本文转载自微信公众号「bugstack虫洞栈」,作者小傅哥。转载本文请联系bugstack虫洞栈公众号。
目录
一、前言
二、面试题
三、线程池讲解
- 1. 先看个例子
- 2. 手写一个线程池
- 3. 线程池源码分析
四、总结
一、前言
人看手机,机器学习!
正好是2020年,看到这张图还是蛮有意思的。以前小时候总会看到一些科技电影,讲到机器人会怎样怎样,但没想到人似乎被娱乐化的东西,搞成了低头族、大肚子!
当意识到这一点时,其实非常怀念小时候。放假的早上跑出去,喊上三五个伙伴,要不下河摸摸鱼、弹弹玻璃球、打打pia、跳跳房子!一天下来真的不会感觉累,但现在如果是放假的一天,你的娱乐安排,很多时候会让头很累!
「就像」,你有试过学习一天英语头疼,还是刷一天抖音头疼吗?或者玩一天游戏与打一天球!如果你意识到了,那么争取放下一会手机,适当娱乐,锻炼保持个好身体!
二、面试题
谢飞机,小记!,上次吃亏在线程上,这次可能一次坑掉两次了!
「谢飞机」:你问吧,我准备好了!!!
「面试官」:嗯,线程池状态是如何设计存储的?
「谢飞机」:这!下一个,下一个!
「面试官」:Worker 的实现类,为什么不使用 ReentrantLock 来实现呢,而是自己继承AQS?
「谢飞机」:我...!
「面试官」:那你简述下,execute 的执行过程吧!
「谢飞机」:再见!
三、线程池讲解
1. 先看个例子
- ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(10));
- threadPoolExecutor.execute(() -> {
- System.out.println("Hi 线程池!");
- });
- threadPoolExecutor.shutdown();
- // Executors.newFixedThreadPool(10);
- // Executors.newCachedThreadPool();
- // Executors.newScheduledThreadPool(10);
- // Executors.newSingleThreadExecutor();
这是一段用于创建线程池的例子,相信你已经用了很多次了。
线程池的核心目的就是资源的利用,避免重复创建线程带来的资源消耗。因此引入一个池化技术的思想,避免重复创建、销毁带来的性能开销。
「那么」,接下来我们就通过实践的方式分析下这个池子的构造,看看它是如何处理线程的。
2. 手写一个线程池
2.1 实现流程
为了更好的理解和分析关于线程池的源码,我们先来按照线程池的思想,手写一个非常简单的线程池。
其实很多时候一段功能代码的核心主逻辑可能并没有多复杂,但为了让核心流程顺利运行,就需要额外添加很多分支的辅助流程。就像我常说的,为了保护手才把擦屁屁纸弄那么大!
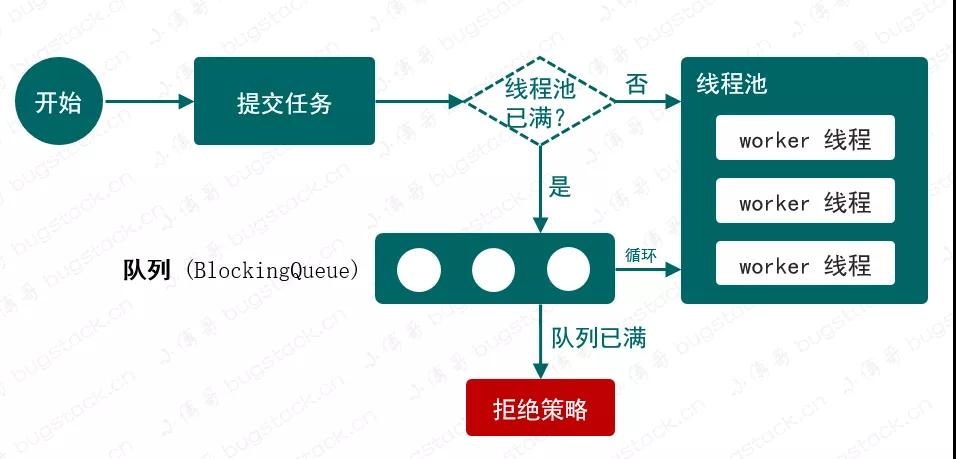
图 21-1 线程池简化流程
关于图 21-1,这个手写线程池的实现也非常简单,只会体现出核心流程,包括:
有n个一直在运行的线程,相当于我们创建线程池时允许的线程池大小。
把线程提交给线程池运行。
如果运行线程池已满,则把线程放入队列中。
最后当有空闲时,则获取队列中线程进行运行。
2.2 实现代码
- public class ThreadPoolTrader implements Executor {
- private final AtomicInteger ctl = new AtomicInteger(0);
- private volatile int corePoolSize;
- private volatile int maximumPoolSize;
- private final BlockingQueue<Runnable> workQueue;
- public ThreadPoolTrader(int corePoolSize, int maximumPoolSize, BlockingQueue<Runnable> workQueue) {
- this.corePoolSize = corePoolSize;
- this.maximumPoolSize = maximumPoolSize;
- this.workQueue = workQueue;
- }
- @Override
- public void execute(Runnable command) {
- int c = ctl.get();
- if (c < corePoolSize) {
- if (!addWorker(command)) {
- reject();
- }
- return;
- }
- if (!workQueue.offer(command)) {
- if (!addWorker(command)) {
- reject();
- }
- }
- }
