在人工代码评审(Code Review,CR)中,对于纯文本形式的代码浏览不可避免地将耗费大量的时间,影响CR的效率。那么有没有更智能的方法?阿里云云效代码智能语法服务基于云端备份的快速代码导航服务,无须本地克隆即可在页面体验熟悉的定义引用快速查看跳转功能,可大幅提升代码评审的效率和质量。本文分享相关的技术原理与实现方法。
一 前言
代码文本不是简单的二维平面结构,看懂一段代码需要反复地通过定义与引用的跳转,才能将代码深层次的逻辑和片段影响范围理解透彻。纯文本形式的代码浏览是网页端代码评审的最大痛点之一,朱熹老先生常说“心不在此,则眼不看仔细,心眼既不专一,却只漫浪诵读,决不能记,记亦不能久也。”代码文本扁平式地漫浪诵读只能达到眼到、口到的境界,如果你是一个认真负责的代码评审者,阿里云云效代码智能语法服务一定是帮助你充分理解代码变更,超越眼口,到达“心到”境界的功能。心既到矣,眼口岂不到乎?
那么什么是代码智能语法服务呢?语法服务提供了基于云端备份的快速代码导航服务,无须本地克隆即可在页面体验熟悉的定义引用快速查看跳转功能,大幅提升代码评审的效率和质量。
二 技术基础
阿里云云效代码智能语法服务的底层技术是LSIF(Language Server Index Format),它是一种持久化语言的索引的图存储格式,通过图的格式,表示了“代码文档”-> “语法智能结果”之间的事件关系。
在LSIF之前,LSP(Language Server Protocol)定义了编码语言与各类终端代码编辑器之前的交互协议。原先开发者需要为每一款编辑器都定义适配一种语法分析服务应用,那么M个语言要在M个代码编辑器中使用的话需要MxN个应用。而有了LSP的出现,开发者在解析代码语法时只需要遵循LSP协议格式,实现代码补全、定义展示、代码诊断等接口,就只需要开发M+N个应用。
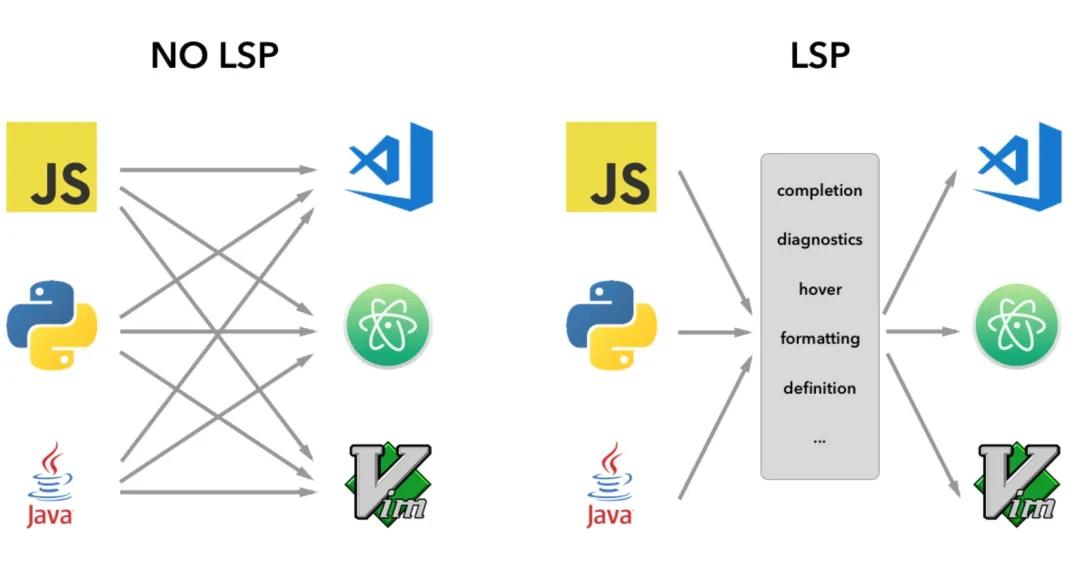
然而代码分析往往需要耗费大量的时间和资源,当用户请求某个语法服务(如查看定义),后端需要克隆代码,下载依赖包,解析语法,构建索引(类比一下IntelliJ Idea初始化工程的场景),编辑器场景用户已经习惯于这样的方式,等待几分钟或许问题不大。但CR场景或者轻量级的代码浏览场景,这种方式就显得时效性比较低了,几分钟后或许用户已经完成了代码浏览,而且缺少持久化的存储会导致资源过度消耗。于是,LSIF就在这样的背景下应运而生,秉承用空间换时间的思想,提前计算好语法分析结果以特定的索引格式存储在云上,从而快速响应不同用户的多次请求。
援引官方示例来简单介绍下LSIF,如下方代码:
// this is a sample classpublic class Sample {}
