20年弹指一挥间。技术在飞速的发展,从最初接触ixp1200 的耳目一新,到如今DPDK, smart NIC的 如火如荼。我也已经从昔日的青葱少年,变成了两鬓微霜的打工人。午夜梦回, 在感慨人生有如逆旅之余,心中也有很多想法不吐不快。
前传
2000年是网络处理器的黄金时代,Intel在那个时候也有一个Network Processor产品,名为IXP1200,主要是通过可编程的专用引擎来加速网络报文处理。IXP1200/2400/2800本身带有N个微引擎,可供编程。但是编程的难度很大,尤其是在高并发的情况下并不容易调试。
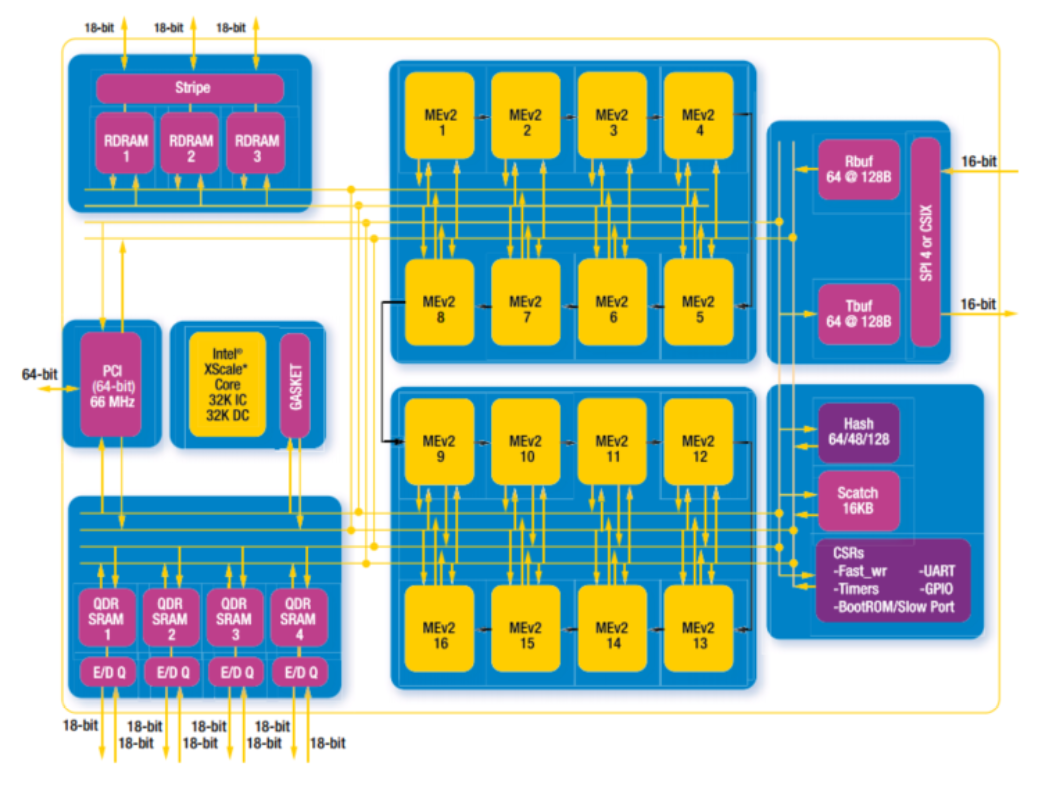
我们来看看IXP1200 和2800的架构图:
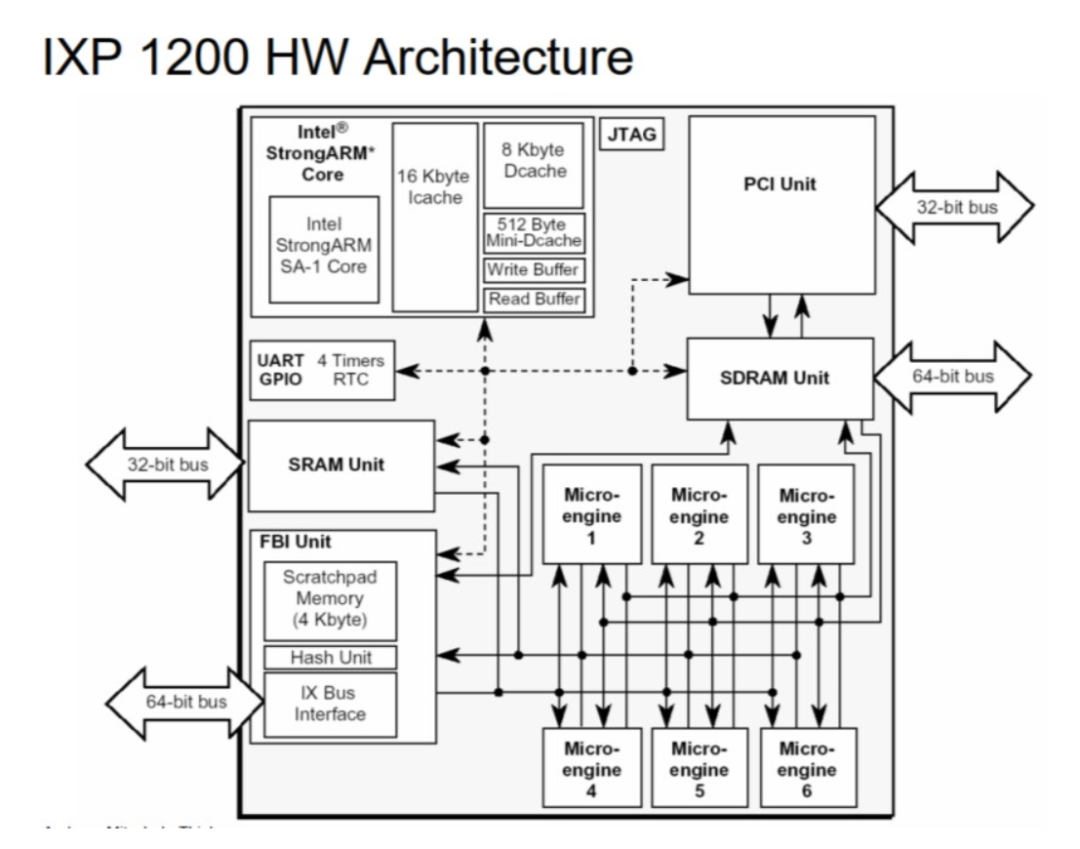
IXP 1200 是初代试水产品, 只有6个微引擎。其整体频率也较低,约为233Mhz,所以只支持千兆网络线速。
IXP 2800 就进化到了16个微引擎. 微引擎频率提高到1.2Ghz. 可以支持万兆网络线速。同时支持各类加密算法加速引擎。
这个产品线于2007年被出售给了Netronome公司,现在依然存在,而且已经扩充至60个甚至更多的微引擎。
https://www.netronome.com/products/agilio-fx/
每个微引擎又内置了4-8个硬件线程,每个线程可以发起收包操作然后进入等待模式调度器调度其它硬件线程运行,直到I/O 操作完成 对应的signal重新设置为可以调度(注意这一切都是硬件逻辑)下面是微引擎的内部架构
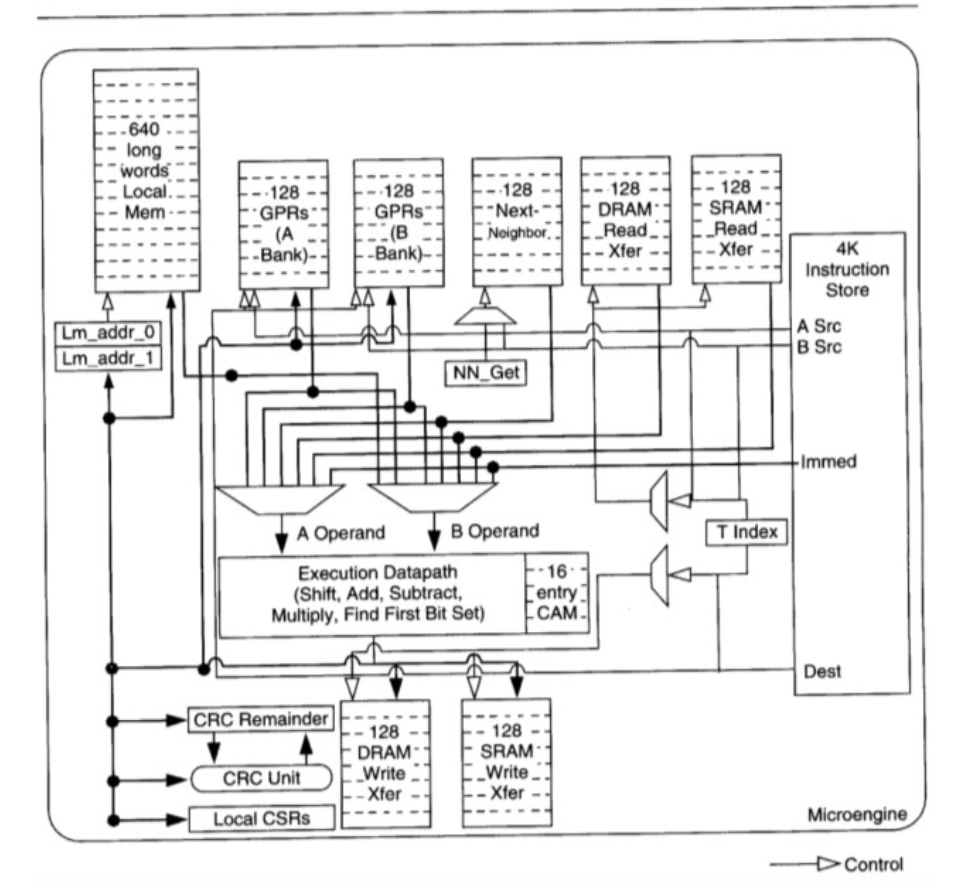
大家可以看到这个微引擎麻雀虽小五脏俱全,甚至带有CAM (Content-addressable memory) 。
寄存器分为几类:计算用的 通用GPR 以及IO用的xfer寄存器。有4k的空间存放代码。有一定大小的本地缓存Local Mem。也有类似于中断但又不完全一样的signal机制。在这个螺蛳壳里也可以写出很多非常精巧的代码,包括复杂的有限状态机。下面是一段代码示例。