- private boolean addWorker(Runnable firstTask) {
- if (ctl.get() >= maximumPoolSize) return false;
- Worker worker = new Worker(firstTask);
- worker.thread.start();
- ctl.incrementAndGet();
- return true;
- }
- private final class Worker implements Runnable {
- final Thread thread;
- Runnable firstTask;
- public Worker(Runnable firstTask) {
- this.thread = new Thread(this);
- this.firstTask = firstTask;
- }
- @Override
- public void run() {
- Runnable task = firstTask;
- try {
- while (task != null || (task = getTask()) != null) {
- task.run();
- if (ctl.get() > maximumPoolSize) {
- break;
- }
- task = null;
- }
- } finally {
- ctl.decrementAndGet();
- }
- }
- private Runnable getTask() {
- for (; ; ) {
- try {
- System.out.println("workQueue.size:" + workQueue.size());
- return workQueue.take();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- }
- private void reject() {
- throw new RuntimeException("Error!ctl.count:" + ctl.get() + " workQueue.size:" + workQueue.size());
- }
- public static void main(String[] args) {
- ThreadPoolTrader threadPoolTrader = new ThreadPoolTrader(2, 2, new ArrayBlockingQueue<Runnable>(10));
- for (int i = 0; i < 10; i++) {
- int finalI = i;
- threadPoolTrader.execute(() -> {
- try {
- Thread.sleep(1500);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- System.out.println("任务编号:" + finalI);
- });
- }
- }
- }
- // 测试结果
- 任务编号:1
- 任务编号:0
- workQueue.size:8
- workQueue.size:8
- 任务编号:3
- workQueue.size:6
- 任务编号:2
- workQueue.size:5
- 任务编号:5
- workQueue.size:4
- 任务编号:4
- workQueue.size:3
- 任务编号:7
- workQueue.size:2
- 任务编号:6
- workQueue.size:1
- 任务编号:8
- 任务编号:9
- workQueue.size:0
- workQueue.size:0
「以上」,关于线程池的实现还是非常简单的,从测试结果上已经可以把最核心的池化思想体现出来了。主要功能逻辑包括:
- ctl,用于记录线程池中线程数量。
- corePoolSize、maximumPoolSize,用于限制线程池容量。
- workQueue,线程池队列,也就是那些还不能被及时运行的线程,会被装入到这个队列中。
- execute,用于提交线程,这个是通用的接口方法。在这个方法里主要实现的就是,当前提交的线程是加入到worker、队列还是放弃。
- addWorker,主要是类 Worker 的具体操作,创建并执行线程。这里还包括了 getTask() 方法,也就是从队列中不断的获取未被执行的线程。
「好」,那么以上呢,就是这个简单线程池实现的具体体现。但如果深思熟虑就会发现这里需要很多完善,比如:线程池状态呢,不可能一直奔跑呀!?、线程池的锁呢,不会有并发问题吗?、线程池拒绝后的策略呢?,这些问题都没有在主流程解决,也正因为没有这些流程,所以上面的代码才更容易理解。
接下来,我们就开始分析线程池的源码,与我们实现的简单线程池参考对比,会更加容易理解??!
