一个月多少钱”这种固定收费模式来收费的,这种广告形式很粗糙,无法保障客户的利益。但是对网站来说CPT的确是一种很省心的广告,能给网站带来稳定的收入。
CPT是品牌广告的报价方式,这种收费模式简单易用,广告主自主选择的空间大。但是CPT沿用几年,广告主渐渐发现这种收费形式缺乏说服力。对客户和网站都不公平,无法保障广告客户的利益。由于各大媒体尚未能实时地公布其每天的不同页面的日访问量和日不重复访客数,因此,广告主在衡量广告投放效果时只能根据媒体公布的数据进行估算,这种评估方法难以体现互联网广告所应有的精确性和实时性,而只是根据经验估算出广告所能传达到的用户数量及相应所需付出的费用。同时一个越来越明显的趋势是随着媒体页面访问量的不断变化提高,媒体缺乏有力的第三方数据向广告主证明这种页面访问量增长的准确可靠性,只能被动地每半年或每一年调整一次价格,以提高自己的收人。
电商网站主页中间位置的钻展和门户网站的包月广告都属于这种CPT广告。适合垂直行业平台展示广告位,类似地铁广告、电梯广告等户外广告也是这种类型,通常按周、月进行销售。
5 CPS
英文全称Cost Per Sales。CPS是一种以实际销售产品数量来计算广告费用的广告,这种广告更多的适合购物类、导购类、网址导航类的网站,需要精准的流量才能带来转化。
这种模式的好处是相对容易得到广告主的认同,只需要在完成一单订单后才会支付相应的广告费用,不好的地方是在现有条件下,会导致广告资源的浪费,例如一个网站投放了CPS广告,10000个访客中可能会有100个人对产品感兴趣,而100个人中间只有10个人最后完成了购买的转化,但另外9900个流浪其实就浪费了。所以大型媒体一般不会采用这种结算方式,采用此类方式的媒体一般处于长尾端利基产品进行广告投放。因为推广效果能够比较准确的计量与评估,对于广告主而言,CPC、CPA、CPS方式比CPM、CPT模式更加有利。
6 CPI
英文全称Cost per install。按每次装机付费,是移动端APP推广常用的计费模式。
二 虚假流量的获益形式和发生机制
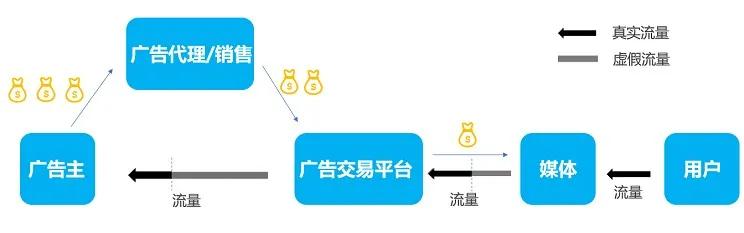
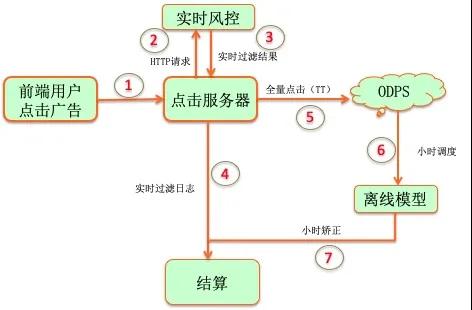
1 广告投放流程
下图是广告投放流程[1]:
2 获益方式
广告作为互联网最主要的盈利模式,利益诱惑下部分流量提供方会有作弊动机。下图[1]是几种常用广告计费模式对应的获益方式。

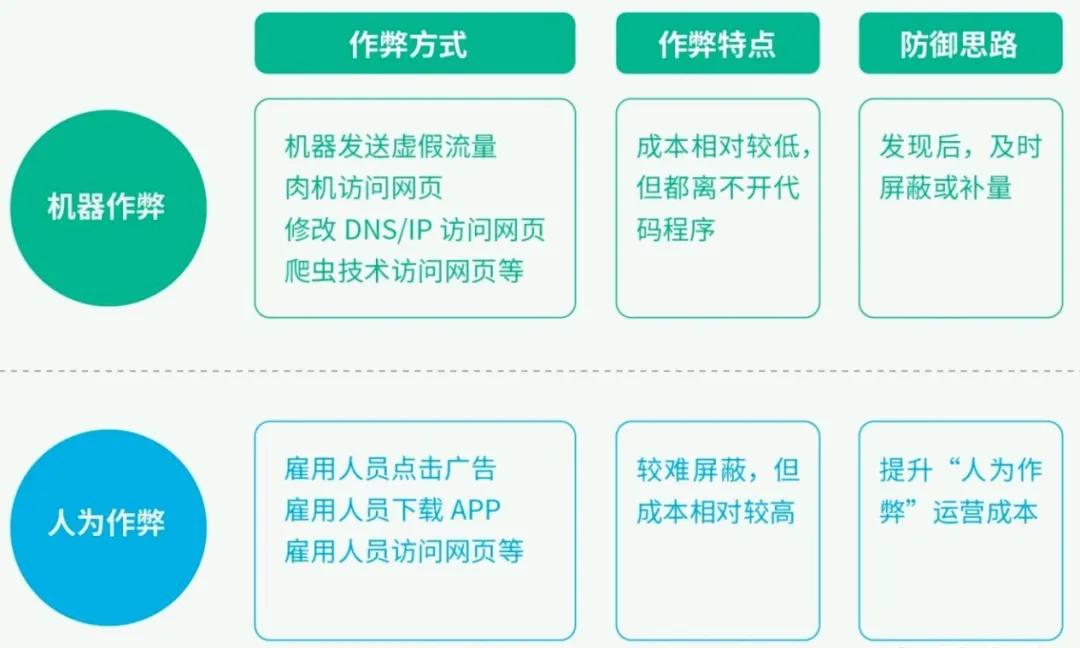
3 发生机制
机器作弊[1]成本低,特征集中,容易识别;人工作弊成本高,作弊者要想获利也会表现会一定的集中性,需要深入分析数据挖掘异常特征,从而识别作弊。
三 广告点击反作弊核心问题
世界广告主联盟WFA表示[1]“若不采取措施,2025 年虚假广告花费将高达 500 亿美元,仅次于毒品交易金额,成为世界第二大非法营收”。
互联网行业发展的几十年来,已经渗透到生活的方方面面,各种互联网公司层出不穷。互联网公司的商业变现途径已经发展出引流、电商、游戏等多种流派,但是广告变现作为一种最快捷和直接的变现途径,依然占据着整个行业的大半壁江山。国际国内的各大互联网公司如:Google、Facebook、百度、阿里、字节跳动、各大门户或视频网站,广告收入占其总收入的比例都非常高。有人的地方就有江湖,有江湖的地方就有纷争。互联网广告也引申出了作弊与反作弊的纷争。互联网广告作弊已经成为了一个有完整链条的行业,而反作弊部门也成为了各大依靠广告变现公司的标配。
