今天分享一下以前入职现在公司第一次发布项目遇到的一个问题,一个数据库读写分离的坑。
前言
事情是这样的,刚入职的时候接到了这样的一个业务需求:
每个支付通道支付失败的时候都会返回特定的错误码,业务内部需要将通道特定的错误码转义成内部的错误码,这样对外就可以统一返回我们自己的错误码。
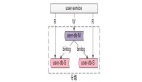
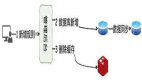
这个需求其实不难,当时设计的系统架构如下:
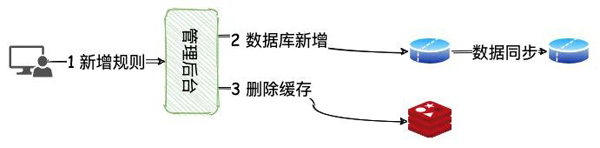
新增规则的流程简单分为三步:
- 业务人员通过管理后台新增映射规则
- 数据库新增、修改这条映射规则
- 删除缓存
这里之所以增加缓存,是因为这个场景每次支付都需要使用,使用缓存可以避免每次都去数据库读取,增加读取速度。
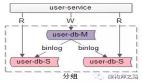
后续支付请求业务流程如下:
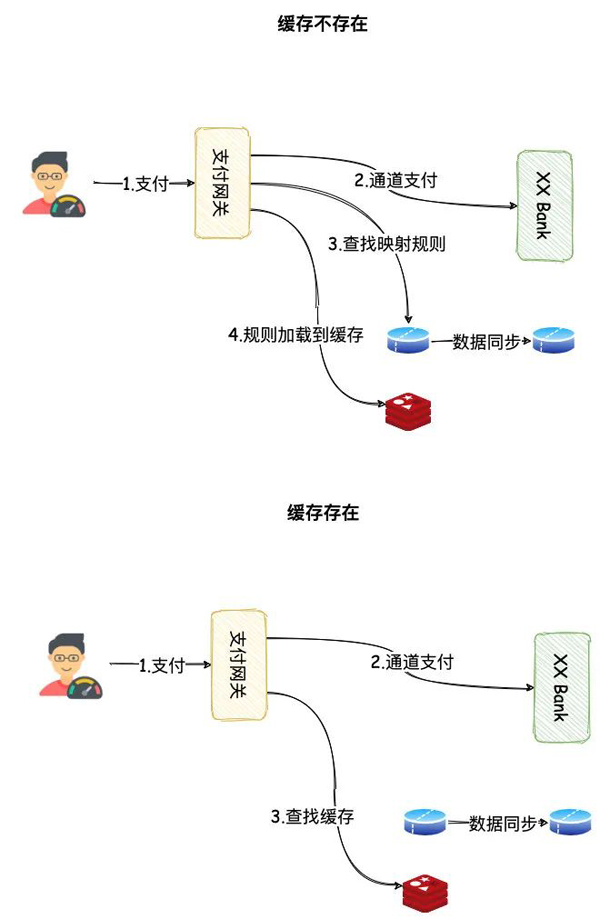
数据库读写分离-用户操作
当缓存内映射规则不存在的时候,将会查询数据库,然后加载到缓存中。如果缓存内映射规则已存在,将会直接使用缓存内映射规则。
这个业务流程其实比较简单,当时在测试环境测试也没问题,后续发布线上环境的却碰到奇怪的问题。
「新增规则之后,一段时间内,映射规则并没有生效。查看日志发现,查询数据库的时候,没有数据。」
这就很奇怪了,日志显示新增是成功,但是查询却没有数据。但是过了一段时间,再次查询却又有了数据。
走查了下代码,发现并没有什么问题,第二天上班的时候请教了一下同事,才知道问题的原因:
原来线上的数据库采用主从架构,数据读写分离,数据查询走的是从库。数据写入都是直接操作主库,后续再同步到从库。
「由于数据库同步存在延时,这就导致数据同步的这段时间,主从数据将会不一致,从库无法查询到最新的数据。」
如果你之前的数据库系统架构是单库或者主备结构,当你第一次转到数据读写分离架构,这个坑大概率也会踩到。
数据库系统架构发展
下面我们首先了解一下数据库系统架构,最后再来看下如何解决主从同步延时的导致数据不一致。
主备架构
业务发展的前期,数据访问量小,这时我们可以直接采用单库的架构。