3. 线程池源码分析
3.1 线程池类关系图

图 21-2 线程池类关系图
以围绕核心类 ThreadPoolExecutor 的实现展开的类之间实现和继承关系,如图 21-2 线程池类关系图。
- 接口 Executor、ExecutorService,定义线程池的基本方法。尤其是 execute(Runnable command) 提交线程池方法。
- 抽象类 AbstractExecutorService,实现了基本通用的接口方法。
- ThreadPoolExecutor,是整个线程池最核心的工具类方法,所有的其他类和接口,为围绕这个类来提供各自的功能。
- Worker,是任务类,也就是最终执行的线程的方法。
- RejectedExecutionHandler,是拒绝策略接口,有四个实现类;AbortPolicy(抛异常方式拒绝)、DiscardPolicy(直接丢弃)、DiscardOldestPolicy(丢弃存活时间最长的任务)、CallerRunsPolicy(谁提交谁执行)。
- Executors,是用于创建我们常用的不同策略的线程池,newFixedThreadPool、newCachedThreadPool、newScheduledThreadPool、newSingleThreadExecutor。
3.2 高3位与低29位

图 22-3 线程状态,高3位与低29位
- private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
- private static final int COUNT_BITS = Integer.SIZE - 3;
- private static final int CAPACITY = (1 << COUNT_BITS) - 1;
- private static final int RUNNING = -1 << COUNT_BITS;
- private static final int SHUTDOWN = 0 << COUNT_BITS;
- private static final int STOP = 1 << COUNT_BITS;
- private static final int TIDYING = 2 << COUNT_BITS;
- private static final int TERMINATED = 3 << COUNT_BITS;
在 ThreadPoolExecutor 线程池实现类中,使用 AtomicInteger 类型的 ctl 记录线程池状态和线程池数量。在一个类型上记录多个值,它采用的分割数据区域,高3位记录状态,低29位存储线程数量,默认 RUNNING 状态,线程数为0个。
3.2 线程池状态
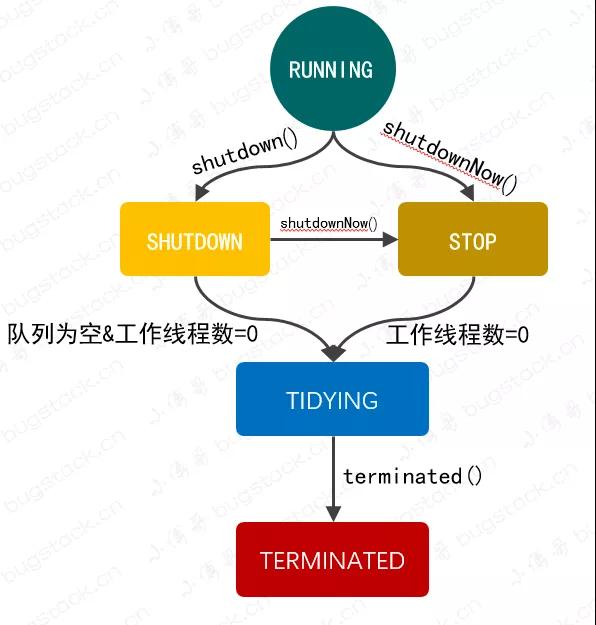
图 22-4 线程池状态流转
图 22-4 是线程池中的状态流转关系,包括如下状态:
- RUNNING:运行状态,接受新的任务并且处理队列中的任务。
- SHUTDOWN:关闭状态(调用了shutdown方法)。不接受新任务,,但是要处理队列中的任务。
- STOP:停止状态(调用了shutdownNow方法)。不接受新任务,也不处理队列中的任务,并且要中断正在处理的任务。
- TIDYING:所有的任务都已终止了,workerCount为0,线程池进入该状态后会调 terminated() 方法进入TERMINATED 状态。
- TERMINATED:终止状态,terminated() 方法调用结束后的状态。
3.3 提交线程(execute)
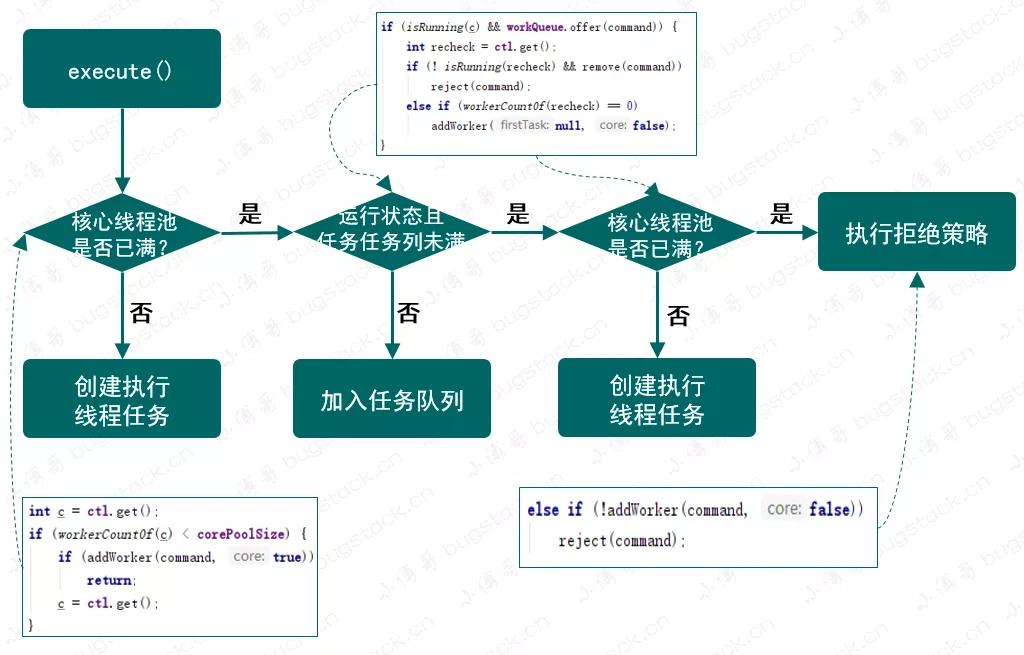
图 22-5 提交线程流程图
- public void execute(Runnable command) {
- if (command == null)
- throw new NullPointerException();
- int c = ctl.get();
- if (workerCountOf(c) < corePoolSize) {