估计大多数人都不太能看明白这段代码。这其实就是微引擎编程的一个瓶颈-可读性差与学习曲线陡峭。微引擎中的资源(各类寄存器,signal) 都是非常有限的,基本上都需要进行手动的优化,开发人员编码时如履薄冰。寄存器耗尽是我那时的噩梦。绞尽脑汁也要腾挪出一些资源。学习的曲线之高直接导致的就是开发生态非常之小。同时开发工具,调试工具都必须是专有的。直接导致开发效率不高。这些其实也是专用的ASIC和网络处理器普遍存在的问题。
挑战到来
X86 CPU 在控制面处于统治地位,数据面则长期受制于FSB,PCI/PCIE 带宽限制。2010年以后,随着新一代X86 CPU性能的不断增强(FSB被替代,DMI带宽不断增大)以及PCIE 2.0 推出。那么人们不禁要问。使用X86是否有可能达万兆线速处理?这在当时是一个巨大的疑问。普遍认为是很难做到的。
首先来看看FSB的移除
FSB 全称是 Front-side bus。如下图所示, 主要是负责连接CPU 与北桥内存控制器的总线技术。
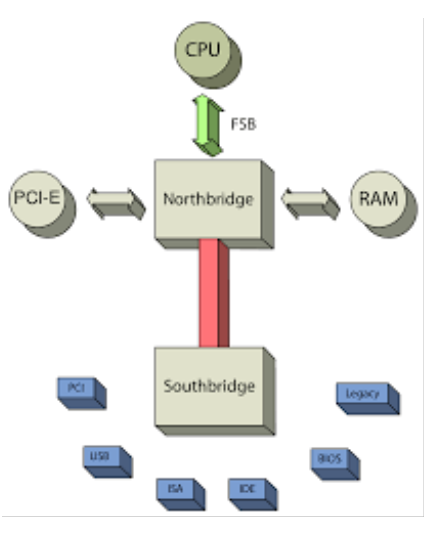
FSB 横亘在北桥(一般是内存控制器Hub)与CPU之间。FSB不但掌管了对内存的访问同时也是PCIE通信的必经之路。性能不具备水平扩展性。作为控制平面是没问题的。但是如果作为数据平面 就成了首要瓶颈。
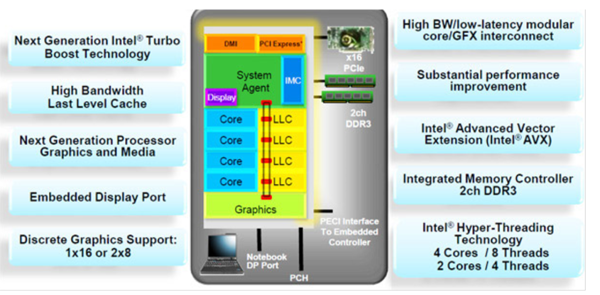
再来看看之后的Sandy bridge 微架构的样子。FSB被移除, 内存控制器直接整合到CPU之中, PCIE也升级到了2.0(这就意味着每个lane的带宽升级到了 4Gbps)
揭开大幕
使用X86作为数据平面方案有很多福利:
- X86 芯片通常有18个月换代的,可以使得性能搭车18个月就获得更新。一个最好的例子就是aes-ni,每一代aes-ni指令性能都有所增强。同理适用于sse/avx/avx2/avx512。(aes-ni 属于X86的aes加密算法指令扩展)
