













这个世界是纷繁复杂的,同时又是符合一些简单规律的。朱子有句名言:千头万绪,终归一理。意思是无论多么混乱的东西,都始终是由一个简单的道理支配着的。举例来说,在古老的《易经》里便定义了阴阳两个符号,并赋予了它们丰富而且深刻的内涵。在《易经》的系辞传中,有一句著名的话:易有太极,是生两仪。对这句话,有不同的理解。“天地起源说”是其中一种。根据这种理解,宇宙最初是混沌的一体,后来清者为天,浊者为地,这个形成天地的过程可以被简称为“二仪攸分”。
我不敢说这句话对描述天地形成有几分准确,但凭着多年来对软件的研究,我认为它对软件世界是很适用的。最早的软件就是一长串卡片,连在一起,卡片上的指令住在一个空间里,是平等的,没有特权差异,没有空间划分。随着计算机的发展,计算机系统里的角色开始细分,每个角色的特征和位置逐渐固定。于是有了中央化的内存和处理器,以及外部的输入输出设备。
中央的处理器和内存速度很快,外部的输入输出设备速度很慢。让中央处理器直接与外设对话太影响效率了。于是便有了中断的概念,中央处理器需要什么,下命令给外设,外设做好了,通过中断通知中央处理器:“报告老大,您吩咐的任务完成了。”外部设备不止一个,中断也有很多种,为了更好的处理中断,便有了专门用于处理中断的“控制程序”,这便是操作系统的前身。中断处理程序的逻辑很敏感,如果出故障就会导致整个系统无法工作。既然它如此重要,那么就应该“优待”它,让它享有特权,给它专门的“住所”,加强其住所的防卫,防止有人擅自闯入。于是便有了专门给中断处理程序住的空间,也就是所谓的内核空间。有了高特权的内核空间后,也就有了低特权的用户空间。于是本来混沌一体不分特权的软件世界便分成两个部分了。
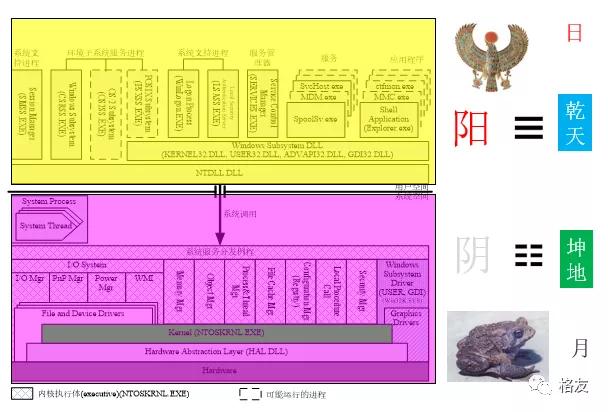
在软件世界的两个空间中,“用户空间是可见的,很多程序在上面生生不息,属阳。内核空间不可见,但是承载着上面的应用,为应用提供服务,厚德载物,本身不发光,但是却能反射应用的光辉,像月亮,属阴。”(选自《软件调试》卷2)今天,软件世界的这种基本格局已经非常固定,无论是Windows,还是Linux都是如此。用户空间和内核空间的关系与现实世界中公民与政府的公司非常类似。当公民需要政府服务时要到政府的窗口去办理,软件世界中的对应机制便叫“系统调用”,意思是要调用系统的服务。
[前半部分为科普,后半部分换挡,前方高寒,非geek止步]
受两大空间划分的影响,当我们调试软件时,一般也分为调试用户空间代码的应用程序调试,和调试内核空间代码的内核调试。相应的,调试器也可以分为应用程序调试器和内核调试器。
容易理解,当我们使用应用程序调试器调试应用程序时,是无法调试内核代码的。反过来则未必。
或者说,使用内核调试器能调试用户空间的代码吗?
