极限学习机
有人认为,极限学习机是有史以来最聪明的神经网络发明之一,以至于甚至召开了专门讨论ELM神经网络体系结构的会议。ELM的支持者认为,它可以以指数级的更快的训练时间执行标准任务,而很少有训练实例。另一方面,除了它在机器学习社区中并不大的事实之外,它还受到深度学习专家的广泛批评,其中包括Yann LeCun,他们认为它的宣传和信誉远远超出其应有的程度。
通常,人们似乎认为这是一个有趣的概念。
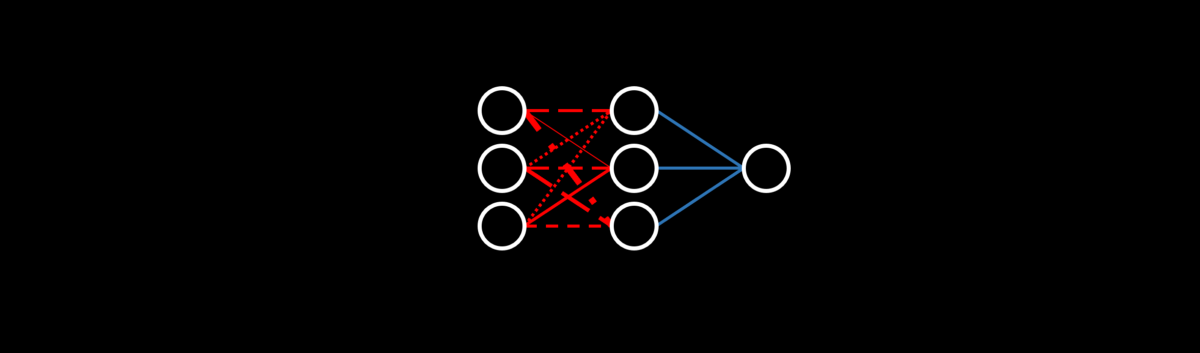
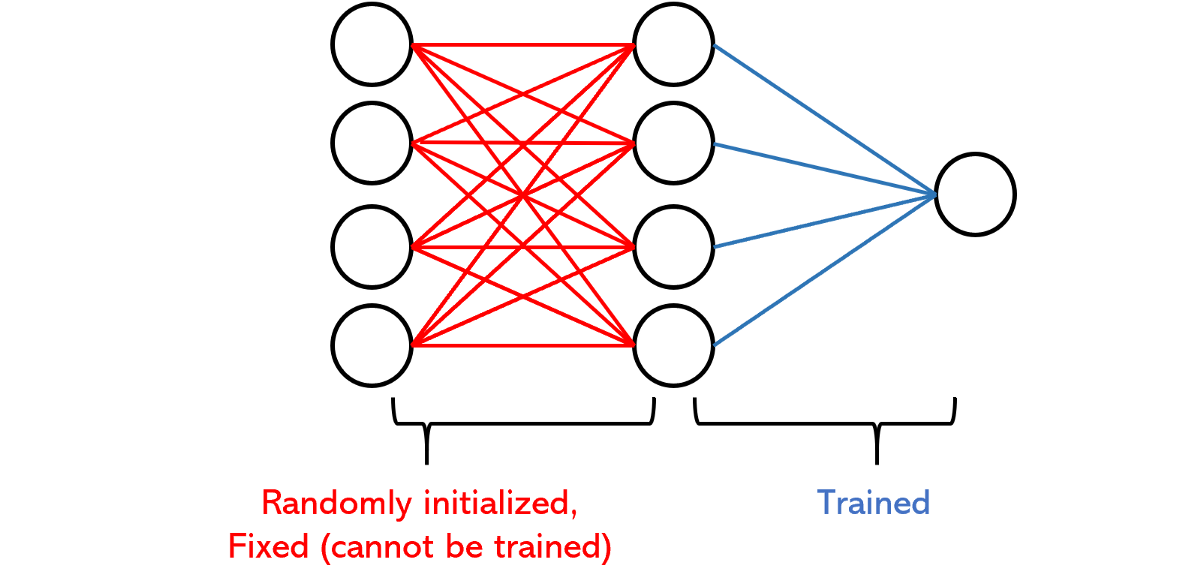
ELM体系结构由两层组成:第一个是随机初始化和固定的,而第二个是可训练的。本质上,网络将数据随机投影到新空间中并执行多元回归(当然,然后将其传递给输出激活函数)。随机投影需要一种降维(或放大)方法,该方法将随机矩阵乘以输入-尽管这个想法听起来很奇怪,但从战略分布中随机抽取实际上可以很好地工作(我们将在以后的直观类比中看到)。它会施加某种随机失真,这种失真会以良好的方式(如果正确完成的话)会产生噪声,并使网络的其余部分能够适应,从而为学习机会打开了新的大门。
实际上,正是由于这种随机性,Extreme Learning Machines才被证明具有隐藏层中具有相对较小节点的通用近似定理幂。
实际上,在1980年代和1990年代,以神经网络发展领域的名字就已经探索了随机投影的想法,这就是对ELM并不是什么新鲜事物的一种批评。只是旧研究以新名称打包。许多其他体系结构(例如回声状态机和液体状态机)也利用随机跳过连接和其他随机性来源。
但是,ELM与其他神经网络架构之间的最大区别可能是它不使用反向传播。取而代之的是,由于网络的可训练部分只是简单的多元回归,因此以大致相同的方式在回归中拟合系数来训练参数。这代表了人们认为神经网络训练方式的根本转变。