虚假流量的存在,让数字广告行业遭受前所未有的信任危机。具体危害主要表现在:
- 虚假流量的存在,让广告效果、品牌安全等方面都难以实现广告主的投放初衷,会导致获客成本的增加,直接造成了广告主的经济损失。
- 无效流量掩盖了真实用户。从结果上看,虚假流量提升了流量数据,虚增的曝光次数实际对广告主并无价值,无法提升客户与商机的数量、无法提升真实的用户留存和真实的用户活跃。
- 数字广告行业遭受前所未有的信任危机。因为不良的竞争及短期的利益驱使,加上广告主对数字广告营销效果的困惑、混乱,造成广告主对数据广告的信誉危机。
下述探讨按CPC计费的广告点击反作弊。
1 无效点击定义
点击反作弊的工作目标是把流量中存在的“无效点击”过滤掉。对于“无效点击”的定义,维基百科上的定义如下:
Click fraud occurs in pay per click online advertising when a person, automated script or computer program imitates a legitimate user of a web browser clicking on an ad, for the purpose of generating an improper charge per click.
简单来说无效点击是指在CPC计费的广告系统中,以人工或者机器手段蓄意造成的非以转化为目的的广告点击行为。
2 广告点击业务的运转逻辑
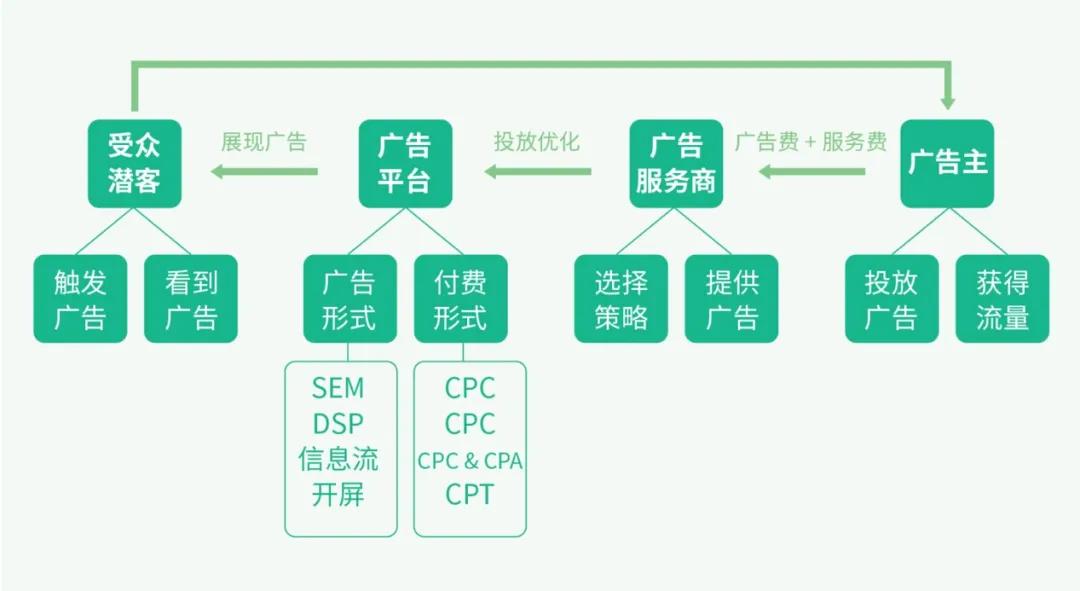
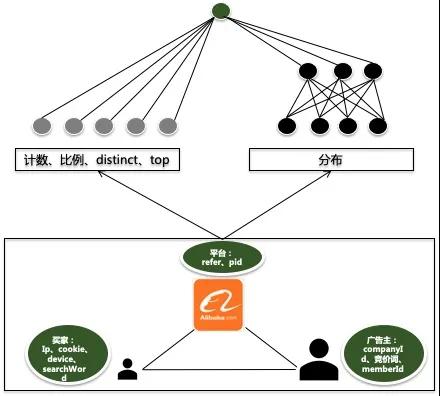
下图[3]是广告投放过程涉及的4个角色,他们的基本功能和诉求如下:
- 广告主:将自己产品的广告触达到用户,通过广告在受众群体或目标用户中产生一定的品牌影响力,进一步使得用户成为其服务或产品的消费者。
- 广告代理/销售:比较专业的广告推广操盘手,帮广告主管理账号,提供专业的营销服务。
- 广告交易平台:是一个连接互联网媒体和广告主的广告系统平台,不仅会给广告主提供广告营销工具和广告投放服务,而且会借助互联网媒体的流量实现广告的商业价值。比如有大量用户和流量的搜索引擎公司、电商公司、社交公司。
- 媒体:媒体一般为互联网网站或互联网信息与服务的提供商。互联网广告投放的媒体通过用户在其网站浏览信息或者使用服务的过程中完成广告信息的传播,媒体一般也叫联盟。比如一些小网站,如博客。
- 用户:在互联网上浏览信息或使用服务的人,也是广告主的潜在的广告客户。
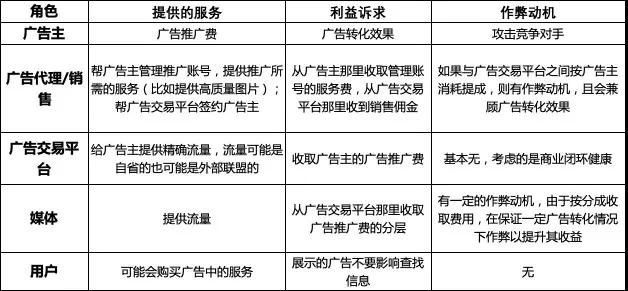
下表介绍了上面5个角色的在广告产业链中“提供的服务、利益诉求、作弊动机”。这些作弊者是黑产中的一部分,另外一些专业黑产为上述作弊者提供专业的作弊服务(比如养的批量账号,比如提供可以修改点击者环境信息的作弊器),以收取服务费。
3 反作弊的意义
- 定性方面:业务发展和风险如同汽车的引擎和刹车,是有机的组成。引擎负责向前,刹车负责避免风险。
- 定量方面:业务如同放贷,而技术风险就是放贷的利率。利率高了,业务就跑不动了;利率低了,是要有泡沫破灭的大风险的。利率的高低是需要数据和艺术来平衡的。”