- if (addWorker(command, true))
- return;
- c = ctl.get();
- }
- if (isRunning(c) && workQueue.offer(command)) {
- int recheck = ctl.get();
- if (! isRunning(recheck) && remove(command))
- reject(command);
- else if (workerCountOf(recheck) == 0)
- addWorker(null, false);
- }
- else if (!addWorker(command, false))
- reject(command);
- }
在阅读这部分源码的时候,可以参考我们自己实现的线程池。其实最终的目的都是一样的,就是这段被提交的线程,启动执行、加入队列、决策策略,这三种方式。
- ctl.get(),取的是记录线程状态和线程个数的值,最终需要使用方法 workerCountOf(),来获取当前线程数量。`workerCountOf 执行的是 c & CAPACITY 运算
- 根据当前线程池中线程数量,与核心线程数 corePoolSize 做对比,小于则进行添加线程到任务执行队列。
- 如果说此时线程数已满,那么则需要判断线程池是否为运行状态 isRunning(c)。如果是运行状态则把不能被执行的线程放入线程队列中。
- 放入线程队列以后,还需要重新判断线程是否运行以及移除操作,如果非运行且移除,则进行拒绝策略。否则判断线程数量为0后添加新线程。
- 最后就是再次尝试添加任务执行,此时方法 addWorker 的第二个入参是 false,最终会影响添加执行任务数量判断。如果添加失败则进行拒绝策略。
3.5 添加执行任务(addWorker)
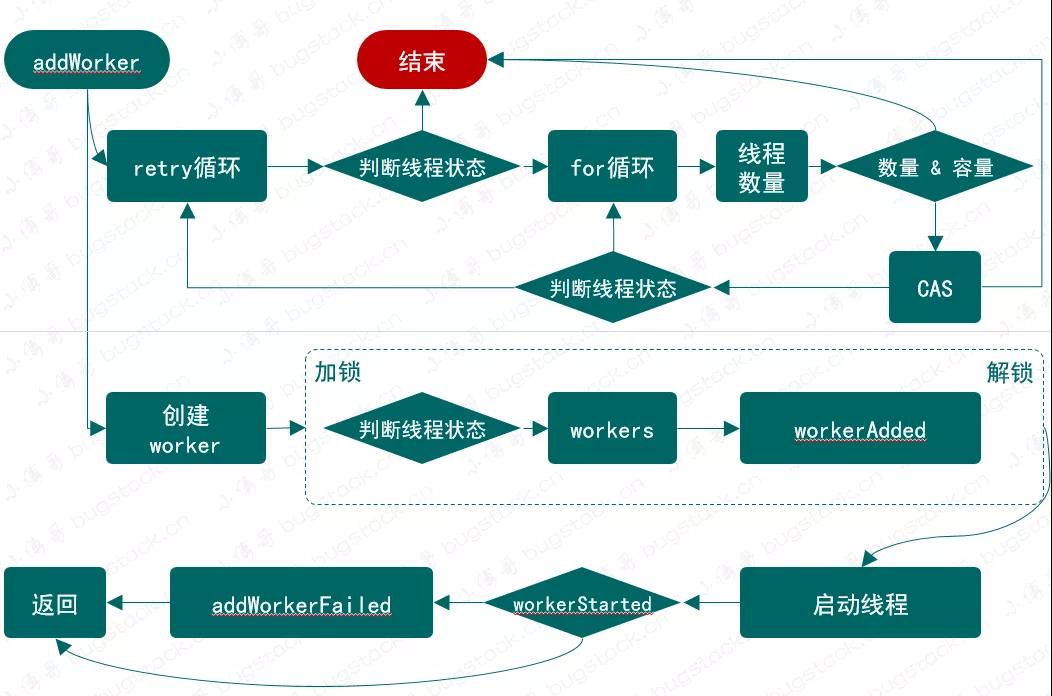
图 22-6 添加执行任务逻辑流程
「private boolean addWorker(Runnable firstTask, boolean core)」
「第一部分、增加线程数量」
- retry:
- for (;;) {
- int c = ctl.get();
- int rs = runStateOf(c);
- // Check if queue empty only if necessary.
- if (rs >= SHUTDOWN &&
- ! (rs == SHUTDOWN &&
- firstTask == null &&
- ! workQueue.isEmpty()))
- return false;
- for (;;) {
- int wc = workerCountOf(c);
- if (wc >= CAPACITY ||
- wc >= (core ? corePoolSize : maximumPoolSize))
- return false;
- if (compareAndIncrementWorkerCount(c))
- break retry;
- c = ctl.get(); // Re-read ctl
- if (runStateOf(c) != rs)
- continue retry;
- // else CAS failed due to workerCount change; retry inner loop
- }
- }
「第一部分、创建启动线程」
- boolean workerStarted = false;
- boolean workerAdded = false;
- Worker w = null;
- try {
- w = new Worker(firstTask);
- final Thread t = w.thread;
- if (t != null) {
- final ReentrantLock mainLock = this.mainLock;
- mainLock.lock();
- try {
- int rs = runStateOf(ctl.get());
