本文转载自公众号“读芯术”(ID:AI_Discovery)。
技术快速发展,各种学科中积极使用定量分析,产生了更大量的数据,数据分析的作用已经超过了最初的预期。由于基础设备不断进步,现在可以拥有多个数据源,如传感器、CRMs、事件、文本、图像、音频和视频。
现在的大量数据中,大部分是非结构化的,即没有预定义模型/结构的数据。如图像,是像素的集合,文本数据是没有预定义储存模型的字符序列,以及用户在Web应用程序上操作的点击流。非结构化数据所需要处理的地方在于,需要通过预处理等方法转化为结构化数据,以便对结构化数据应用统计方法获取原始数据中的重要信息。
论及结构数据,主要是指表格数据(矩形结构数据),即数据库中的行和列。这种表格数据包含两种类型的结构化数据:
1. 数值数据
用数字所衡量表述的数据,进一步分为两种表示形式:
- 连续型——数据可以表示时间间隔中的任何值,例如汽车的速度、心率等。
- 离散型——只能接受整数值的数据,如计数值。例如,投掷一枚硬币20次,正面朝上的次数。
2. 分类数据
只能表示可能类别中一组特定的数据。也称为枚举、因子或名词性因子。
- 二进制型,这种分类数据是二进制分类的一种特殊情况,即只有0/1或者说真/假两个值。
- 有序型,有明确前后顺序的分类数据。例如对一家餐馆的五星评价制。(1、2、3、4、5)。
那么问题来了,为什么需要了解这些数据类型呢?因为不知道数据类型,将会不知道如何应用正确的统计方法处理这类数据。举例来说,如果数据框中有一列有序号数据,就必须要进行预处理,在Python中,scikit-learn包提供了一个序号编码器来处理序号数据。
下一步是深入研究结构化数据,以及如何使用第三方工具包和库来操作这些结构。我们主要有两种类型的结构或数据储存模型:
- 矩形
- 非矩形
矩形数据
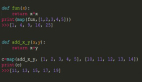
数据科学中大多数的分析对象都是针对二位矩形数据(如数据框、电子表格、CSV文件或是数据库表格)完成。
矩形数据主要由表示数据类型的行和表示列的变量/特性组成。数据框是一种特殊的数据结构,采用表格格式,提供了高效的数据操作可能。数据框是最常用的数据结构,下方是一些重要的定义:
- 数据框:用于统计和机器学习模型的有效操作和应用的矩形数据结构(如电子表格)。
- 特性:数据框的列值通常被称为特性。同义词有(属性、输入值、预测值、变量)。
- 结果:许多数据科学项目都涉及到结果预测——通常输出值yes/no。
- 记录:数据框中的一行通常被成为记录。同义词(实例,模式值,样本值)。
关系数据库表将一个或多个指定的列作为索引,本质上是行号查询。这可以极大程度地提高某些数据库的查询效率,在Panda dataframe中,可以根据行的顺序自动创建一个整数索引。在Pandas中还可以设置多层次索引提高操作效率。
图源:unsplash
非矩形数据
除了矩形数据外,还有一些其他的数据结构属于非矩形数据的范畴。
地理位置分析中使用的空间数据结构更加复杂,不同于矩形数据结构。在地理位置数据中,数据的焦点是一个特定对象(如一个公园)及其空间坐标。相比之下,视场视图聚焦于小的空间单位和相关的度量值。(如像素强度)。
图数据结构,这种数据结构通常用来表示数据间的关系——物理关系、社会关系和抽象关系。例如脸书或推特上以社会关系图的形式表示网络上人们之间的联系。图结构对某些类型的问题特别有用,如网络优化和系统推荐问题。
每种数据类型在数据科学中都有特殊的处理方法,本文重点讲了矩形数据,希望你已经掌握了它。