前言
前面我们介绍了线程池框架(ExecutorService)的两个具体实现:
- ThreadPoolExecutor 默认线程池
- ScheduledThreadPoolExecutor定时线程池
线程池为线程生命周期的开销和资源不足问题提供了解决方案。通过对多个任务重用线程,线程创建的开销被分摊到多个任务上。Java7 又提供了的一个用于并行执行的任务的框架 Fork/Join ,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。在介绍Fork/Join 框架之前我们先了解几个概念:CPU密集型、IO密集型,再逐步深入去认识Fork/Join 框架。
任务性质类型
CPU密集型(CPU bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对于CPU要好很好多,此时,系统运作大部分的状况是 CPU Loading 100%,CPU要读/写 I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部分时间用来做计算、逻辑判断等CPU动作的程序称之 CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部分时间在用三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽了等待I/O的时间。
- 线程数一般设置为:线程数 = CPU核数 + 1(现代CPU支持超线程)
IO密集型(I/O bound)
I/O密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O(硬盘/内存)的读/写操作,此时 CPU Loading 并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而 pipeline 做的不是很好,没有充分利用处理器能力。
- 线程数一般设置为:线程数 = ((线程等待时间 + 线程CPU时间) / 线程CPU时间) * CPU数目
CPU密集型 VS I/O密集型
我们可以把任务分为计算密集型和I/O密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是I/O密集型,涉及到网络、磁盘I/O的任务都是I/O密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待I/O操作完成(因为I/O的速度远远低于CPU和内存的速度)。对于I/O密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是I/O密集型任务,比如Web应用。
I/O密集型任务执行期间,99%的时间都花在I/O上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于I/O密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
什么是 Fork/Join 框架?
Fork/Join 框架是 Java7 提供了的一个用于并行执行的任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
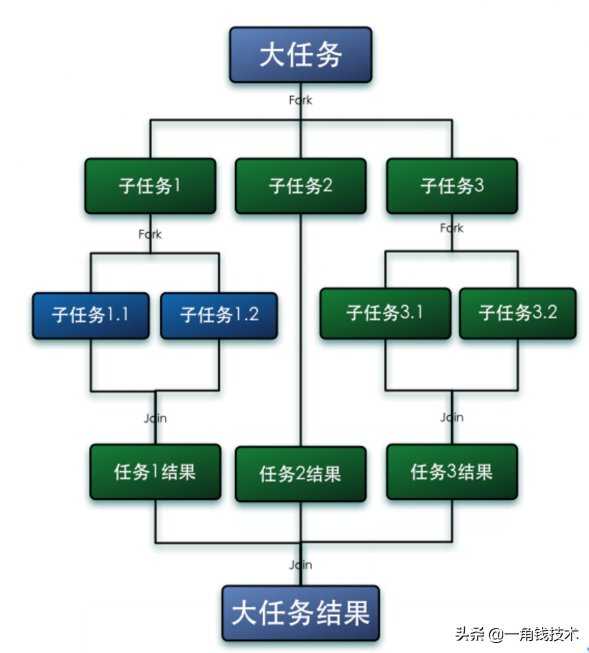
Fork 就是把一个大任务切分为若干个子任务并行的执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算 1+2+......+10000,可以分割成10个子任务,每个子任务对1000个数进行求和,最终汇总这10个子任务的结果。如下图所示:
Fork/Join的特性:
- ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。(见 Java Tip: When to use ForkJoinPool vs ExecutorService )
- ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等;
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O、线程间同步、sleep() 等会造成线程长时间阻塞的情况时,最好配合 MangedBlocker。
关于“分而治之”的算法,可以查看《分治、回溯的实现和特性》
工作窃取算法
工作窃取(work-stealing)算法 是指某个线程从其他队列里窃取任务来执行。
我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。
但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。

工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
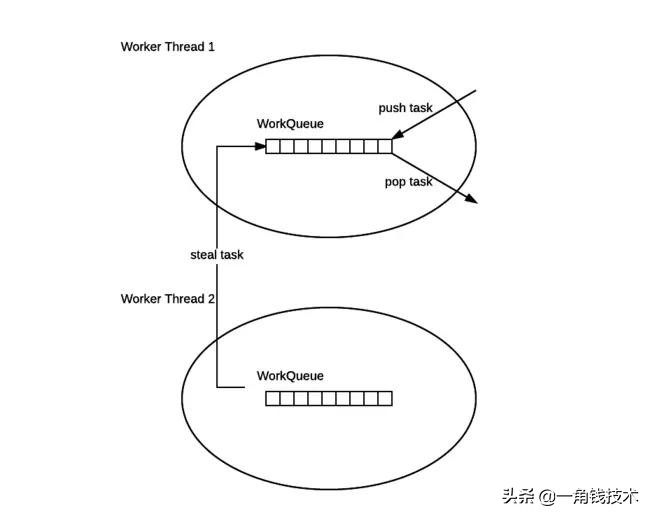
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