- if (rs < SHUTDOWN ||
- (rs == SHUTDOWN && firstTask == null)) {
- if (t.isAlive()) // precheck that t is startable
- throw new IllegalThreadStateException();
- workers.add(w);
- int s = workers.size();
- if (s > largestPoolSize)
- largestPoolSize = s;
- workerAdded = true;
- }
- } finally {
- mainLock.unlock();
- }
- if (workerAdded) {
- t.start();
- workerStarted = true;
- }
- }
- } finally {
- if (! workerStarted)
- addWorkerFailed(w);
- }
- return workerStarted;
添加执行任务的流程可以分为两块看,上面代码部分是用于记录线程数量、下面代码部分是在独占锁里创建执行线程并启动。这部分代码在不看锁、CAS等操作,那么就和我们最开始手写的线程池基本一样了
- if (rs >= SHUTDOWN &&! (rs == SHUTDOWN &&firstTask == null &&! workQueue.isEmpty())),判断当前线程池状态,是否为 SHUTDOWN、STOP、TIDYING、TERMINATED中的一个。并且当前状态为 SHUTDOWN、且传入的任务为 null,同时队列不为空。那么就返回 false。
- compareAndIncrementWorkerCount,CAS 操作,增加线程数量,成功就会跳出标记的循环体。
- runStateOf(c) != rs,最后是线程池状态判断,决定是否循环。
- 在线程池数量记录成功后,则需要进入加锁环节,创建执行线程,并记录状态。在最后如果判断没有启动成功,则需要执行 addWorkerFailed 方法,剔除到线程方法等操作。
3.6 执行线程(runWorker)
- final void runWorker(Worker w) {
- Thread wt = Thread.currentThread();
- Runnable task = w.firstTask;
- w.firstTask = null;
- w.unlock(); // 允许中断
- boolean completedAbruptly = true;
- try {
- while (task != null || (task = getTask()) != null)
- w.lock();
- if ((runStateAtLeast(ctl.get(), STOP) ||
- (Thread.interrupted() &&
- runStateAtLeast(ctl.get(), STOP))) &&
- !wt.isInterrupted())
- wt.interrupt();
- try {
- beforeExecute(wt, task);
- Throwable thrown = null;
- try {
- task.run();
- } finally {
- afterExecute(task, thrown);
- }
- } finally {
- task = null;
- w.completedTasks++;
- w.unlock();
- }
- }
- completedAbruptly = false;
- } finally {
- processWorkerExit(w, completedAbruptly);
- }
- }
「其实」,有了手写线程池的基础,到这也就基本了解了,线程池在干嘛。到这最核心的点就是 task.run() 让线程跑起来。额外再附带一些其他流程如下;
- beforeExecute、afterExecute,线程执行的前后做一些统计信息。