广告点击反作弊表面上是过滤了点击,减少了营收。实际上是过滤广告主认为不该扣费的点击,保障广告主的正常投放广告,提升广告主对平台的信任度,为广告业务的发展保驾护航。
正如CRO的使命中所说“反作弊的使命是让消费者安心,让业务方/商家与合作伙伴省心,让监管单位放心,让作恶者灰心”。
4 反作弊的难点
业务视角的难点
很赞同大家提的反作弊要尽量做到“上医治未病”、“遏制劣币驱逐良币”以及反作弊要做到“水不惊鱼不跳”、“没有人知道我的存在就是我做得好的一个表现”。这是对平台发展、买家和卖家体验的义无反顾的责任,做得不好的时候别人很快就知道我的存在了,但是做到“风平浪静”的时候怎么证明是反作弊的贡献呢?准确过滤的作弊量一定程度上反映问题。客户的体验和信任度也反应反作弊的价值。
技术视角的难点
- 道高一尺魔高一丈,作弊和反作弊都在不断迭代升级,如果没能过滤新型大规模攻击将非常影响客户体验和对平台的信任,怎么持续做到“上医治未病”、“防范于未然”,保障客户体验和避免平台资损。后续我们会介绍事前我们的“主动发现作弊机制”,以及事后升级规则和模型。
- 缺少置信样本,怎么在保证召回作弊的情况下控制平台的资损。后续“样本工程”部分介绍我们的有监督模型是怎么选样本的。
- 用什么指标衡量业务做得好?我们用准召率和召回率两个指标,准确率分两种,一种是新策略的准确率,计算逻辑为“大盘点击的转化率/新策略单独识别点击的转化率”;另一种是线上所有策略的准确率,计算逻辑为“大盘点击的转化率/所有策略识别点击的转化率”。召回率指客户赔付总次数和金额。
5 作弊动机
在整个行业中每个角色在整个链条中利益诉求不尽相同,其作弊动机也不一样,接下来我们单独分析每个角色的作弊动机及利益所在:
- 广告主:虽然广告主是最初的金主,但也存在作弊的强烈动机。比如在竞价环境下希望尽快消耗竞争对手的广告从而使自己容易拿到量,或者对自己作弊从而提升自己的点击率。
- 广告交易平台:广告交易平台还有被动的作弊,因为还有很多流量来自于其它媒体的引流,这些媒体参差不齐,广告交易平台和媒体之间的结算以点击来结算,所以媒体也有足够的动力作弊。而这些点击完全不会有任何转化。
6 作弊类型
- 机器作弊:使用机器或程序来模拟广告行为,或者通过木马和肉鸡模拟用户的广告行为。为了使点击行为不被规则类发现还会控制ip分布和时间。机器作弊有如下的方法:模拟器、Proxy(网关,修改ISP,IP,UA,设备类型等)、爬虫(各家搜索引擎大量爬取着整个网络,依然会消耗巨大的广告预算)。
- 人工作弊:雇人用真实的设备进行广告的各种行为操作,主要方式为众包。
7 评价反作弊效果的方法
以下对比我们与阿里妈妈、百度凤巢的主要评价指标,主要评价指标均是准确和召回两个视角。召回视角比较相似:都是客户感知,客户赔付次数和赔付金额。以下对比准确视角的指标。
我们评价过滤准确的方法
准确视角:新策略上线前,计算其近似准确率的逻辑为“大盘点击的转化率/新策略单独识别点击的转化率”大于 X,值越大越准确,具体阈值根据业务统计数据和人工评测确定
阿里妈妈评价过滤准确的方法
准确视角:借助淘系闭环转化效果,估算准确率置信区间。
百度凤巢评价过滤准确的方法
准确视角:人工抽样,可视化的评测各个维度的统计分布特征,然后计算准确率。
我们与阿里妈妈均是电商业务,有转化数据,比较适合用转化率指标。百度凤巢代表的其他无转化指标的广告系统,适合人工评测。