- 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
- 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
Fork/Join的使用
使用场景示例
定义fork/join任务,如下示例,随机生成2000w条数据在数组当中,然后求和_
- package com.niuh.forkjoin.recursivetask;
- import java.util.concurrent.RecursiveTask;
- /**
- * RecursiveTask 并行计算,同步有返回值
- * ForkJoin框架处理的任务基本都能使用递归处理,比如求斐波那契数列等,但递归算法的缺陷是:
- * 一只会只用单线程处理,
- * 二是递归次数过多时会导致堆栈溢出;
- * ForkJoin解决了这两个问题,使用多线程并发处理,充分利用计算资源来提高效率,同时避免堆栈溢出发生。
- * 当然像求斐波那契数列这种小问题直接使用线性算法搞定可能更简单,实际应用中完全没必要使用ForkJoin框架,
- * 所以ForkJoin是核弹,是用来对付大家伙的,比如超大数组排序。
- * 最佳应用场景:多核、多内存、可以分割计算再合并的计算密集型任务
- */
- class LongSum extends RecursiveTask<Long> {
- //任务拆分的最小阀值
- static final int SEQUENTIAL_THRESHOLD = 1000;
- static final long NPS = (1000L * 1000 * 1000);
- static final boolean extraWork = true; // change to add more than just a sum
- int low;
- int high;
- int[] array;
- LongSum(int[] arr, int lo, int hi) {
- array = arr;
- low = lo;
- high = hi;
- }
- /**
- * fork()方法:将任务放入队列并安排异步执行,一个任务应该只调用一次fork()函数,除非已经执行完毕并重新初始化。
- * tryUnfork()方法:尝试把任务从队列中拿出单独处理,但不一定成功。
- * join()方法:等待计算完成并返回计算结果。
- * isCompletedAbnormally()方法:用于判断任务计算是否发生异常。
- */
- protected Long compute() {
- if (high - low <= SEQUENTIAL_THRESHOLD) {
- long sum = 0;
- for (int i = low; i < high; ++i) {
- sum += array[i];
- }
- return sum;
- } else {
- int mid = low + (high - low) / 2;
- LongSum left = new LongSum(array, low, mid);
- LongSum right = new LongSum(array, mid, high);
- left.fork();
- right.fork();
- long rightAns = right.join();
- long leftAns = left.join();
- return leftAns + rightAns;
- }
- }
- }
执行fork/join任务
- package com.niuh.forkjoin.recursivetask;
- import com.niuh.forkjoin.utils.Utils;
- import java.util.concurrent.ForkJoinPool;
- import java.util.concurrent.ForkJoinTask;
- public class LongSumMain {
- //获取逻辑处理器数量
- static final int NCPU = Runtime.getRuntime().availableProcessors();
- /**
- * for time conversion
- */
- static final long NPS = (1000L * 1000 * 1000);
- static long calcSum;
- static final boolean reportSteals = true;
- public static void main(String[] args) throws Exception {
- int[] array = Utils.buildRandomIntArray(2000000);
- System.out.println("cpu-num:" + NCPU);
- //单线程下计算数组数据总和
- long start = System.currentTimeMillis();
