监控平台,服务治理,调用链跟踪,数据收集中心,自动化测试… 很多公司在搞技术体系平台化。可如果连第一步“集群信息集中管理”都没做到,谈平台化为时尚早。
今天,和大家聊聊技术体系平台化的基石,集群信息集中管理。
什么是集群?
互联网典型分层架构如下:
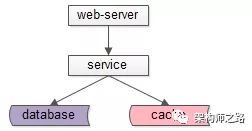
- web-server层;
- service层;
- db层与cache层;
为了保证高可用,每一个站点、服务、数据库、缓存都会冗余多个实例,组成一个分布式的系统,集群则是一个分布式的物理形态。
更通俗的说,集群就是一堆机器,上面部署了提供相似功能的站点,服务,数据库,或者缓存。
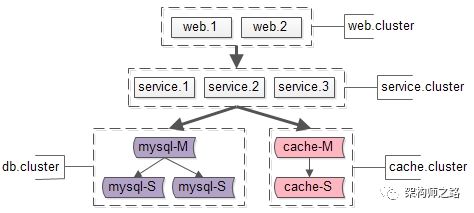
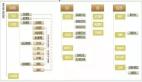
如上图:
- web集群,由web.1和web.2两个实例组成;
- service集群,由service.1/service.2/service.3三个实例组成;
- db集群,由mysql-M/mysql-S1/mysql-S2三个实例组成;
- cache集群,由cache-M/cache-S两个实例组成;
与“集群”相对应的是“单机”。
画外音:缓存如果没有高可用要求,可以是单机架构,而不用非得是集群。
什么是集群信息?
一个集群,会包含若干信息(额,这算什么解释),例如:集群名称,节点IP列表,二进制目录,配置目录,日志目录,负责人列表等,这些就是集群信息。
画外音:集群节点IP列表,往往不是内外IP列表,是内网域名列表。
什么时候会用到集群信息呢?
很多场景,特别是线上操作,都会使用到各种集群信息,例如:自动化上线,监控,日志清理,二进制与配置的备份,下游的调用等,都会用到集群信息。
这些场景,分别都是如何读取集群信息的?
一般来说,早期会把集群信息写在配置文件里。
例如,自动化上线,有一个配置文件,deploy.user.service.config,其内容是:
- name : user.service
- ip.list : ip1, ip2, ip3
- bin.path : /user.service/bin/
- ftp.path : ftp://192.168.0.1/USER_2_0_1_3/user.exe
自动化上线的过程,则是:
- 把可执行文件从ftp拉下来;
- 读取集群IP列表;
- 读取二进制应该部署的目录;
- 把二进制部署到线上;
- 逐台重启;
画外音:还没有实现自动化脚本部署?赶紧照着这个流程,做自动化改造吧。
又例如,web-X调用下游的user服务,又有一个配置文件,web-X.config,其内容配置了:
- service.name : user.service
- service.ip.list : ip1, ip2, ip3
- service.port : 8080
web-X调用user服务的过程,则是:
- web-X启动;
- web-X读取user服务集群的IP列表与端口;
- web-X初始化user服务连接池;
- web-X拿取user服务的连接,通过RPC接口调用user服务;
日志清理,服务监控,二进制备份的过程,也都与上述类似。
上述方案存在什么问题?
上述业务场景,对于集群信息的使用,有两个最大的特点:
- 每个应用场景,所需集群信息都不一样(A场景需要集群abc信息,B场景需要集群def信息);
- 每个应用场景,集群信息都写在“自己”的配置文件里;
一句话总结:集群信息管理分散化。
这里最大的问题,是耦合,当集群的信息发生变化的时候,有非常多的配置需要修改:
- deploy.user.service.config
- clean.log.user.service.config
- backup.bin.user.service.config
- monitor.config
- web-X.config
- …
这些配置里,user服务集群的信息都需要修改:
- 随着研发、测试、运维人员的流动,很多配置放在哪里,逐步就被遗忘了;
- 随着时间的推移,一些配置就被改漏了;
- 逐渐的,莫名其妙的问题出现了;
画外音:ca,谁痛谁知道。
如何解决上述耦合的问题呢?
一句话回答:集群信息管理集中化。
如何集中化管理集群信息呢?
不同发展阶段的公司,实现的方式不一样。
早期方案:全局配置。通
过全局配置文件,实现集群信息集中管理,举例global.config如下:
- [user.service]
- ip.list : ip1, ip2, ip3
- port : 8080
- bin.path : /user.service/bin/
- log.path : /user.service/log/
- conf.path : /user.service/conf/
- owner.list : shenjian, ku
- [passport.web]
- ip.list : ip11, ip22, ip33
- port : 80
- bin.path : /passport.web/bin/
- log.path : /passport.web/log/
- conf.path : /passport.web/conf/
- owner.list : shenjian, shuai
集中维护集群信息之后:
- 任何需要读取集群信息的场景,都从global.config里读取;
- 任何集群信息的修改,只需要修改global.config一处;
- global.config会部署到任何一台线上机器,维护和管理也很方便;
画外音:信息太多的话,global.config也要垂直拆分。
中期方案:服务化。
随着公司业务的发展,随着技术团队的扩充,随着技术体系的完善,通过集群信息管理服务,来维护集群信息的诉求原来越强烈。
画外音:慢慢的,配置太多了,通过global.config来修改配置太容易出错了。
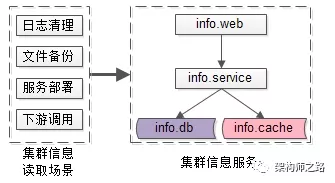
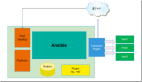
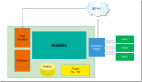
如上图,建立集群信息管理服务:
- info.db :存储集群信息;
- info.cache :缓存集群信息;
- info.service :提供集群信息访问的RPC接口,以及HTTP接口;
- info.web :集群信息维护后台;
服务的核心接口是:
- Info InfoService::getInfo(String ClusterName);
- Bool InfoService::setInfo(String ClusterName, String key, String value);
然后,统一通过服务来获取与修改集群信息:
- 所有需要获取集群信息的场景,都通过info.service提供的接口来读取集群信息;
- 所有需要修改集群信息的场景,都通过info.web来操作;
长期方案:配置中心平台化。
集群信息服务可以解决大部分的耦合问题,但仍然有一个不足:集群信息变更时,无法反向实时通知关注方,集群信息发生了改变。更长远的,要引入配置中心来解决。
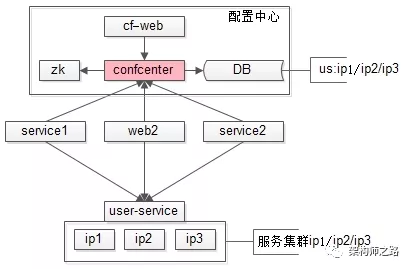
配置中心的细节,网上的分析很多,之前也撰文写过,细节就不再本文展开。
总结
集群信息管理,是架构设计中非常容易遗漏的一环,但又是非常基础,非常重要的基础设施,一定要在早期规划好:
- 传统的方式,分散化管理集群信息,容易导致耦合;
- 集中管理集群信息,有全局配置,信息服务,配置中心三个阶段;
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】