另外关于转化率可以根据业务定义,比如腾讯APP推广反作弊系统会让各个APP设定转化指标,如留存、激以及电商场景的收藏、加购物车等。
四 反作弊技术体系
反作弊非常重要的一点是数据分析,本文暂不展开。下述技术已经应用到多个业务的广告点击反作弊中,下述技术不仅适用于按CPC计费的广告点击反作弊,多数技术也适用于其他计费模式(CPM/CPA/CPS/CPI)的反作弊。
1 技术体系大图
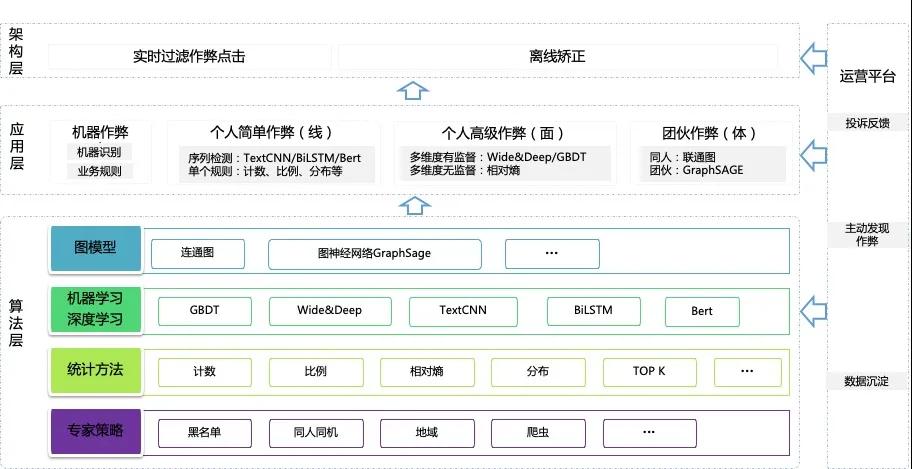
数据层
线上系统使用了用户历史多天的站内全链路行为数据,和最近的曝光、点击数据。行为反映用户的意图,在行为序列模型TextCNN、BiLSTM、Bert和GraphSage里都用到了用户的历史行为序列。
算法层&应用层
如前面所述,作弊和反作弊都在不断迭代升级。目前的算法主要集中在人工经验规则、统计策略、机器学习和深度学习模型、图模型。
下述简单介绍算法迭代的过程,详细介绍请参考后面核心算法部分。
- 业务刚开始的作弊主要是机器作弊,一些人机识别、爬虫识别、黑名单即可识别大部分作弊。我们称之为单点反作弊。
- 随后作弊者升级到人工作弊,比如大规模人工点击(期间还不断清除介质),或者只点没有转化的行为序列异常,我们会升级到计数、比例、分布等统计策略和行为序列模型TextCNN、BiLSTM,已经能拦截大部分的个人作弊。我们称之为线上反作弊。
- 接着作弊者又会升级高级的人工作弊,模拟人的点击,尽可能的各种特征上不集中,但是毕竟作弊者要达到收益的话,需要有一定的作弊量,而他们不知道正常点击的真实分布,自然的会在一些维度上出现异常。我们反作弊算法升级到无监督相对熵模型,再后面有样本了升级到有监督的GBDT和Wide&Deep,均是从多个维度和特征上识别作弊。我们称之为面上反作弊。
- 再后面作弊难度更大了,他们会有众包团伙作弊,我们也升级联通图、图神经网络GraphSage等模型,识别作弊团伙。我们称之为体反作弊。
架构层
广告点击涉及到钱,时效性要求高,所以必须有实时反作弊;但是实时策略只能看到当前点击之前的数据,不能看到点击之后的数据,可能存在少量判断不准的情况。故我们增加了小时级别的离线模型,使用更多数据提升准确率和召回率。
运营平台
- 投诉反馈是与广告主反馈无效点击的通道。
- 主动发现作弊是我们离线运行一些达不到上线准确率的策略,以在广告主感知到之前主动发现作弊,提升客户体验。由于准确率达不到上线标准,故需要较多的人力分析挖掘的疑似作弊。在后面的主动发现作弊环境会详细介绍思路。
- 数据沉淀包括两方面,一是识别的无效点击用于后续训练有监督模型识别作弊,二是识别无效点击,以便下游广告算法等清洗数据。
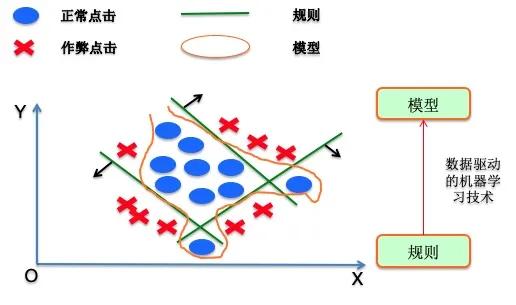
2 规则与模型对比
新型作弊大规模出现时,非常影响客户体验,进而影响业务发展,规则适合解决这种紧急出现的大规模作弊;且规则容易实时部署;且规则可解释性强,早期的反作弊中使用较多,正因为这个原因,微软的广告反作弊系统2016年主要还是规则;再者反作弊场景天然缺少作弊样本,也是规则受欢迎的一个原因。但由于规则过于依赖人的经验,且维度单一,容易被作弊者绕过,在作弊退去时可能因为准确率变低而误过;另外一个规则解决一类作弊的话,后期会出现规则过多,维护成本高。另外统计规则为了保证准确率段首较大。
当规则和人工经验多了会积累作弊样本,这时候将规则作为模型的特征训练模型,让模型自己学作弊的特点以召回作弊。由于模型使用特征较多,准确率更高,且一定程度上解决规则的段首问题。