- calcSum = seqSum(array);
- System.out.println("seq sum=" + calcSum);
- System.out.println("singgle thread sort:->" + (System.currentTimeMillis() - start));
- start = System.currentTimeMillis();
- //采用fork/join方式将数组求和任务进行拆分执行,最后合并结果
- LongSum ls = new LongSum(array, 0, array.length);
- ForkJoinPool fjp = new ForkJoinPool(NCPU); //使用的线程数
- ForkJoinTask<Long> task = fjp.submit(ls);
- System.out.println("forkjoin sum=" + task.get());
- System.out.println("singgle thread sort:->" + (System.currentTimeMillis() - start));
- if (task.isCompletedAbnormally()) {
- System.out.println(task.getException());
- }
- fjp.shutdown();
- }
- static long seqSum(int[] array) {
- long sum = 0;
- for (int i = 0; i < array.length; ++i) {
- sum += array[i];
- }
- return sum;
- }
- }
Fork/Join框架原理
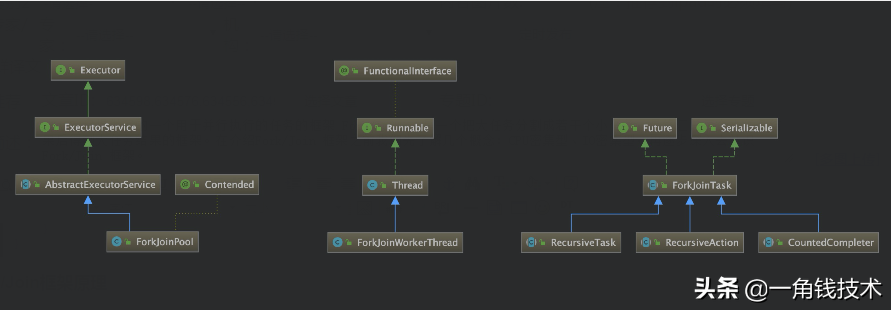
Fork/Join 其实就是指由ForkJoinPool作为线程池、ForkJoinTask(通常实现其三个抽象子类)为任务、ForkJoinWorkerThread作为执行任务的具体线程实体这三者构成的任务调度机制。
ForkJoinWorkerThread
ForkJoinWorkerThread 直接继承了Thread,但是仅仅是为了增加一些额外的功能,并没有对线程的调度执行做任何更改。

ForkJoinWorkerThread 是被ForkJoinPool管理的工作线程,在创建出来之后都被设置成为了守护线程,由它来执行ForkJoinTasks。该类主要为了维护创建线程实例时通过ForkJoinPool为其创建的任务队列,与其他两个线程池整个线程池只有一个任务队列不同,ForkJoinPool管理的所有工作线程都拥有自己的工作队列,为了实现任务窃取机制,该队列被设计成一个双端队列,而ForkJoinWorkerThread的首要任务就是执行自己的这个双端任务队列中的任务,其次是窃取其他线程的工作队列,以下是其代码片段:
- public class ForkJoinWorkerThread extends Thread {
- // 这个线程工作的ForkJoinPool池
- final ForkJoinPool pool;
- // 这个线程拥有的工作窃取机制的工作队列
- final ForkJoinPool.WorkQueue workQueue;
- //创建在给定ForkJoinPool池中执行的ForkJoinWorkerThread。
- protected ForkJoinWorkerThread(ForkJoinPool pool) {
- // Use a placeholder until a useful name can be set in registerWorker
- super("aForkJoinWorkerThread");
- this.pool = pool;
- //向ForkJoinPool执行池注册当前工作线程,ForkJoinPool为其分配一个工作队列
- this.workQueue = pool.registerWorker(this);
- }
- //该工作线程的执行内容就是执行工作队列中的任务
- public void run() {
- if (workQueue.array == null) { // only run once
- Throwable exception = null;
- try {
- onStart();
- pool.runWorker(workQueue); //执行工作队列中的任务
- } catch (Throwable ex) {
- exception = ex; //记录异常
- } finally {
- try {
- onTermination(exception);
- } catch (Throwable ex) {
- if (exception == null)
- exception = ex;
- } finally {
- pool.deregisterWorker(this, exception); //撤销工作
- }
- }
- }
- }
- .....