- 虚拟化技术也是可以毫无障碍的搭顺风车来利用,从而节省单独研发的费用问题。
- 同时因为是X86,整个技术生态是完备的。开发环境/调试环境都无需再使用专有的。大大增强了普适性同时也大大提高了效率以及升级换代的时间。例如 可以使用最先进最好的编译器技术。C语言的普及程度也是非常之高,学习曲线平缓。
随着Sandy bridge 这代的X86 处理器发布, 之前的各种技术瓶颈貌似都有了松动的迹象。Venky Venkatesan(已故的DPDK之父) 脑海中的新一代的技术方案也逐渐成型。在经过一段内部的酝酿之后,2010-2012年 Intel完成架构分析与设计。2013 年dpdk社区正式上线,从而在业内成为了一个现象级的产品。
那么我们可以复盘一下 当时 Venky 先生所面临的挑战(X86 万兆线速)
- 万兆线速基本上约等于15 MPPS(也就是1500万个报文每秒)。那么CPU大约有67.2 ns的预算来转发一个报文
- Sandybridge 主频达到2.2Ghz是毫无困难的。困难应该主要还是来自IO。FSB这个瓶颈已经被替代。PCIE2.0 已经开始支持。2M/1G的巨页也开始支持!
- 但是如果回头看软件, 问题就很多了。如果通过传统的内核协议栈, 这一目标完全是无法实现的。当然内核协议栈的设计哲学也并非是单纯为了性能。通用性也是其重要考量。但是在这个特定的场景下就成为了最后一个瓶颈。
应对挑战
DPDK是一个典型的由量变到质变的设计过程。它本质上是众多优化方法的集合。单一的优化方法,其实以前也已经存在。比如 by pass kernel 的 net map。但是单一的优化方法都不足以把性能提升到一个质变的程度。DPDK则是集所有可以使用到的优化方法之大成,把X86处理器的网络处理能力推上了一个新的境界。
我们可以列出DPDK的优化方法有(包含但不限于):
- By pass 内核协议栈。通过uio/vfio将网络设备暴露给用户层, 抛开通用的内核路径, 一身轻。(uio/vfio 是Linux内核支持用户层驱动的编程框架)