3 样本工程
- 前面提到我们是电商场景,所以有转化数据,而且前期有统计规则的过滤点击,故可以用规则圈一些较准确的样本(即转化率较低的样本)。
- 基于经验构造样本,也就是在其他场景的反作弊经验的迁移应用。
- 使用SMOTE[4]生成样本,我尝试过SMOTE生成样本的实验,召回上略有提升。当作弊样本较少,SMOTE相当于差值法,生成作弊样本使得取值分布更全面。
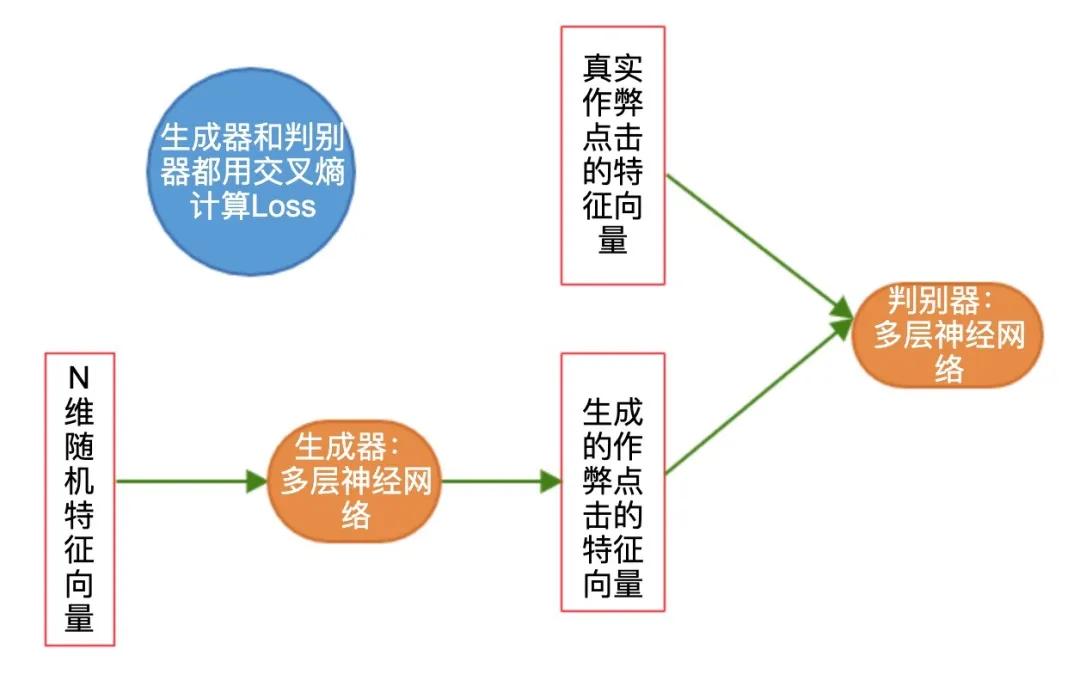
- 使用GAN[5]生成样本,[6]用GAN生成欺诈样本用于训练有监督模型。下图是GAN生成作弊样本的思路。
4 特征工程
一般来说,真实流量一般自然 (真实的流量在各个维度中表现一定是自然的)与多样(网民的喜好各不相同,行为一定也是多样的)。而对于虚假流量,常表现出一定的目的性(虚假流量的产生一定和某个特定的目的有关)和规律性(特定的目的导致虚假流量一定有特殊的规律)。
由于虚假流量与真实流量在具体访问行为有较大差异,围绕用户行为可从以下几方面识别出虚假流量。
模型的特征值或者规则是由下述的“维度*特征*类型”组合而成的,其中类型是通用的,支持配置。
维度
常用维度:时间&地域维度、终端类型、操作系统、联网方式、浏览器、设备介质、IP、广告主账号、refer、query集中等。
下面以时间维度&地域维度举例:正常的流量访问分布在一天中的各个时段、地理分布较为均匀(区域性投放或者活动除外)、访问趋势较为平缓。而虚假流量出现时间段特殊、来源区域集中、趋势突增的情况。因此,通过流量产生的时间、地理位置、访问趋势变化都可以成为判断虚假流量的参考方式。
同理用户的终端类型、操作系统、联网方式、浏览器、设备介质、IP、广告主账号、refer、query集中等属性,同样可以成为判断虚假流量的参考标准。
特征
1)产品参与度
具体包括平均访问深度、平均访问时长、用户行为路径、鼠标点击位置等。
- 平均访问深度:访问深度是用户一次浏览网站、APP的深度,它是衡量网站服务效率的重要指标之一。以刷量为目的的虚假流量,用户访问深度通常非常低,因为他的目的是作弊,点完即走。当然造成用户访问深度不够的原因有多种,如新投放的落地页的失败引导。因此我们在观察此指标时,应率先排除产品较大改动造成的访问深度不足等特殊情况,或者与其他渠道的流量数据综合比较,进行科学评估。
- 平均访问时长:平均访问时长指标,主要用来衡量用户与网站、APP 交互的深度。交互越深,相应停留的时长也越长。显然虚假流量追求的是“量”,而非“时长”,因此平均访问时长也可以配合几个网站参与度指标一起分析。比如机器点击的访问时间会比较集中。
- 用户行为路径:用户在网站中的访问行为路径,用户路径的分析模型可以将用户行为进行可视化展示。因此通常用户通过渠道来到。网站后会有不同的行为,他们一般会从落地页开始进行分流,会访问不同的页面,并在不同的页面结束对网站的访问。显然, 用户行为序列分布是没规律的,而对于虚假流量,虽然通过某些方式完成点击,但也是预先设定,有迹可循的。后面的TextCNN和BiLSTM模型解决的就是行为序列异常的作弊,有相应的作弊case,用户基本只访问homepage和detail,没有访问其他页面。
- 鼠标点击位置:虚假流量用户的鼠标点击位置通常是集中的,借助热力图工具可以较为容易地发现问题。