- }
ForkJoinTask
ForkJoinTask :与FutureTask一样, ForkJoinTask也是Future的子类,不过它是一个抽象类。
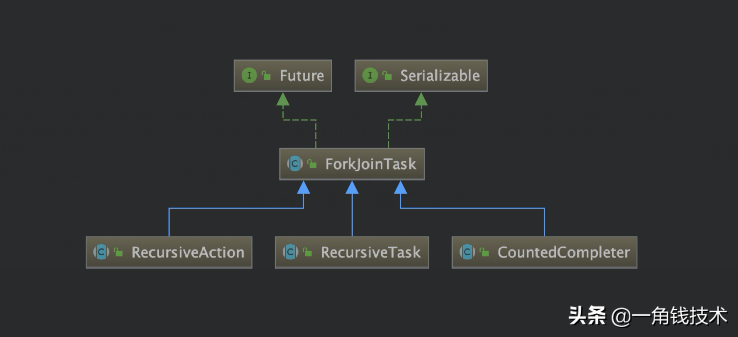
ForkJoinTask :我们要使用 ForkJoin 框架,必须首先创建一个 ForkJoin 任务。它提供在任务中执行 fork() 和 join() 操作的机制,通常情况下我们不需要直接继承 ForkJoinTask 类,而只需要继承它的子类,Fork/Join框架提供类以下几个子类:
- RecursiveAction:用于没有返回结果的任务。(比如写数据到磁盘,然后就退出。一个 RecursiveAvtion 可以把直接的工作分割成更小的几块,这样它们可以由独立的线程或者 CPU 执行。我们可以通过继承来实现一个 RecusiveAction)
- RescursiveTask:用于有返回结果的任务。(可以将自己的工作分割为若干更小任务,并将这些子任务的执行合并到一个集体结果。可以有几个水平的分割和合并)
- CountedCompleter :在任务完成执行后会触发执行一个自定义的钩子函数。
常量介绍
ForkJoinTask 有一个int类型的status字段:
- 其高16位存储任务执行状态例如NORMAL、CANCELLED或EXCEPTIONAL
- 低16位预留用于用户自定义的标记。
任务未完成之前status大于等于0,完成之后就是NORMAL、CANCELLED或EXCEPTIONAL这几个小于0的值,这几个值也是按大小顺序的:0(初始状态) > NORMAL > CANCELLED > EXCEPTIONAL.
- public abstract class ForkJoinTask<V> implements Future<V>, Serializable {
- /** 该任务的执行状态 */
- volatile int status; // accessed directly by pool and workers
- static final int DONE_MASK = 0xf0000000; // mask out non-completion bits
- static final int NORMAL = 0xf0000000; // must be negative
- static final int CANCELLED = 0xc0000000; // must be < NORMAL
- static final int EXCEPTIONAL = 0x80000000; // must be < CANCELLED
- static final int SIGNAL = 0x00010000; // must be >= 1 << 16
- static final int SMASK = 0x0000ffff; // short bits for tags
- // 异常哈希表
- //被任务抛出的异常数组,为了报告给调用者。因为异常很少见,所以我们不直接将它们保存在task对象中,而是使用弱引用数组。注意,取消异常不会出现在数组,而是记录在statue字段中
- //注意这些都是 static 类属性,所有的ForkJoinTask共用的。
- private static final ExceptionNode[] exceptionTable; //异常哈希链表数组
- private static final ReentrantLock exceptionTableLock;
- private static final ReferenceQueue<Object> exceptionTableRefQueue; //在ForkJoinTask被GC回收之后,相应的异常节点对象的引用队列
- /**
- * 固定容量的exceptionTable.