假定只有一种交互,当鼠标移动到Sample的类名上,就会出现“this is a sample class”的注释信息。用LSIF的图就可以如下描述。
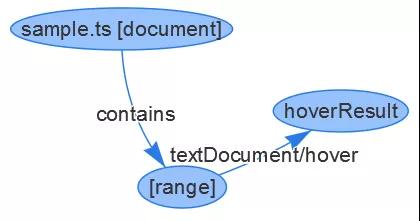
一个sample文件,包含了一个range信息,这个range关联了一个hoverResult。含义是该文件的某个位置范围内,触发hover事件的话,就给出hoverResult存储的结果。
如果用Json文件描述这张图的存储,就可以得到如下结果:
{ id: 1, type: "vertex", label: "document", uri: "file:///abc/sample.java", languageId: "java" }{ id: 2, type: "vertex", label: "range", start: { line: 0, character: 13}, end: { line: 0, character: 18 } }{ id: 3, type: "edge", label: "contains", outV: 1, inVs: [2] }{ id: 4, type: "vertex", label: "hoverResult", result: {["this is a sample class"]} }{ id: 5, type: "edge", label: "textDocument/hover", outV: 2, inV: 4 }
实际一个工程的LSIF图会非常复杂,经常会包含几十万个节点。感兴趣的同学可以参考LSIF具体描述[1]。
三 实现方式
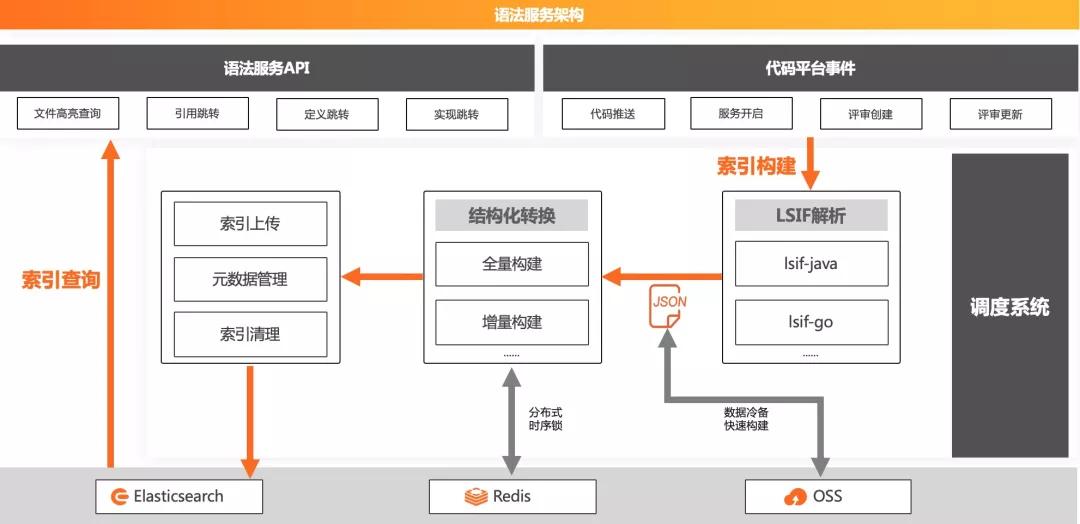
阿里云云效的语法服务架构图主要分为两部分:
基于事件触发的索引构建过程
基于用户请求的语法服务响应
1 索引构建
用户对代码的浏览场景主要集中在代码评审和主干分支的代码浏览,所以我们目前主要支持两种场景的语法服务。语法服务接收来自代码平台的事件消息,如代码推送事件,评审的创建、更新、合并、关闭、重新开启事件,来触发语法服务构建。
我们的构建工作流调度主要基于阿里巴巴开源的分布式调度框架tbschedule,该系统会通过zookeeper维护一个任务集群,通过zookeeper做节点管理和任务分发,不重复不遗漏地快速处理调度任务。
针对不同语言,我们只需要实现一次从源代码到LSIF格式的转换,就能将其应用在多种场景。多种代码语言代码语言都会被解析成统一的LSIF格式文件。