2)转化情况
很多作弊流量可以模仿人类行为,成功绕过平均访问深度和停留时长这些宏观指标,但是要模仿一个业务转化就比较难了,如果宏观指标表现很好,业务转化很少的话,就需要提高警觉。当广告主被恶意攻击时,其点击击率会突然变高或者推广时长突然变低。
类型
以下的策略类型均可配置“特征”和“维度”。
- 计数:如策略“IP近1天点击次数”,超过一定阈值是则是作弊。适用于过滤大规模攻击。
- 比例:如策略“IP下平均访问时长小于等于0秒的点击数占比为Y”,Y过大也是作弊。适用于“可列特征取值的某一个值占比异常的情况”。
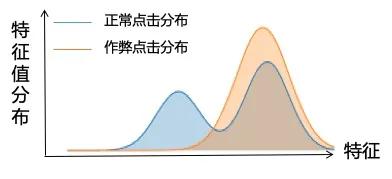
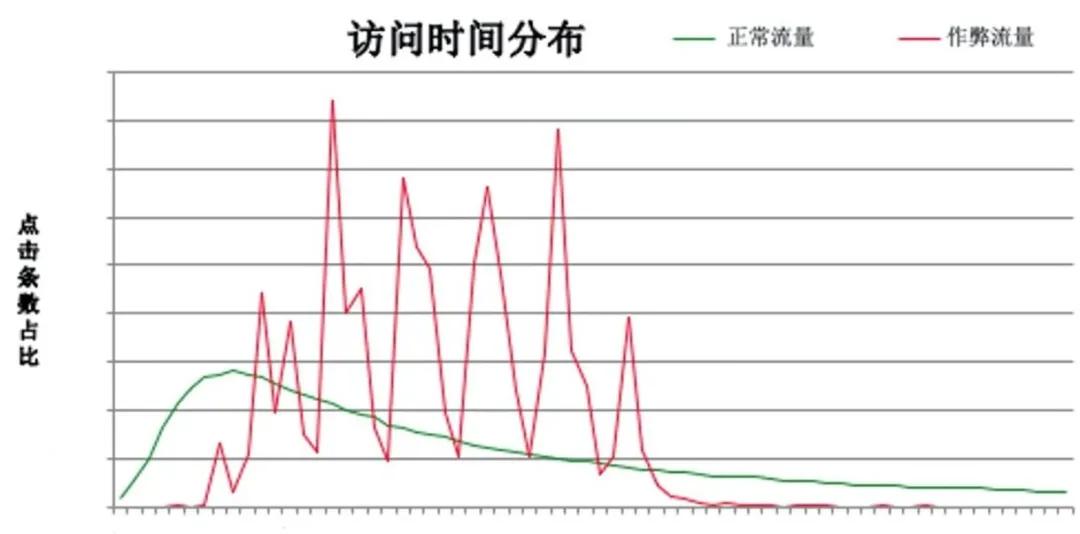
- 分布:如下图所示是作弊点击和正常点击在访问时长的分布。我们可以用相对熵或者卡方分布计算其异常度。适用于“可列特征取值是多个值”。
- Distinct:如策略“ip维度设备介质的数目”,该例子解决换设备作弊。适用于维度对象去重后值较多,如cookie的个数,行业的个数,国家的个数等值较分散的场景。
- 集中度:比如策略“广告主维度top K的ip的点击占比”,该例子解决特定ip攻击广告主的情况,适用于不可列特征值的top K值较集中的场景。
- 子维度Distinct数目分布:比如策略“广告主主维度下的IP子维度下不同cookie数目的分布”——该例子解决换cookie攻击Memberid的。这里广告主是主维度,IP是子维度。适用于子维度换ip,换useragent,换设备介质等,子维度下某个特征取值分布于基准有差异。
- 计数分布:比如策略“IP维度设备介质子维度点击次数的分布”,该例子解决机器均匀点击作弊。适用于子维度点击次数与基准差异,主要是多次点击。
5 主动发现作弊
主动发现作弊是为了在客户申诉前发现并召回作弊,以提升客户体验,但其实也已经出现作弊了。
- 异常检测。[7]和[8]分别是之前我整理的中文和英文版“从时间序列、统计、距离、线性方法、分布、树、图、行为序列、有监督机器学习和深度学习模型等多个角度的异常检测方法”。我们用这些方法结合上述特征工程环节的维度、特征、类型,提前发现异常。比如“memberid的点击率和推广时长的变化,或者某些维度下的其他的广告指标”。如果策略准确率达到上线要求则部署到线上,否则需要对挖掘的数据做进一步分析,针对发现的作弊调研策略。
- 运营人员去市场上调研作弊器。
- 自己构建各种作弊数据模拟攻击反作弊系统,观察其鲁棒性。
- 蜜罐。收集作弊者的更多信息。
6 核心算法
识别机器作弊(点)
早期的作弊是机器点击、业务上的无效点击上线规则,规则只关注较少维度的信息。比如识别爬虫、内网点击。我们称之为单点反作弊。
识别个人简单作弊(线)
在作弊者升级到人工作弊后,我们会升级到计数、比例、分布等统计策略和行为序列模型。我们称之为线上反作弊。
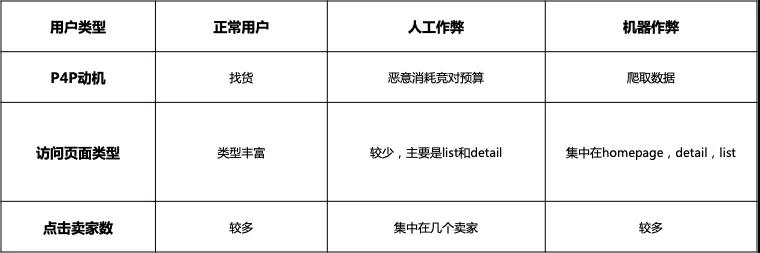
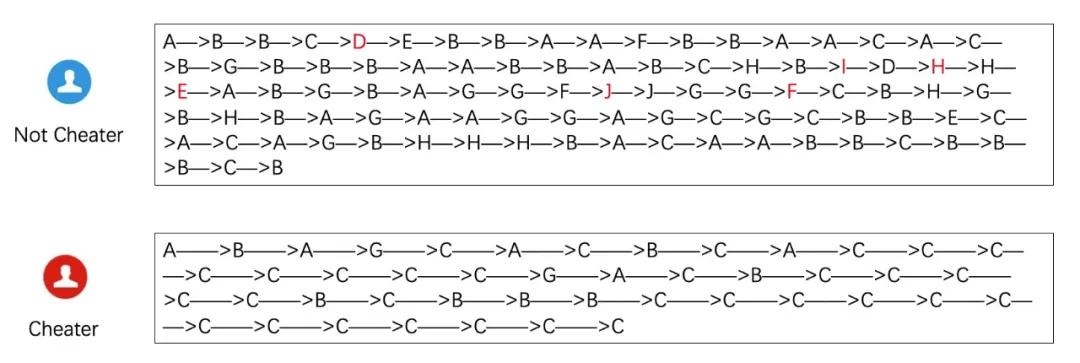
下图是我们发现的网站某行业出现的一类攻击,作弊者只访问A、B、C、G共4类页面,因为他的目的就是点广告。正常用户访问页面很丰富。还会访问D、E、F、H等页面,想咨询买东西。