- */
- private static final int EXCEPTION_MAP_CAPACITY = 32;
- //异常数组的键值对节点。
- //该哈希链表数组使用线程id进行比较,该数组具有固定的容量,因为它只维护任务异常足够长,以便参与者访问它们,所以在持续的时间内不应该变得非常大。但是,由于我们不知道最后一个joiner何时完成,我们必须使用弱引用并删除它们。我们对每个操作都这样做(因此完全锁定)。此外,任何ForkJoinPool池中的一些线程在其池变为isQuiescent时都会调用helpExpungeStaleExceptions
- static final class ExceptionNode extends WeakReference<ForkJoinTask<?>> {
- final Throwable ex;
- ExceptionNode next;
- final long thrower; // 抛出异常的线程id
- final int hashCode; // 在弱引用消失之前存储hashCode
- ExceptionNode(ForkJoinTask<?> task, Throwable ex, ExceptionNode next) {
- super(task, exceptionTableRefQueue); //在ForkJoinTask被GC回收之后,会将该节点加入队列exceptionTableRefQueue
- this.ex = ex;
- this.next = next;
- this.thrower = Thread.currentThread().getId();
- this.hashCode = System.identityHashCode(task);
- }
- }
- .................
- }
除了status记录任务的执行状态之外,其他字段主要是为了对任务执行的异常的处理,ForkJoinTask采用了哈希数组 + 链表的数据结构(JDK8以前的HashMap实现方法)存放所有(因为这些字段是static)的ForkJoinTask任务的执行异常。
fork 方法(安排任务异步执行)
fork() 做的工作只有一件事,既是把任务推入当前工作线程的工作队列里(安排任务异步执行)。可以参看以下的源代码:
- public final ForkJoinTask<V> fork() {
- Thread t;
- if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
- ((ForkJoinWorkerThread)t).workQueue.push(this);
- else
- ForkJoinPool.common.externalPush(this);
- return this;
- }
该方法其实就是将任务通过push方法加入到当前工作线程的工作队列或者提交队列(外部非ForkJoinWorkerThread线程通过submit、execute方法提交的任务),等待被线程池调度执行,这是一个非阻塞的立即返回方法。
- 这里需要知道,ForkJoinPool线程池通过哈希数组+双端队列的方式将所有的工作线程拥有的任务队列和从外部提交的任务分别映射到哈希数组的不同槽位上。
join 方法(等待执行结果)
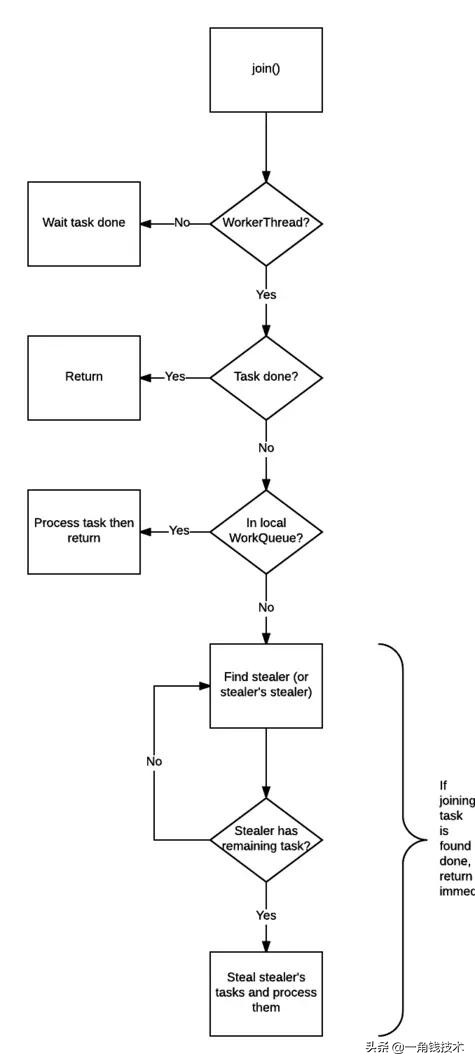
join() 的工作则复杂得多,也是 join() 可以使得线程免于被阻塞的原因——不像同名的 Thread.join()。
- 检查调用 join() 的线程是否是 ForkJoinThread 线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞。
- 查看任务的完成状态,如果已经完成,直接返回结果。
- 如果任务尚未完成,但处于自己的工作队列内,则完成它。
- 如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式),执行,以期帮助它早日完成 join 的任务。
- 如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 join 的任务时,则找到小偷的小偷,帮助它完成它的任务。
- 递归地执行第5步。
将上述流程画成序列图的话就是这个样子:
由于文章篇幅有限,源码分析请查看文章末尾的“了解更多”
小结
通常ForkJoinTask只适用于非循环依赖的纯函数的计算或孤立对象的操作,否则,执行可能会遇到某种形式的死锁,因为任务循环地等待彼此。但是,这个框架支持其他方法和技术(例如使用Phaser、helpQuiesce和complete),这些方法和技术可用于构造解决这种依赖任务的ForkJoinTask子类,为了支持这些用法,可以使用setForkJoinTaskTag或compareAndSetForkJoinTaskTag原子性地标记一个short类型的值,并使用getForkJoinTaskTag进行检查。ForkJoinTask实现没有将这些受保护的方法或标记用于任何目的,但是它们可以用于构造专门的子类,由此可以使用提供的方法来避免重新访问已经处理过的节点/任务。