- 使用巨页从而大大降低TLB miss带来的性能损失。细节请参考(https://lwn.net/Articles/374424/)
- 广泛的应用批处理从而摊薄单个报文的开销 (例如 使用simd优化网卡驱动). 批处理的优化思想在DPDK之中是一个极其常见的范式。
- 放弃中断模式而转而直接使用轮询模式。这个对于降低时延非常重要。因为在PCIE总线上,中断也是一个TLP报文过多的中断也会影响真正数据的时延(尤其是小包),中断处理导致的上下文切换也会引起系统抖动。但是轮询非常考验内存控制器和PCIE Root Complex的鲁棒性。鲁棒性差的平台容易出问题。
- 魔改DDIO,网卡直接DMA数据到LLC(Last-Level Cache)中. DDIO对于小包的性能非常重要. 这个在今天依然是xeon的独有功能(新一代的CLX协议中实现了DDIO的超集),细节请参考“Linux阅码场”公众号前期文章《Linux 系统性能评测基准系统配置及其原理》。
- 对齐对齐再对齐。预取预取再预取。极度重视cache的优化。对齐主要是针对CacheLine 长度以及 PCIE的DMA地址。预取Prefetch 则较为难以把握精确的时间点, 需要反复的实验找到最佳位置。细节请参考Intel 软件优化手册(https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-optimization-reference-manual.html)
- 隔离Core 不让Core参与操作系统的调度。减少抖动。禁止进程切换,尽量减少系统调用,这些都会引起严重的抖动。细节请参考之前的公号文章(https://mp.weixin.qq.com/s/nkiE4CEo_zSN35I_qITAvQ)
- 针对X86微架构。无所不用其极地进行优化。例如 write forwarding. 细节请参考Intel 软件优化手册