针对阿里巴巴内部主要的Java语言,我们利用开源Java代码解析工具Spoon[2]将Java源代码分析为AST(抽象语法树),然后捕捉定义和引用、定义与注释之间的关联,将坐标信息、注释内容,文本类型,所属文件等信息聚合,输出为统一的LSIF的Json格式。
开发期间修复并适配了一些lsif-java的问题,如位置范围信息错乱,召回多种遗漏的高亮词类型,适配非Maven仓库的索引构建。同时还修复了Spoon关于无法正确解析注释中的部分注解的问题,PR已被Spoon社区接受合并[3]。
生成lsif.json文件后,由于这个Json文件较大,直接由前端加载并响应请求不太合理,后期增量生成与维护难度也很大,所以我们还需要一步:将lsif.json转化为结构化数据,从而按需响应用户查询请求。lsif的图存储格式让人自然地联想到用图数据结构存储,图查询的速度也比较快,然而由于索引变化迭代较快,频繁更换的ID导致图存储难以适配增量方案,不同代码库不同语言的索引数据很难在一张图中结构化,参考了社区的相关实践,考虑到成本和性能,因为ES天然地适合大规模的数据存储和索引,我们最后选择了用ES(Elasticsearch)做结构化数据存储。
我们将这种结构化的数据上传到ES,然后语法服务后端服务器会基于用户的语法请求,构造ES请求Query,查询定义、引用或注释信息,将其拼装返回。
对于分支,我们会持续更新和保留最新版本的索引数据;对于代码评审,我们会构建源分支的每次Push版本和源目标分支的merge-base版本的索引。
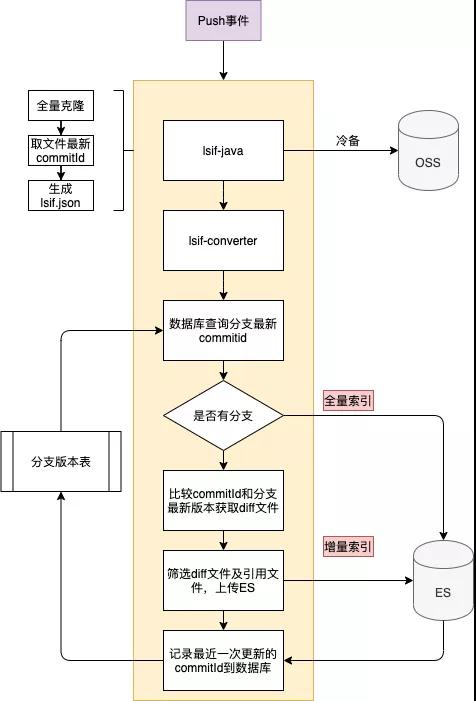
索引构建的另外一个难点是增量计算。如上文所述,语法服务索引构建对资源的要求非常高,而现实中代码库不可避免地会存在频繁提交的现象。如此引申出了两个优化点:
利用增量的方式减少存储内容的变更,加快索引构建速度。
利用分布式时序锁减少频繁请求带来的压力。
增量方案
每次分支索引构建成功,我们都会在数据库中记录分支对应的版本号,当该分支有了一次新的提交后,在生成lsif.json后,系统会比较两个分支的Diff,获取到变更文件和变更类型,通过变更文件来进一步提取索引受到影响的文件(引用或定义的坐标信息变更),分析出所有受影响的文件和对应的ES增删操作后,完成增量索引上传。这个增量的过程平均能减少45%的分支构建时间。
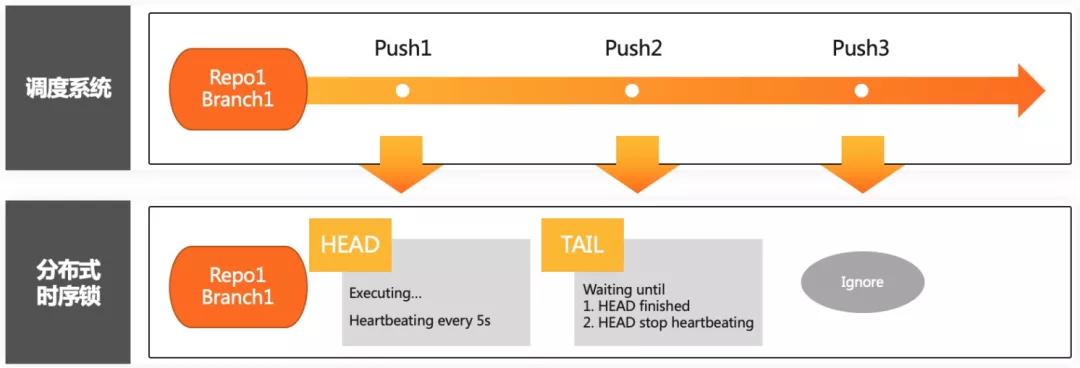
时序锁管理
根据库大小的区别,LSIF的索引构建时间为10秒至数分钟不等,而用户对同一个代码仓库的提交操作峰值可能会达到每分钟近百次,即使我们采用了增量技术也很难满足高频的构建请求,并且提交事件触达和调度任务执行无法保证精准的时序性。综上所述,我们需要一个分布式时序锁来保证任务调度的顺序和尽量减少重复调度。