ForkJoinTask应该执行相对较少的计算,并且应该避免不确定的循环。大任务应该被分解成更小的子任务,通常通过递归分解。如果任务太大,那么并行性就不能提高吞吐量。如果太小,那么内存和内部任务维护开销可能会超过处理开销。
ForkJoinTask是可序列化的,这使它们能够在诸如远程执行框架之类的扩展中使用。只在执行之前或之后序列化任务才是明智的,而不是在执行期间。
ForkJoinPool
ForkJoinPool:ForkJoinTask 需要通过 ForkJoinPool 来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
常量介绍
ForkJoinPool 与 内部类 WorkQueue 共享的一些常量
- // Constants shared across ForkJoinPool and WorkQueue
- // 限定参数
- static final int SMASK = 0xffff; // 低位掩码,也是最大索引位
- static final int MAX_CAP = 0x7fff; // 工作线程最大容量
- static final int EVENMASK = 0xfffe; // 偶数低位掩码
- static final int SQMASK = 0x007e; // workQueues 数组最多64个槽位
- // ctl 子域和 WorkQueue.scanState 的掩码和标志位
- static final int SCANNING = 1; // 标记是否正在运行任务
- static final int INACTIVE = 1 << 31; // 失活状态 负数
- static final int SS_SEQ = 1 << 16; // 版本戳,防止ABA问题
- // ForkJoinPool.config 和 WorkQueue.config 的配置信息标记
- static final int MODE_MASK = 0xffff << 16; // 模式掩码
- static final int LIFO_QUEUE = 0; // LIFO队列
- static final int FIFO_QUEUE = 1 << 16; // FIFO队列
- static final int SHARED_QUEUE = 1 << 31; // 共享模式队列,负数 ForkJoinPool 中的相关常量和实例字段:
ForkJoinPool 中的相关常量和实例字段
- // 低位和高位掩码
- private static final long SP_MASK = 0xffffffffL;
- private static final long UC_MASK = ~SP_MASK;
- // 活跃线程数
- private static final int AC_SHIFT = 48;
- private static final long AC_UNIT = 0x0001L << AC_SHIFT; //活跃线程数增量
- private static final long AC_MASK = 0xffffL << AC_SHIFT; //活跃线程数掩码
- // 工作线程数
- private static final int TC_SHIFT = 32;
- private static final long TC_UNIT = 0x0001L << TC_SHIFT; //工作线程数增量
- private static final long TC_MASK = 0xffffL << TC_SHIFT; //掩码
- private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // 创建工作线程标志
- // 池状态
- private static final int RSLOCK = 1;
- private static final int RSIGNAL = 1 << 1;
- private static final int STARTED = 1 << 2;
- private static final int STOP = 1 << 29;
- private static final int TERMINATED = 1 << 30;
- private static final int SHUTDOWN = 1 << 31;
- // 实例字段
- volatile long ctl; // 主控制参数
- volatile int runState; // 运行状态锁
- final int config; // 并行度|模式
- int indexSeed; // 用于生成工作线程索引
- volatile WorkQueue[] workQueues; // 主对象注册信息,workQueue
- final ForkJoinWorkerThreadFactory factory;// 线程工厂