- 另外这里的锁操作是 Worker 继承 AQS 自己实现的不可重入的独占锁。
- processWorkerExit,如果你感兴趣,类似这样的方法也可以深入了解下。在线程退出时候workers做到一些移除处理以及完成任务数等,也非常有意思
3.7 队列获取任务(getTask)
如果你已经开始阅读源码,可以在 runWorker 方法中,看到这样一句循环代码 while (task != null || (task = getTask()) != null)。这与我们手写线程池中操作的方式是一样的,核心目的就是从队列中获取线程方法。
- private Runnable getTask() {
- boolean timedOut = false; // Did the last poll() time out?
- for (;;) {
- int c = ctl.get();
- int rs = runStateOf(c);
- // Check if queue empty only if necessary.
- if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
- decrementWorkerCount();
- return null;
- }
- int wc = workerCountOf(c);
- // Are workers subject to culling?
- boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
- if ((wc > maximumPoolSize || (timed && timedOut))
- && (wc > 1 || workQueue.isEmpty())) {
- if (compareAndDecrementWorkerCount(c))
- return null;
- continue;
- }
- try {
- Runnable r = timed ?
- workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
- workQueue.take();
- if (r != null)
- return r;
- timedOut = true;
- } catch (InterruptedException retry) {
- timedOut = false;
- }
- }
- }
- getTask 方法从阻塞队列中获取等待被执行的任务,也就是一条条往出拿线程方法。
- if (rs >= SHUTDOWN ...,判断线程是否关闭。
- wc = workerCountOf(c),wc > corePoolSize,如果工作线程数超过核心线程数量 corePoolSize 并且 workQueue 不为空,则增加工作线程。但如果超时未获取到线程,则会把大于 corePoolSize 的线程销毁掉。
- timed,是 allowCoreThreadTimeOut 得来的。最终 timed 为 true 时,则通过阻塞队列的poll方法进行超时控制。
- 如果在 keepAliveTime 时间内没有获取到任务,则返回null。如果为false,则阻塞。
四、总结
这一章节并没有完全把线程池的所有知识点都介绍完,否则一篇内容会有些臃肿。在这一章节我们从手写线程池开始,逐步的分析这些代码在Java的线程池中是如何实现的,涉及到的知识点也几乎是我们以前介绍过的内容,包括:队列、CAS、AQS、重入锁、独占锁等内容。所以这些知识也基本是环环相扣的,最好有一些根基否则会有些不好理解。
除了本章介绍的,我们还没有讲到线程的销毁过程、四种线程池方法的选择和使用、以及在CPU密集型任务、IO 密集型任务时该怎么配置。另外在Spring中也有自己实现的线程池方法。这些知识点都非常贴近实际操作。
好了,今天的内容先扯到这,后续的内容陆续完善。如果以上内容有错字、流程缺失、或者不好理解以及描述错误,欢迎留言。互相学习、互相进步。