理论上是可以的,因为内核空间的特权高,既然已经能访问和控制内核空间,那么理论也就能访问和控制受内核管理的用户空间。
理论上可以,实践中可以么?答案是未必,要看调试器的能力,也要看调试者的技术水平。
举例来说,使用WinDBG来调试Windows内核时,也可以在用户空间设置断点,断点命中后,可以读写变量,或者单步跟踪。
不过,虽然WinDBG有这个能力,实际能做把WinDBG使用到这个程度的人其实并不多。在这方面,WinDBG还有一个非常牛的能力,那就是跨越阴阳二界地显示系统调用的完整过程,比如:
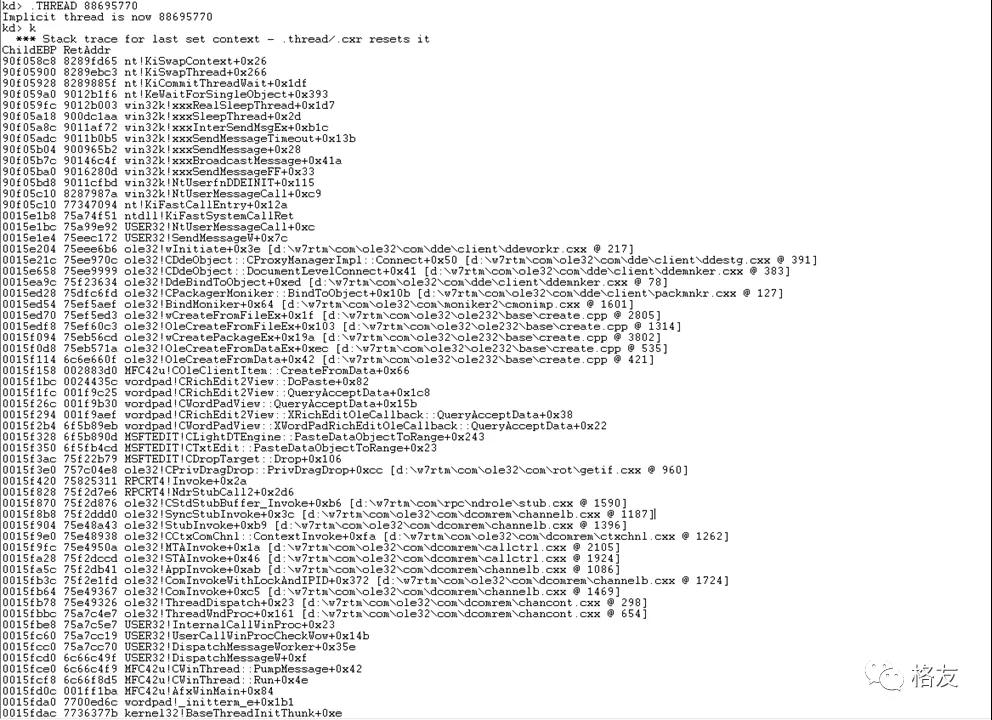
在上面这幅完美的栈回溯中,下面部分是CPU在用户空间的执行经过,从线程的起点开始,到AfxWinMain,经过消息循环,然后是OLE的处理文件拖拽逻辑,收到一个文件后,自己不认识,通过古老的DDE机制广播消息寻求帮助,用于广播消息的SendMessageW函数发起系统调用,进入内核空间,内核空间中的Win32K模块处理这个服务请求,执行广播消息的任务,把消息发个一个个顶层窗口,遇到一个“收到消息不回的坏蛋”,卡在那里了。
我第一次看到这样的完美栈回溯时,我深深被微软调试工具的技术水平所打动。
为什么呢?因为要跨越两个空间显示这个栈回溯有很多困难。第一个困难是每个普通线程都至少有两个栈,用户空间一个,内核空间一个,因此,要显示上面这样的完美栈回溯,必须要回溯两个栈,因为起点在内核空间,因此,内核空间的栈比较好找。但用户空间的栈位置就不那么好找。
第二个困难是今天的主流操作系统都是多任务的,有很多个用户空间,要显示上面的完美栈回溯,必须要找到正确的用户空间,并且找到这个空间中的模块列表,加载用户空间的模块。
自从开始开发NDB调试器,我就想让它也具有“产生完美栈回溯”的能力。为了实现这个愿望,我花很多时间思考,加上很多时间写代码,当然还花了很多时间来调试代码,让它如预期的工作。
长话短说,解决第一个困难花了至少三十个小时的时间。最终的成功方案是要经历这几个步骤。先通过内核空间的栈回溯,找到CPU做系统调用时,飞到内核空间的起点,在x64下,它是使用汇编编写的entry_SYSCALL_64。在内核源码的syscall_init中,也可以看到这个证据。
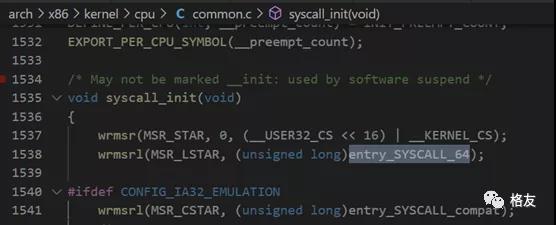