- final UncaughtExceptionHandler ueh; // 每个工作线程的异常信息
- final String workerNamePrefix; // 用于创建工作线程的名称
- volatile AtomicLong stealCounter; // 偷取任务总数,也可作为同步监视器
- /** 静态初始化字段 */
- //线程工厂
- public static final ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory;
- //启动或杀死线程的方法调用者的权限
- private static final RuntimePermission modifyThreadPermission;
- // 公共静态pool
- static final ForkJoinPool common;
- //并行度,对应内部common池
- static final int commonParallelism;
- //备用线程数,在tryCompensate中使用
- private static int commonMaxSpares;
- //创建workerNamePrefix(工作线程名称前缀)时的序号
- private static int poolNumberSequence;
- //线程阻塞等待新的任务的超时值(以纳秒为单位),默认2秒
- private static final long IDLE_TIMEOUT = 2000L * 1000L * 1000L; // 2sec
- //空闲超时时间,防止timer未命中
- private static final long TIMEOUT_SLOP = 20L * 1000L * 1000L; // 20ms
- //默认备用线程数
- private static final int DEFAULT_COMMON_MAX_SPARES = 256;
- //阻塞前自旋的次数,用在在awaitRunStateLock和awaitWork中
- private static final int SPINS = 0;
- //indexSeed的增量
- private static final int SEED_INCREMENT = 0x9e3779b9;
ForkJoinPool 的内部状态都是通过一个64位的 long 型 变量ctl来存储,它由四个16位的子域组成:
- AC: 正在运行工作线程数减去目标并行度,高16位
- TC: 总工作线程数减去目标并行度,中高16位
- SS: 栈顶等待线程的版本计数和状态,中低16位
- ID: 栈顶 WorkQueue 在池中的索引(poolIndex),低16位
ForkJoinPool.WorkQueue 中的相关属性:
- //初始队列容量,2的幂
- static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
- //最大队列容量
- static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
- // 实例字段
- volatile int scanState; // Woker状态, <0: inactive; odd:scanning
- int stackPred; // 记录前一个栈顶的ctl
- int nsteals; // 偷取任务数
- int hint; // 记录偷取者索引,初始为随机索引
- int config; // 池索引和模式
- volatile int qlock; // 1: locked, < 0: terminate; else 0
- volatile int base; // 下一个poll操作的索引(栈底/队列头)
- int top; // 一个push操作的索引(栈顶/队列尾)
- ForkJoinTask<?>[] array; // 任务数组
- final ForkJoinPool pool; // the containing pool (may be null)
- final ForkJoinWorkerThread owner; // 当前工作队列的工作线程,共享模式下为null
- volatile Thread parker; // 调用park阻塞期间为owner,其他情况为null
- volatile ForkJoinTask<?> currentJoin; // 记录被join过来的任务
- volatile ForkJoinTask<?> currentSteal; // 记录从其他工作队列偷取过来的任务
内部数据结构
ForkJoinPool采用了哈希数组 + 双端队列的方式存放任务,但这里的任务分为两类:
- 一类是通过execute、submit 提交的外部任务
- 另一类是ForkJoinWorkerThread工作线程通过fork/join分解出来的工作任务