自从基本人工神经网络出现以来,几乎所有开发出的神经网络都通过在整个网络中前后反射信息信号,使用迭代更新(或根据需要将其称为"调整")进行了优化。由于这种方法已经存在了很长时间,因此必须假定已经尝试并测试了该方法为最佳方法,但是研究人员承认,标准反向传播存在许多问题,例如训练起来很慢或陷入极小的局部极小值现象。
另一方面,ELM使用数学上涉及更多的公式来设置权重,而无需太深入地研究数学,可以想到使用随机层来补偿更多计算上昂贵的细节,否则它将被替换。从技术上讲,如果有帮助,那么非常成功的Dropout层就是一种随机投影。
因为ELM同时使用随机性和无反向传播算法,所以它们的训练速度比标准神经网络快得多。
另一方面,他们是否表现更好是另一个问题。
有人可能会提出这样一种观点,即ELM比标准神经网络(尽管两者都相距甚远)更能反映人类的学习方式,因为它仅需几个示例就可以非常快速地解决更简单的任务,但是迭代神经网络需要贯穿其中至少,成千上万的样本可以泛化并表现良好。与机器相比,人类可能有其弱点,但是他们在示例学习比率(示例是他们所接受的培训示例的数量)方面的巨大优势才使我们真正变得聪明。
极限学习机的概念非常简单-如此简单,以至于有人会称其为愚蠢的。伟大的计算机科学家和深度学习先驱Yann LeCun宣称,"随机连接第一层几乎是您可以做的最愚蠢的事情",在此论点之后,他列举了更多的开发方法来非线性地变换向量的维数,例如作为SVM中使用的内核方法,通过使用反向传播进行定位进一步得到了加强。
LeCun说,从本质上讲,ELM本质上是一个SVM,具有更差的转换内核。使用SVM可以更好地建模ELM能够解决的有限范围的问题。唯一的反驳是使用"随机内核"而不是专用内核的计算效率,因为SVM是众所周知的高功率模型。ELM可能带来的性能降低是否值得,这是另一个讨论。
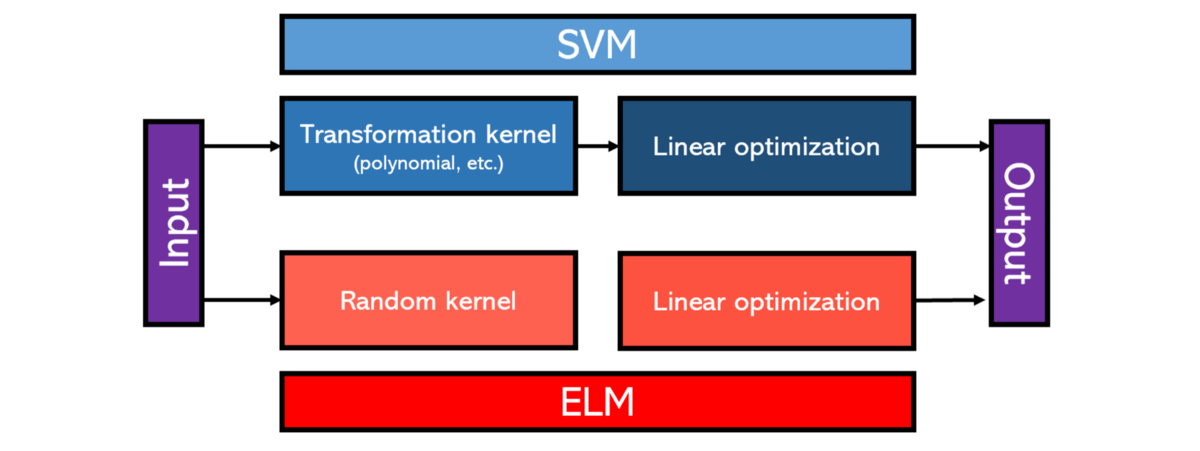
> One way to compare ELMs and SVMs.