当同一代码库的不同推动消息纷涌而至,Redis维护的分布式锁会做如下判断:若该库当前没有正在运行的任务,将任务置于队首,立即运行;若已有一个正在执行的任务,比较新来的Push消息是否是最新的,若是,则加入队尾;当队伍已有两个成员时,则将任务丢弃,因为每次执行任务时,系统都会克隆分支代码,基于最新的版本构建索引,如此就避免了多少次Push就需要执行多少次索引构建的可能性。考虑到线程意外退出的情况,队首会每隔5秒钟全局发送心跳,当队尾或新来的任务监听到心跳超时,则会将队首的任务放弃并执行新的任务。
2 语法服务响应
如前言的示例,用户在使用语法服务时,主要有以下三个请求:
每次打开文件获取所有的可点击高亮词
点击高亮词获取对应的定义与引用列表
点击定义和引用实现跳转
针对第一个请求,系统会构造基于文件路径的过滤条件构造ES的Query请求,将当前文件的所有高亮词坐标信息发送给前端,避免了前端做语法分词,没有构建好的文件自然也不会在页面上被高亮出来。另外,为了避免超大文件对ES的压力,前端会做分批动态加载。
针对第二个请求,我们在获取定义与引用列表的过程中,不光要得到文件名和位置信息,还需要将对应的代码内容展示出来,方便用户理解。为了实现这个效果,我们新增了批量获取文件片段的接口。
对于第三个请求,同一个文件内的跳转会自动高亮到对应的代码行,不同文件间的跳转会新开页面并跳转。
语法服务响应和语法索引构建是完全异步的,互不影响,支持独立的资源扩缩。
3 索引清理
语法服务的索引大小约是代码文件内容的数倍,比较消耗存储资源。所以针对用户通常的使用习惯和场景,制定了一系列索引清理任务来避免资源过度的损耗。
当代码评审合并或删除时,当分支删除时,系统会开始执行索引清理任务,释放索引资源。
四 语法服务展望
缺少符号跳转长久以来一直是页面上代码阅读的痛点之一,各种语法协议和技术层出不穷,如LSIF、Kythe、SARIF、UAST、Tree-sitter,ctags,全球技术人都在为更智能的代码分析,更好的代码体验,更高的代码质量做努力。云效语法服务后续也会逐渐加快语法构建速度,支持更多的代码语言,满足更多的语法场景,提升用户的代码浏览体验。
相关链接
[1]https://microsoft.github.io/language-server-protocol/specifications/lsif/0.4.0/specification/
[2]http://spoon.gforge.inria.fr/
[3]https://github.com/INRIA/spoon/pull/3513