ForkJoinPool并没有把这两种任务混在一个任务队列中,对于外部任务,会利用Thread内部的随机probe值映射到哈希数组的偶数槽位中的提交队列中,这种提交队列是一种数组实现的双端队列称之为Submission Queue,专门存放外部提交的任务。
对于ForkJoinWorkerThread工作线程,每一个工作线程都分配了一个工作队列,这也是一个双端队列,称之为Work Queue,这种队列都会被映射到哈希数组的奇数槽位,每一个工作线程fork/join分解的任务都会被添加到自己拥有的那个工作队列中。
在ForkJoinPool中的属性 WorkQueue[] workQueues 就是我们所说的哈希数组,其元素就是内部类WorkQueue实现的基于数组的双端队列。该哈希数组的长度为2的幂,并且支持扩容。如下就是该哈希数组的示意结构图:
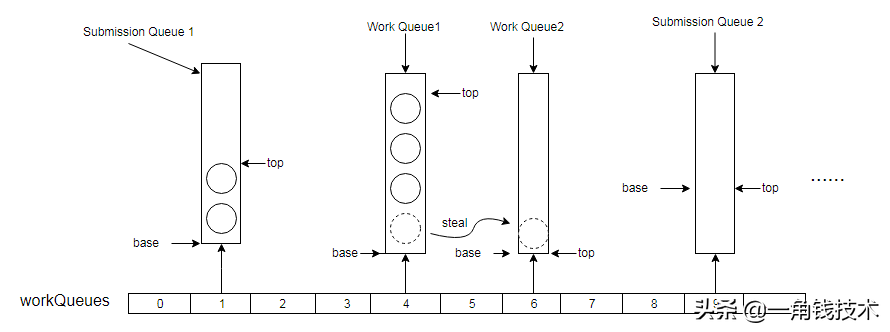
如图,提交队列位于哈希数组workQueue的奇数索引槽位,工作线程的工作队列位于偶数槽位。
- 默认情况下,asyncMode为false时:因此工作线程把工作队列当着栈一样使用(后进先出),将分解的子任务推入工作队列的top端,取任务的时候也从top端取(凡是双端队列都会有两个分别指向队列两端的指针,这里就是图上画出的base和top);而当某些工作线程的任务为空的时候,就会从其他队列(不限于workQueue,也会是提交队列)窃取(steal)任务,如图示拥有workQueue2的工作线程从workQueue1中窃取了一个任务,窃取任务的时候采用的是先进先出FIFO的策略(即从base端窃取任务),这样不但可以避免在取任务的时候与拥有其队列的工作线程发生冲突,从而减小竞争,还可以辅助其完成比较大的任务。
- asyncMode为true的话,拥有该工作队列的工作线程将按照先进先出的策略从base端取任务,这一般只用于不需要返回结果的任务,或者事件消息传递框架。
ForkJoinPool构造函数
其完整构造方法如下
- private ForkJoinPool(int parallelism,
- ForkJoinWorkerThreadFactory factory,
- UncaughtExceptionHandler handler,
- int mode,
- String workerNamePrefix) {
- this.workerNamePrefix = workerNamePrefix;
- this.factory = factory;
- this.ueh = handler;
- this.config = (parallelism & SMASK) | mode;
- long np = (long)(-parallelism); // offset ctl counts
- this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
- }
重要参数解释
- parallelism:并行度( the parallelism level),默认情况下跟我们机器的cpu个数保持一致,使用 Runtime.getRuntime().availableProcessors()可以得到我们机器运行时可用的CPU个数。
- factory:创建新线程的工厂( the factory for creating new threads)。默认情况下使用ForkJoinWorkerThreadFactory defaultForkJoinWorkerThreadFactory。
- handler:线程异常情况下的处理器(Thread.UncaughtExceptionHandler handler),该处理器在线程执行任务时由于某些无法预料到的错误而导致任务线程中断时进行一些处理,默认情况为null。
- asyncMode:这个参数要注意,在ForkJoinPool中,每一个工作线程都有一个独立的任务队列
- asyncMode表示工作线程内的任务队列是采用何种方式进行调度,可以是先进先出FIFO,也可以是后进先出LIFO。如果为true,则线程池中的工作线程则使用先进先出方式进行任务调度,默认情况下是false。
ForkJoinPool.submit 方法
- public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task) {
- if (task == null)
- throw new NullPointerException();
- //提交到工作队列
- externalPush(task);
- return task;
- }
ForkJoinPool 自身拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 ForkJoinThread 线程)提交过来的任务,而这些工作队列被称为 submitting queue 。 submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
PS:以上代码提交在 Github :
https://github.com/Niuh-Study/niuh-juc-final.git