我们将用户近7天在网站的访问页面序列作为特征,识别本次点击是否是作弊点击。先通过Word2Vec对每个页面进行文本向量化编码。然后模型预测向量序列是否是作弊点击。
1)TextCNN
TextCNN[9]是利用卷积神经网络对文本进行分类的算法,输入是词向量,最后一层full connected网络输出预测结果。
卷积神经网络的核心思想是捕捉局部特征,对于文本来说,局部特征就是由若干单词组成的滑动窗口。卷积神经网络的优势在于能够自动地对特征进行组合和筛选,获得不同抽象层次的语义信息。如图所示:
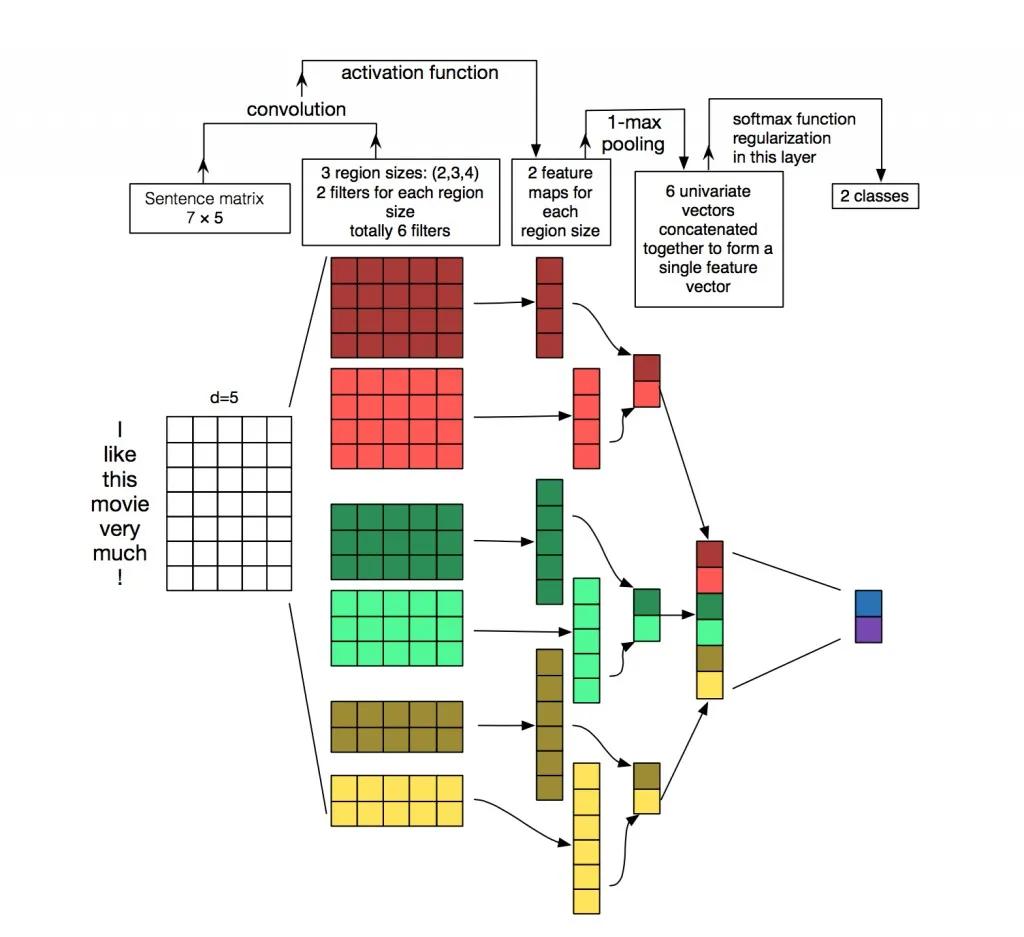
下图的输入是一个用预训练好的词向量(Word2Vec)方法得到的一个Embedding layer。词向量的维度是固定的,相对于原来的One-Hot编码要小,同时在新的词向量空间语义上相近或者语法相近的单词会更加接近。两个维度,横轴是单词、纵轴是词向量的维度(固定的)。我们的场景的模型结构图如下:
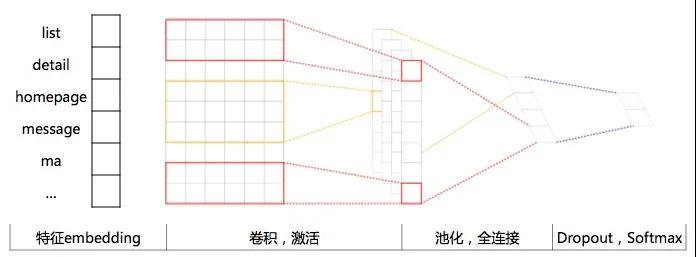
2)BiLSTM+Attention
我们也尝试了BiLSTM+Attention[10],即双向LSTM挖掘行为序列上下文关联信息。LSTM依据之前时刻的时序信息来预测下一时刻的输出,但在有些问题中,当前时刻的输出不仅和之前的状态有关,还可能和未来的状态有关系。Bi-LSTM可以看成是两层神经网络,第一层从左边作为系列的起始输入,在文本处理上可以理解成从句子的开头开始输入,而第二层则是从右边作为系列的起始输入,在文本处理上可以理解成从句子的最后一个词语作为输入,反向做与第一层一样的处理处理。最后对得到的两个结果进行处理。在我们的场景中即理解为正常点击的用户行为序列和作弊点击的用户行为序列从左往右和从右往左都有较大的区分性。LSTM虽然能获取历史信息,但是不能突然重要信息,为了更好的筛选历史信息中的重要信息,增加了Attention。
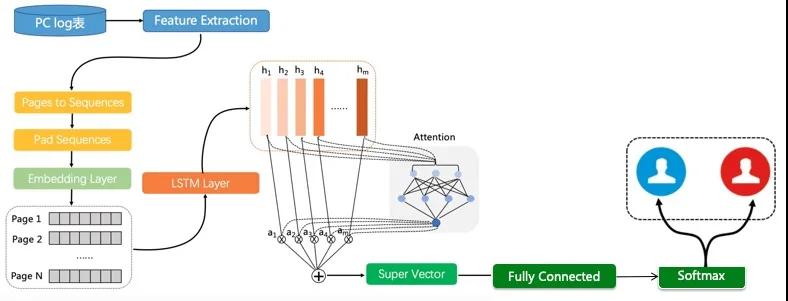
3)Bert
BERT (Bidirectional Encoder Representations from Transformers)模型是谷歌提出的基于双向Transformer[11]构建的语言模型。通过海量语料预训练,得到序列当前最全面的局部和全局特征表示。
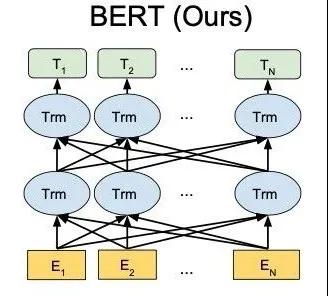
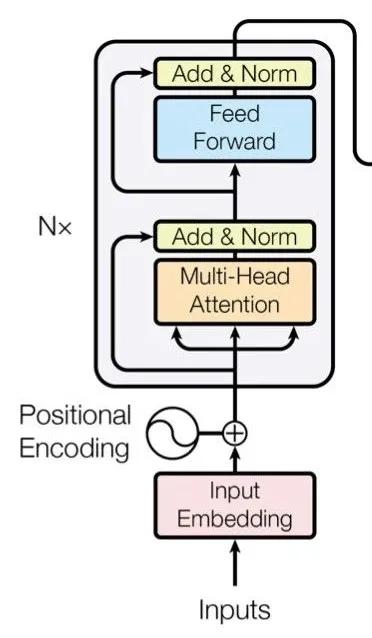
BERT[12]网络结构如上图所示,Bert的内部结构是多个transformer 的encoder,从上图可以看出Bert是双向结构的,transformer 的encoder如下图所示。encoder包含一个Multi-Head Attention层和一个前馈神经网络,self-attention能帮助当前节点既关注当前的词又能获取到上下文的语义,Multi-Head Attention扩展了模型集中于不同位置的能力。
我们选择BERT-Base,Uncased模型。在做文本分类项目时,只需要修改run_classifier.py文件的数据预处理类。
4)三者效果对比
- TextCNN通过不同的滑动窗口可以获取不同位置的上下文的特征,在测试集上效果比BiLSTM+Attention好。
- Bert的双向结构和多头机制可以从多个角度获取上下文特征,在测试集上效果比TextCNN好。