然而,无论是否像ELM一样,根据经验,在简单的神经网络中使用随机投影或过滤器以及其他模型都已证明在MNIST等各种(现在被认为是"简单")标准训练任务中表现出色。尽管这些性能不是一流的,但经过如此严格审查并且其概念几乎被认为是荒唐可笑的体系结构,可以通过最新的神经网络在排行榜上独占edge头–此外,它具有更轻量级的体系结构和较小的计算量–至少是令人感兴趣的。
为什么使用固定的随机连接有效?
这是一百万美元的问题:很明显,如果ELM的性能与普通的反向传播神经网络一样好(甚至更好),那么ELM中具有随机连接的某些功能就可以正常工作。虽然它的数学是不直观的,但原始的《极限学习机器》论文的作者光斌煌,举例说明了这个概念(针对语言,简洁性和深度学习的相似性进行了编辑):
您要用石头填满一个湖,直到用石头而不是水填满一个水平表面,然后您才能看到空湖的底部,这是一条曲线(代表数据的函数)。工程师仔细计算了湖泊的大小,填满湖泊的石头的大小,以及在优化任务中起作用的众多其他小因素。(优化适合该功能的许多参数。)
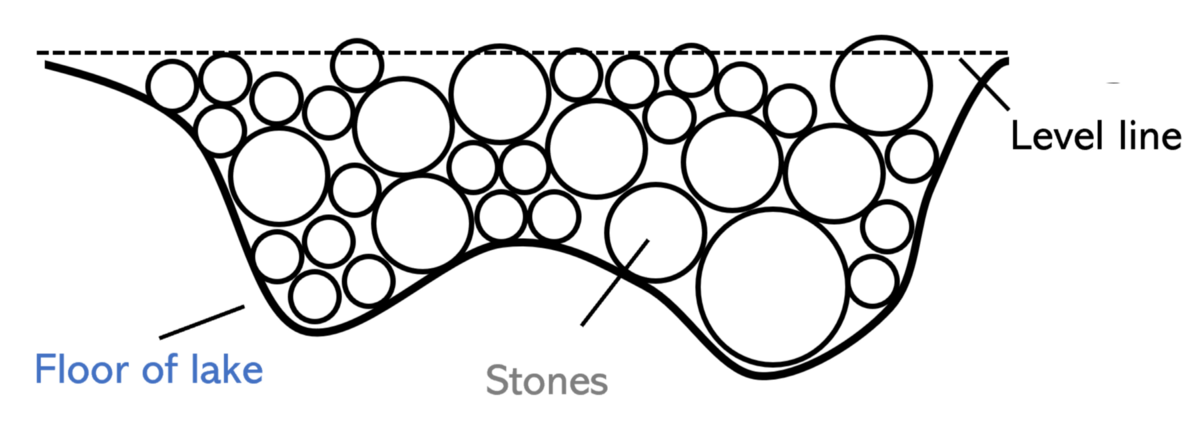
> A bad but acceptable job of filling stones into the lake.
另一方面,农村农民炸毁附近的山,开始扔掉或推下掉进湖里的岩石。当农村农民捡起一块石头(隐藏层节点)时,他不需要知道湖的大小或石头的大小,他只是随意地扔石头并将石头散布开来。如果某个区域的岩石开始堆积在地表上方,则农夫会用锤子将其砸碎(β参数-各种规则化处理),以平整地表。
尽管工程师仍在计算岩石的高度和体积以及湖泊的形状,但农夫已经填满了湖泊。对于农夫来说,扔多少块石头都没关系:他可以更快地完成工作。
尽管这种类比在不同场景的直接应用中存在一些问题,但这是对ELM的本质以及随机性在模型中扮演的角色的直观解释。ELM的本质在于,天真并不总是一件坏事:简单的解决方案可能能够更好地解决不太复杂的问题。
关键点
- 极限学习机使用固定的随机第一层和可训练的第二层。这本质上是随机投影,然后是多元回归。
- ·支持者说,ELM能够在简单的场景(如MNIST)中以非常少的示例很快地学习,其优点是易于编程,并且无需选择诸如体系结构,优化器和损耗之类的参数。另一方面,反对者认为,SVM在这些情况下会更好,ELM不适合解决更复杂的问题,并且它只是对一个非常古老的想法进行了重新命名。
- ELM通常在复杂任务上表现不佳,但事实证明它可以在较简单的任务上表现良好,这是探索更多轻量级体系结构,非反向传播模型拟合和随机投影世界的一个很好的理由。至少,极限学习机(或您想在其下打上这个名字的任何名称)是每个深度学习爱好者都应该知道的有趣的想法。
您对ELM有何看法?