- 广泛使用二阶递进的分区设计模式。尽量避免核间通信(例如mem pool/local pool etc) 细节请参考DPDK 官方文档
- 广泛使用无锁队列以及相关精巧的数据结构设计。例如著名的rte_ring。细节请参考DPDK 官方文档
经过这样层层递进联合的优化, DPDK终于站上了性能的巅峰。
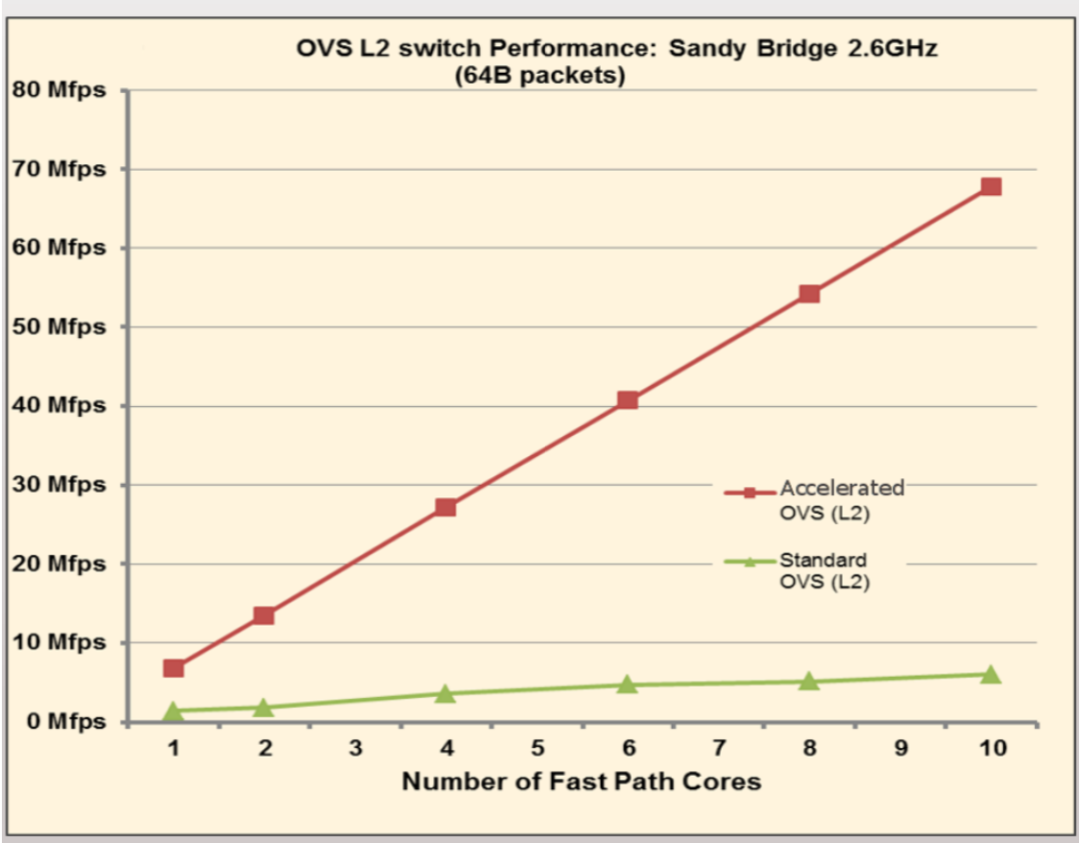
但是故事并没有结束。X86有一个比较突出的问题,就是关于价格。那么每一个X86 Xeon核心的价格并不便宜。所以当一些业务流程逐渐沉淀下来比较固化以后,又可以重新的转化为ASIC来处理。这样就催生了各类的Smart NIC,绕了个圈又回到了IXP 。只是如今微引擎(或者类似的可编程组件)都集成进了网卡。这些恰恰印证了技术的发展是一个螺旋上升的过程,永远是围绕着性能/价格进行动态平衡调整。
DPDK与内核的关系
这个话题通常是一个DPDK广泛被误解的地方。我觉得既有竞争关系,但是又有非常密切的合作关系。
首先我们来谈竞争。DPDK和Linux 内核进行竞争的仅仅是Linux内核协议栈中关于包转发处理的一小部分。那么这一部分由于Linux内核协议栈性能常年非常的低下。当然,这也是Linux 内核的一些设计哲学导致的.其实并不算是设计失误而是追求的目标不同。那么这一部分确实是存在竞争关系,但是值得一提的是 DPDK同时也催生了Linux 内核中的新的包处理框架XDP 以及AF_XDP这些新兴的技术。也算是既竞争又促进。关于某些内核协议栈maintainer一些过于戏剧化的行为,窃以为看看就好, 毕竟想想DPDK的编码风格,开发管理流程, 大多还是跟随内核社区。
那么合作的这一部分呢?其实就非常之多了。
首先DPDK所用到的所有基础架构:
- UIO/VFIO/IOMMU这些框架无一不是由内核来提供的。
- Hugepage 以及Systemmap 地址查找都是依赖内核
- 所有的sysfs,不用说都要依赖。
- 电源管理的框架完全根植于cpufreq/idle 这两个内核的子系统
