













在 pandas 中,DataFrame 是我们经常用到的工具。有时候,我们可能会需要对数据按某个字段进行分组,然后每个组取N项。例如:

现在,我想每个职位任取三个用户。
相信有同学会使用 for 循环,依次循环每一行,每个职位选3个,存入一个临时的列表里面。循环完成以后再转成一个新的 DataFrame。但这个方式显然不够智能。
那么,我们有没有什么办法能够不使用循环就做到这一步呢?也许有同学想到了使用 groupby。我们来看看效果。
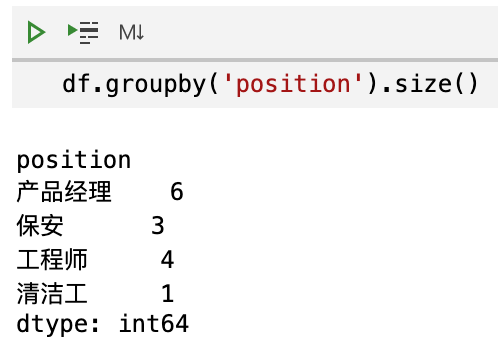
看起来仅仅是统计了每个职位的数量。那么,如何才能保留所有字段呢?
实际上我们可以把.size()改成.head(3):
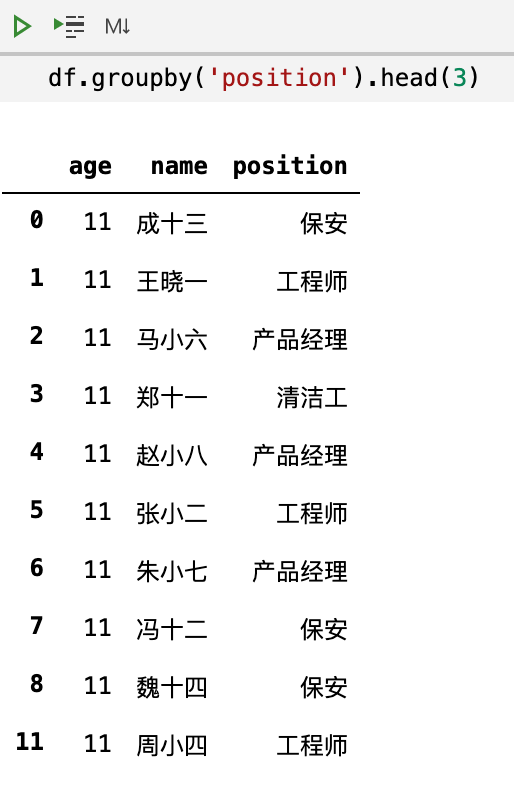
看起来这里的.head(3)似乎没有什么作用。这个时候,我们思考一下 Python 里面,如果要使用itertools.groupby,官方文档里面有这样一段话:
Generally, the iterable needs to already be sorted on the same key function.
如下图所示:

这段话告诉我们,要使用itertools.groupby,我们需要提前对被分组的字段进行排序。
那么,我们试一试在如果提前对 DataFrame 进行排序,然后再 groupby 会怎么样:

成功了。每个职位都取了3个。
可能大家发现最左边的索引是乱序,看起来不好看。那么我们还可以重设一下索引:
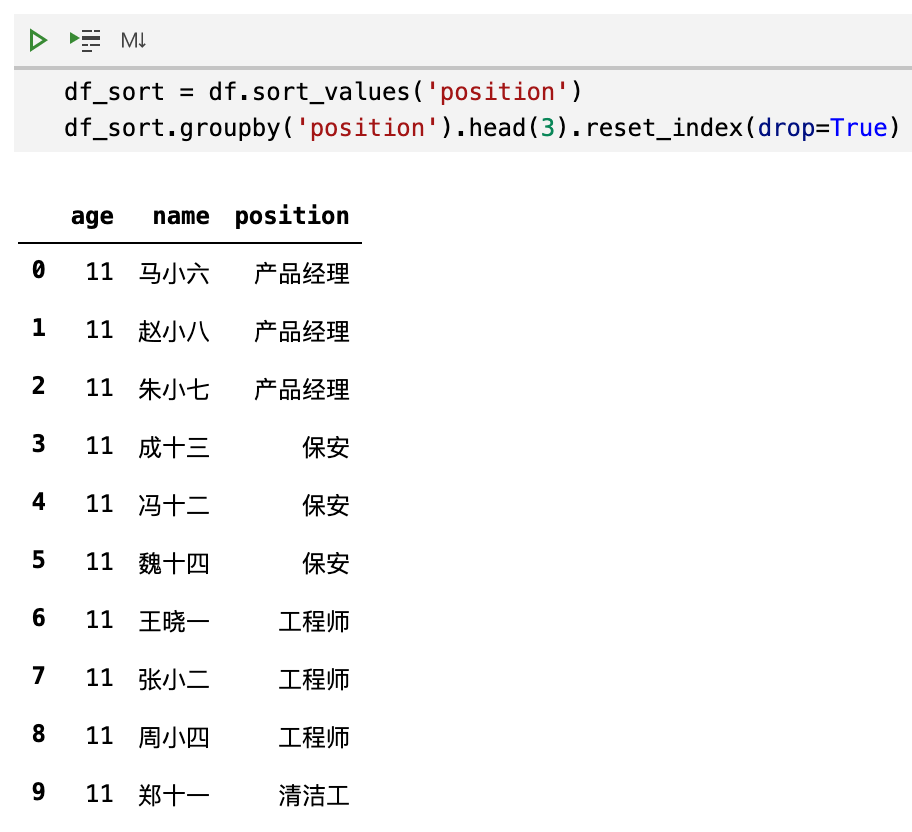
至此,问题完美解决。
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。
