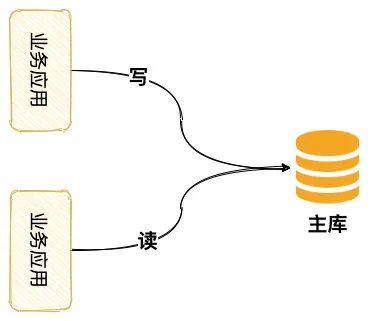
不过我们一般不使用的上面的架构,因为存在单点的问题。若数据库出现故障,这段期间业务将会不可用。我们除了等待重启,其他没什么解决办法。
所以我们会增加一个备库,实时同步主库的数据。
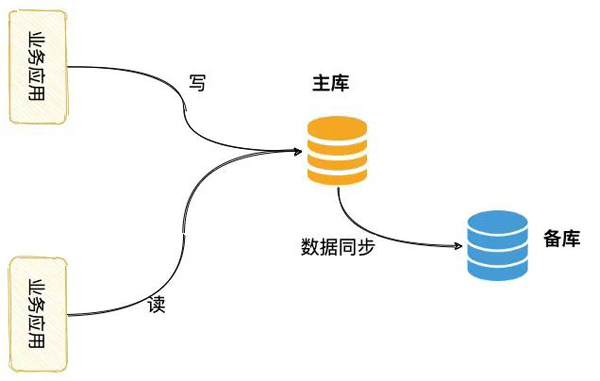
主备架构
一旦「主库」出了故障,通过人工的方式,手动的将「主机」踢下线,将「备机」改为「主机」来继续提供服务。
这种架构,部署维护简单,业务开发也无需任何改造。
不过缺点也很明显,备库只有在主库有问题的时候才会被启用,存在一定的资源浪费的情况。
主从架构
随着业务发展,请求量不断变大,数据量也不断变大,业务变得更加复杂,很快数据将会到达瓶颈。
由于大多数业务都是读多写少,所以数据库读的最容易成为系统瓶颈。
这时候我们可以提高读的性能,这时我们的可以采用的方案,增加从实例,主从同步,数据读写分离。
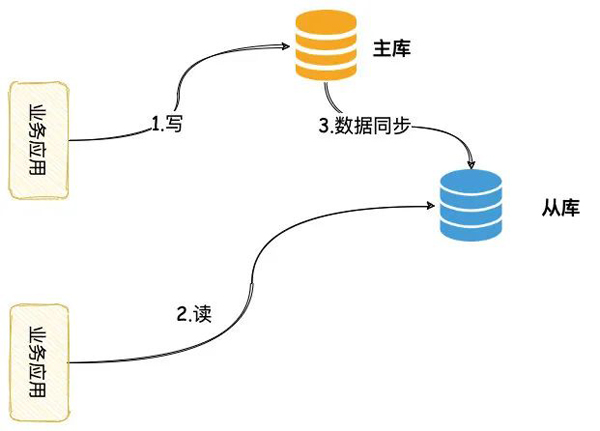
可以看到这个架构与主备没什么区别,主要区别在于主从架构下,从库与主库一样,时刻需要干活,主库提供写服务,从库只提供读服务。
如果后续读的压力还是太大,我们还可以增加从库的数量,水平扩充读的能力。
虽然主从架构帮我们解决读的瓶颈,但是由于主从之间需要数据同步,这天然就存在一定延时。
在这延时窗口期内,从库的读只能读到一个旧数据,这也是上面案例问题的真正的原因。
接下来我们来看下有什么办法可以优化这种情况。
主从延时解决办法
忍受大法
第一种解决办法,很简单,无他,不管他,没有读到也没事。这时业务不需要任何改造,你好,我好,她也好~
如果业务对于数据一致性要求不高,我们就可以采用这种方案。
数据同步写方案
主从数据同步方案,一般都是采用的异步方式同步给备库。
我们可以将其修改为同步方案,主从同步完成,主库上的写才能返回。
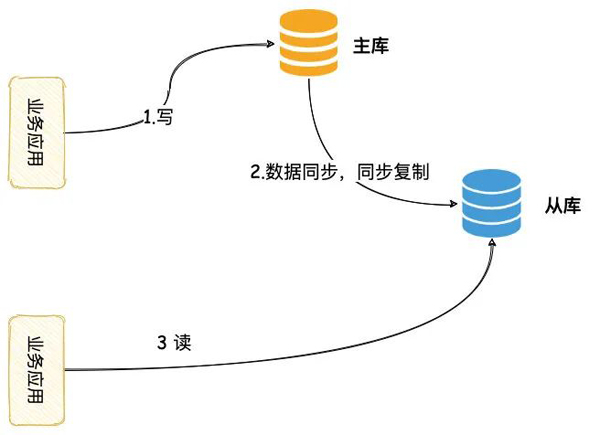
- 业务系统发起写操作,数据写主库
- 写请求需要等待主从同步完成才能返回
- 数据读从库,主从同步完成就能读到最新数据
这种方案,我们只需要修改数据库之间同步配置即可,业务层无需修改,相对简单。