识别个人高级作弊(面)
在我们识别上述作弊后,接着作弊者又升级高级的人工作弊,模拟人的点击,尽可能的各种特征上不集中,但是毕竟作弊者要达到收益的话,需要有一定的作弊量,而他们不知道正常点击的真实分布,自然的会在一些维度上出现异常,故我们反作弊算法升级到无监督相对熵模型,再后面有样本了升级到有监督的GBDT和Wide&Deep,均是从多个维度和特征上识别作弊。我们称之为面上反作弊。
1)相对熵
下图是正常点击和疑似作弊点击的访问时长的分布。在我们没有其中的作弊点击标签时,我们使用相对熵识别作弊点击。
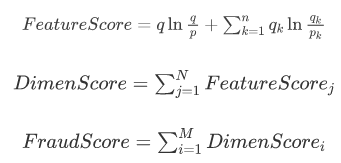
我们先计算N个特征的异常分,再计算M个维度的异常分,最后求和。
实际使用中,我们发现相对熵的一个缺点是新出现的作弊会带偏基准,从而导致误识别。由于相对熵模型是把线上策略识别为正常点击的做基准,当新型作弊出现时,我们不能及时识别,会将其当做基准,从而基准不准确。另外就是相对熵在识别时的候选样本不能包含大规模机器攻击,它们也会带偏分布。即使用时待识别样本中需要剔除规则识别的特征非常集中的点击。
2)Wide&Deep
Wide&Deep[13]通过分别提取wide特征和deep特征,再将其融合在一起训练,我们场景下模型结构如下图所示。
wide是指高维特征和特征组合的LR。LR高效、容易规模化(scalable)、可解释性强。出现的特征组合如果被不断加强,对模型的判断起到记忆作用。但是相反的泛化性弱。deep则是利用神经网络自由组合映射特征,泛化性强。deep部分本质上挖掘一些样本特征的更通用的特点然后用于判断,但是有过度泛化的风险。算法通过两种特征的组合去平衡记忆(memorization)和泛化( generalization)。为了进一步提升高级人工作弊的召回率,减少统计规则的段首漏过,使用前面的一些规则和有监督模型挖掘的转化率较低的比较准确的作弊样本作为训练样本,线上统计规则作为模型的特征,训练Wide&Deep模型识别作弊。
我们的场景中的特征有:ip、memberid、refer等维度的计数、比例、分布、distinct等类型特征。
识别团伙作弊(体)
我们也发现一些团伙攻击广告主,特征表现为先是一个cookie换不同ip,再是ip下换多个cookie和utdid。每个设备介质点击次数较少,绕开了前面的统计策略,也有些点的多的段首漏识别了。而由于我们的CPC较高,客户感知无效点击较明显。我们先是升级联通图解决同行攻击和点自己的作弊,再升级图神经网络GraphSage等模型识别作弊团伙。我们称之为体反作弊。
图神经网络[14][15][16]GraphSage[17]的异构网络适合我们的场景。下图是GraphSage两层从邻居聚合特征信息的示意图:
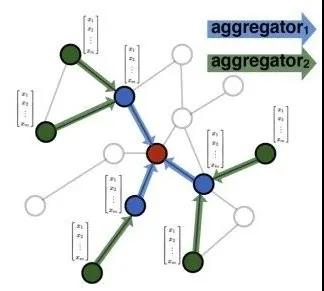
在我们的场景中,ip、utdid、cookie等介质组成的异构图神经网络,下图中红色框的seller是为了示意被一个团伙换介质攻击,实际构图中没有seller。即将强/弱介质连接的团伙的特征进行聚合。
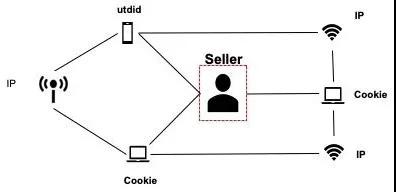
顶点和边特征:介质近30天的作弊信息和站内行为数据。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】