本文转载自微信公众号「石杉的架构笔记」,作者雨后晴天 。转载本文请联系石杉的架构笔记公众号。
1、前言
HashMap 是 java工程师最常用的数据结构之一,但是能对其原理掌握的比较深的同学很少。尤其是本文的主题,据一些常年负责招 聘的朋友介绍。
HashMap 的死循环是面试中的常见问题,但是能讲清楚的面试者很少,即使这些应聘者工作时间都比较长。
原因是,目前讲解这个问题的文章虽多,但好文章却不多。
也有些文章讲解的很完善,但内容太过烧脑,所以看下来基本上都云里雾 里。鉴于目前的情况,本文基于我个人对源码熟练掌握的基础上,跳出源码,因为那太烧脑,提炼出核心环节。尽量一步一图,以大白话 形式将底层原理呈现出来。本文的理论基础是基于 jdk1.8 以下版本。死循环问题也主要存在 于 jdk1.8 以下的版本中。
2、HashMap 的数据结构
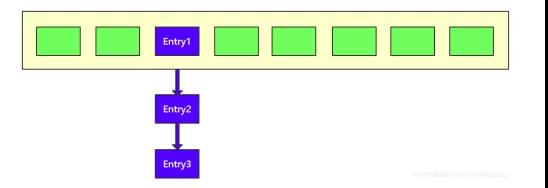
jdk1.7 版本的HashMap,底层结构是一个数组,数组中的每项都可以是个链表,开始时我们用数组保存元素,当添加元素遇到冲突,即相同位置处有多个元素时,就将这些元素添加到对应的链表 中,所以 HashMap 的底层结构可以认为是由数组和链表构成。
如果,你在构建一个 HashMap 时不指定数组大小,那么默认情况下,数组大小为 16,但限于篇幅。
下面我们只画了一个大小为 8 的 数组数组,在索引为 2 处有个链表,存放着 3 个元素,分别为 Entry1、Entry2、Entry3。这三个元素的 hash 运算结果是一样的而 且都为 2,所以在数组的 index=2 构成了一条链表。
3、插入数据
在往 HashMap 中添加元素时,比如需要在上面的HashMap 中 添加一个节点 Entry4(k4,v4)。
首先会根据它的 key 值 k4 计算 hashcode 值,然后再对这个 hashcode 值做些复杂运算,得到在数组中的目标 index,比如为 4, 这时因为数组索引为 4 的位置为空,可直接将该元素插入到其底层数 组中。
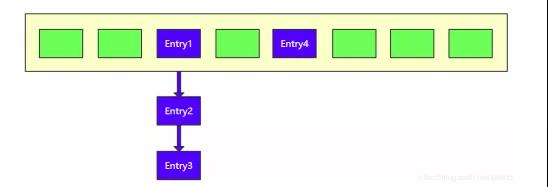
因为不同的 key 完全可能有相同的 hashcode 值,当然也完全可能在数组中有相同的目标 index。比如,要新添加一个元素 Entry5(k5,v5),对 k5 进行运算得到的目标 index 为4。
但是因为数组中对应位置已有一个元素 Entry4, 我们清楚一个数组的同一个索引处不可能连续存储两个元素而不被覆 盖,所以这时会怎么处理呢?
这时链表就派上用场了,将这两个元素在 index 为 4 处构成一个 链表即可以完美的解决冲突问题。
但是要注意,jdk1.7 采用的是头插 法。就是将新节点 Entry5 放在数组中作为链表的头节点,将原来的 Entry4 移出作为其 next 节点。如下图所示:
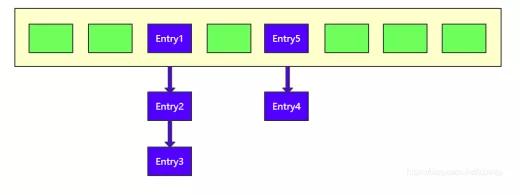
为何要一直强调是 jdk1.7 版本,因为在 jdk1.8 的时候 HashMap 结构发生了较大的变化,1.8 版本的 HashMap 采用的是尾插法而且底 层结构也发生了变化。
4、扩容
java 工程师都清楚 jdk1.7 版本的 HashMap初始默认长度为 16,你也可以自己定义,但不管你是自定义还是选择默认长度,
随着 元素的增加并达到了一定的阈值,总是要扩容的。扩容时是按 2 倍来进行的,就是创建一个 2 倍大小的数组,将原 来的元素重新 Hash,计算新的 index 放入到新的数组+链表结构中。
5、高并发下的扩容问题
HashMap 的这一结构和扩容机制可以保证,在大数据量情况 下,读写性能依然能保持优良。
插入时采用头插法会非常快速,读取 时,也不会因为链表过长而影响读取性能。看到这,会不会觉得 Hash 是个完美的设计,其实不是,因为 HashMap 并不是线程安全的数据结构。
尤其是在扩容时,如果并发量不大通常不会有什么问题,但在高 并发情况下,扩容可能导致很严重的问题。我们下面来模拟一个高并发情况下扩容的例子。