「不过,由于主库写需要等待主从完成,写请求的时延将会增加,吞吐量将会降低。」
这一点对于现在在线业务,可能无法接受。
选择性强制读主
对于需要强一致的场景,我们可以将其的读请求都操作主库,这样「读写都在主库」,就没有不一致的情况。
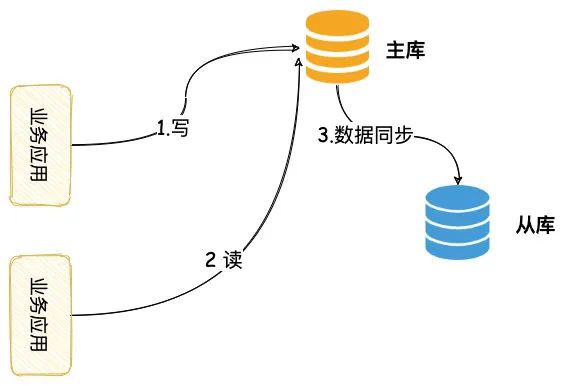
这种方案业务层需要改造一下,将其强制性读主,相对改造难度较低。
不过这种方案相对于浪费了另一个数据库,增加主库的压力。
中间件选择路由法
这种方案需要使用一个中间件,所有数据库操作都先发到中间件,由中间件再分发到相应的数据库。
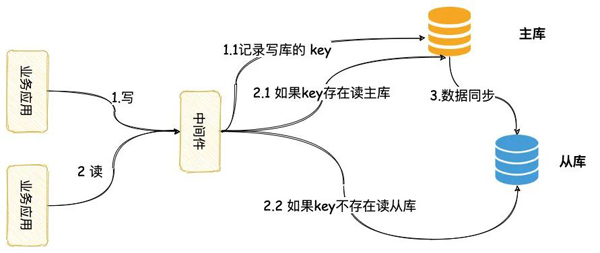
这时流程如下:
- 写请求,中间件将会发到主库,同时记录一下此时写请求的 key(操作表加主键等)
- 读请求,如果此时 key 存在,将会路由到主库
- 一定时间后(经验值),中间件认为主从同步完成,删除这个 key,后续读将会读从库
这种方案,可以保持数据读写的一致。
但是系统架构增加了一个中间件,整体复杂度变高,业务开发也变得复杂,学习成本也比较高。
缓存路由大法
这种方案与中间件的方案流程比较类似,不过改造成本相对较低,不需要增加任何中间件。
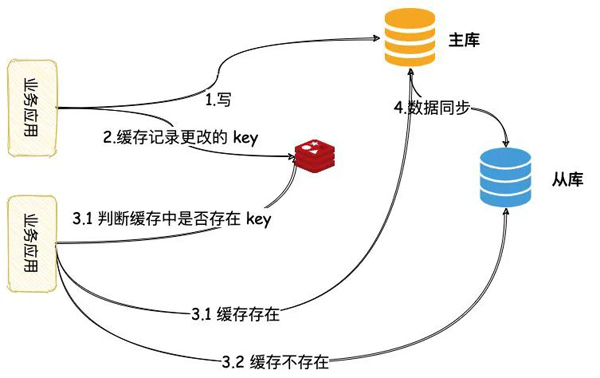
这时流程如下:
- 写请求发往主库,同时缓存记录操作的 key,缓存的失效时间设置为主从的延时
- 读请求首先判断缓存是否存在
- 若存在,代表刚发生过写操作,读请求操作主库
- 若不存在,代表近期没发生写操作,读请求操作从库
这种方案相对中间件的方案成本较低,但是呢我们此时又引入一个缓存组件,所有读写之间就又多了一步缓存操作。
总结
我们引入主从架构,数据读写分离,目的是为了解决业务快速发展,请求量变大,并发量变大,从而引发的数据库的读瓶颈。
不过当引入新一个架构解决问题时,势必会带来另外一个问题,数据库读写分离之后,主从延迟从而导致数据不一致的情况。,
为了解决主从延迟,数据不一致的情况,我们可以采用以下这几种方案:
- 忍受大法
- 数据库同步写方案
- 选择性强制读主
- 中间件选择路由法
- 缓存路由大法
上面的方案都有各自的优点,当然也有相应的缺点,我们需要根据自己的业务情况,选择相应的解决方案。