- 每次新一代的处理器的支持
- 周边的生态linker loader debuger compiler perf etc
- 虚拟化的支持也要依赖kvm/qemu
- 你可以想到的更多。
展望未来
在通信技术高速发展的今天,DPDK 面临很多新的挑战:
- 使用如此高配得core来polling,浮点单元、极致的乱序引擎没有充分发挥效用,同时价格上还是不便宜的,那么在性价比上就会面临DPU的挑战。最终应该是多种方案并存的状态。
- 100%的cpu占用使得真正的cpu使用比例很难被监测到,同时能耗也是一个问题,当然这个方面已经有很多改进的方案在社区进行讨论。
- 扩展生态,开源的鲁棒性高的协议栈仍然是稀缺的
- 同样是生态问题,与控制平面的接口如何优化也是一大方向。
- 在Cloud Native 的大趋势下, 如何进化、适应。
这些问题都有待通过整个DPDK社区的继续努力来解决。
参考
https://www.dpdk.org/wp-content/uploads/sites/35/2014/09/DPDK-SFSummit2014-HighPerformanceNetworkingLeveragingCommunity.pdf
http://dpdk.org
https://www.intel.com/content/www/us/en/io/data-direct-i-o-technology-brief.html
https://software.intel.com/content/www/us/en/develop/download/intel-64-and-ia-32-architectures-optimization-reference-manual.html
https://lwn.net/Articles/374424/
作者简介
作者Liam,海外老码农,对应用密码学、CPU微架构、高速网络通信等领域都有所涉猎。
本文转载自微信公众号「Linux阅码场」,可以通过以下二维码关注。转载本文请联系Linux阅码场公众号。