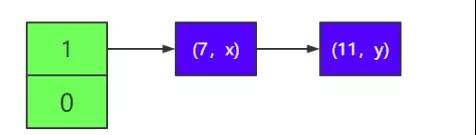
1)假设有一个 HashMap,它的负载因子为 1,有两个元素(7,x)和 (11,y),它们 hash 运算的结果都为 1,所以都在 1 号链表(即 index 为 1 所指向的链表中,为便于描述,下面都简称)中,如下所 示。
2)这时你需要往里面添加一个节点(15,z),这时有 3 个节点,因为 已达到扩容阈值,需要扩容。
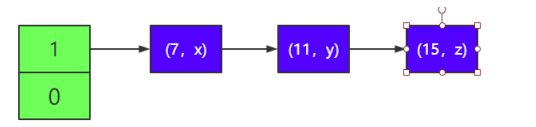
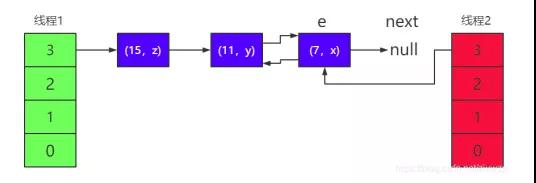
3)首先是线程 2 过来,按照扩容的底层源码,需要将 e 指针指向链表 的头节点(7,x),next 指针指向下一个节点(11,y),如下图所 示:
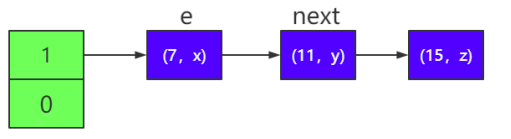
其中 e 表示当前线程正要迁移的节点,next 表示下一个需要迁移 的节点。如果 e 指向的节点迁移完成,则进入下一次循环,e 指针重新指 向节点(11,y),next 指针重新指向节点(15,z)。
4)但是当线程 2 刚开始标记好 e 和 next 两个指针,正准备迁移第一 个节点时。线程 1 过来了,并完成了迁移。
5)前面我们说过,HashMap 进入链表是采用头插法,所以对三个元 素 rehash 迁移后的链表顺序为(15,z) —> (11,y) —> (7,x) 图中的 e 和 next 指针属于线程
2,它们还停留在原来的节点上, 这一阶段的结构如下图所示:
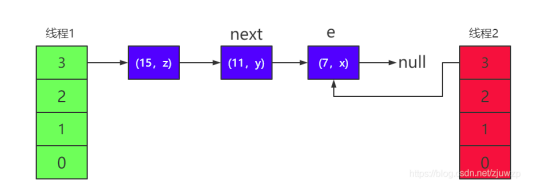
这时线程 2 中的 table 有(7,x)这个节点。
6)然后将 next 指向的节点(11, y)添加到线程 2 表示的 HashMap 中,因为采用头插法,所以(11, y)成了链表的头节点,原来的(7, x)则成了它的下一个节点
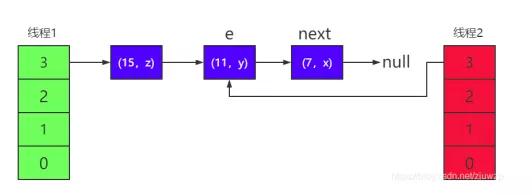
这时线程 2 中的 table 有(11,y)---->(7,x)这些节点,链 表的头节点为(11,y)。
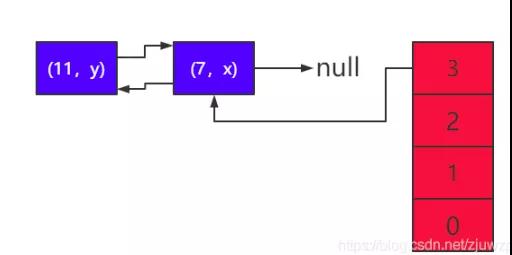
7)继续循环迁移元素,将 e 指向(7,x),则 next 为 null。然后将 线程 2 的数组下标索引 3 指向 e 指向的节点,即将(7,x)又添加到 头节点(头插法),这时线程 2 中的 table 有(7,x)—>(11,y) ---->(7,x),构成了环,如图所示:
6、问题很严重
如果上述的迁移过程最后以线程 2 的 table 作为新的 hashmap, 则最后的迁移结果如下图所示:
7、环形链表会带来什么后果呢?
假设我现在要查询上述 HashMap 是否包含节点(7,x),首先根 据 hash 运算得到目标 index 为 3,所以查找目标转到了 3 号链表,
然后根据 key 值为 11 判断与链表的头节点(7,x)的 key 恰好相等,再 判断它们的 value 也相等。说明该 HashMap 中包含了我们所要查询 的几点,返回 true。
假设我现在要查询节点(11,y),经过 hash 运算也将查找目标转 到了 3 号链表,然后根据 key 值为 11 判断与头节点(7,x)的 key 不 相等,则转向下一个节点。
通过对比,发现与下一个节点的 key 和 value 都相等,则直接返回 true。
这样看来似乎没什么问题,然后我们再查一个节点(15,m),经 过 hash 运算也将查找目标转到了 3 号链表,首先与头节点(7,x)判断 不相等,然后与下一个节点(11,y)对比也不相等。再与下一个节点 判断,这时链表中节点为(7,x)其实就是重新回到了头节点,
它的下一 个节点又是(11,y),这种搜索会一直无限循环下去,CPU 很快飙 升到 100%,后果很严重。其实不管你搜索什么节点,只要路由到 3 号链表,并且待搜索的 key 不是 7 或 11,都将发生死循环。