entry_SYSCALL_64的源代码位于:F:\bench\linux-5.0.7\arch\x86\entry\entry_64.S在这个非常值得细读的汇编源文件中,有一段很长的注释,这段注释帮了我大忙。
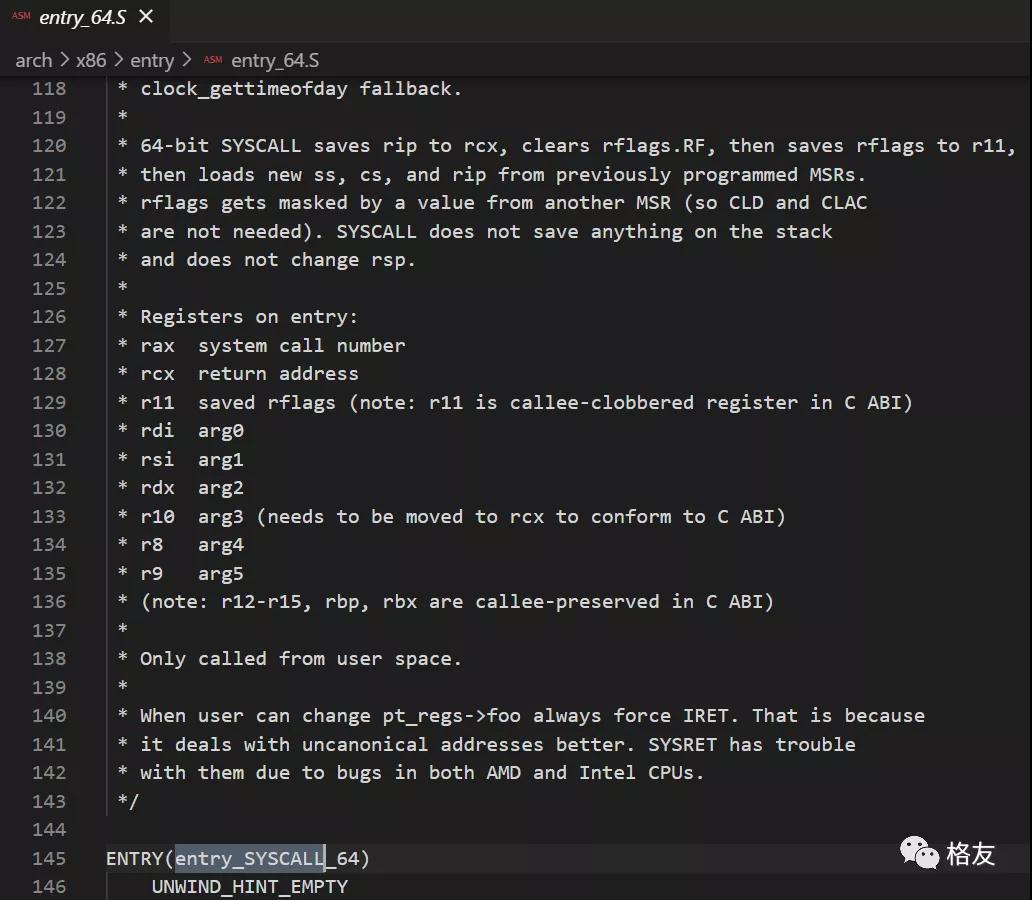
更重要的是,在这个汇编函数中,它保存了一个所谓的硬件帧,通过不断压栈,在栈上形成形成了一个pt_regs结构体。
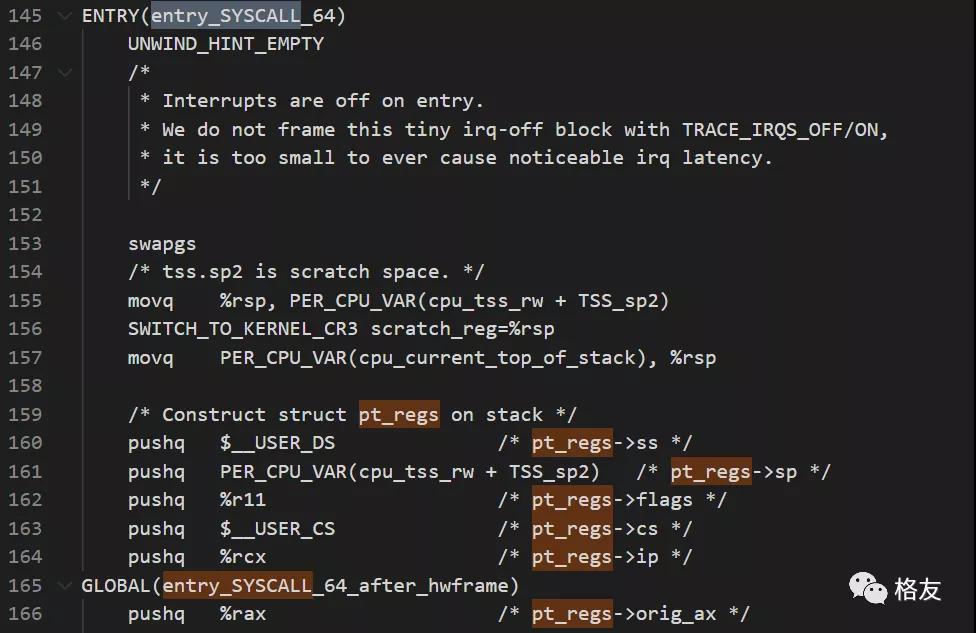
这个pt_regs结构体里面包含了关键的寄存器信息,特别是我需要的用户空间栈指针rsp。
类比一下,这个结构体相当于Windows下的陷阱帧(KTRAP_FRAME),这又应了朱子的话:千头万绪,终归一理。
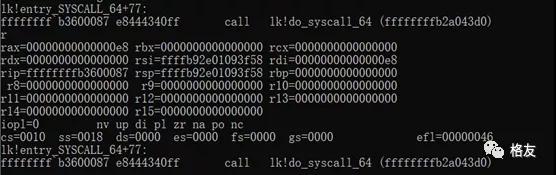
在征战这一关时,我的NDB发挥了很大作用,比如我在entry_SYSCALL_64入口设置断点,成功命中,这让我可以清楚观察CPU从用户空间飞到内核空间后刚刚着陆后的精确状态,每个寄存器的取值。
- rax=00000000000000e4 rbx=0000000000000001rcx=00007ffdc513099a // RIP
- rdx=00007f9b9dec9e10 rsi=00007f9b9dec9e10rdi=0000000000000001
- rip=ffffffffa3e00010 rsp=00007f9b9dec9db8rbp=00007f9b9dec9dc0
- r8=0000000000000000 r9=00007f9b9dec9e10 r10=00007f9b9dec9db0
- r11=0000000000000286 r12=00007f9b9dec9e10r13=0000000000000000
- r14=00007f9b9dec9e10 r15=00007f9b9dec9e20
- iopl=0 nv up di ng nz na po nc
- cs=0010 ss=0018 ds=0000 es=0000 fs=0000 gs=0000 efl=00010086
- lk!entry_SYSCALL_64:
- ffffffff`a3e00010 0f01f8 invlpg eaxds:0010:00007ffd`c512d080=00126362
其中rcx寄存器的值便是用户空间的程序指针,因为根据SYSCALL指令的定义,CPU会把rip保存到rcx,即上面注释中说的:
64-bit SYSCALL saves rip to rcx使用NDB反汇编这个值-2(减2是为了看到已经执行过的syscall指令)便可以看到用户空间发起系统调用的指令:
- u 007ffdc5130998
- 00007ffd`c5130998 0f05 syscall
- 00007ffd`c513099a 415c pop r12d
- 00007ffd`c513099c 5d pop rbp
- 00007ffd`c513099d c3 ret
- 00007ffd`c513099e a860 test al,0x60
- 00007ffd`c51309a0 7438 jz 00007ffdc51309da
- 00007ffd`c51309a2 4863c7 movsxd rax,edi
- 00007ffd`c51309a5 488d0dd4c6ffff lea rcx,[00007ffdc512d080]
顺便说一下,使用汇编语言编写的entry_SYSCALL_64函数准备pt_regs结构体的目的是为了给使用C语言编写的do_syscall_64函数准备参数。后者的第二个参数便是指向pt_regs结构体的指针,即:
- __visible void do_syscall_64(unsigned long nr, struct pt_regs *regs)
下面是准备调用C语言函数前的寄存器上下文:
和栈数据:
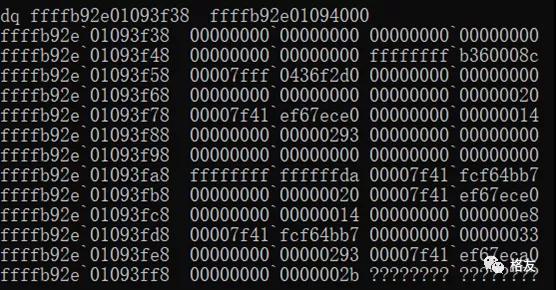
对于这个栈数据,不常做底层调试的同行可能满脸问号。对于我来说,几乎每个字节都非常亲切,像老朋友一样,因为它们都个性鲜明,16位的段选择子也住着64位的大房子(^-^)。
对于第二个困难,解决的难度更大,主要的步骤如下。
首先要通过per-cpu区找到当前任务指针,也就是current指针,参见我的上一篇文章。然后要通过current指针找到当前任务的地址空间描述,也就是mm_struct。然后找到mm_struct中的VMA链表,再遍历这个链表,筛选出其中的一个个so模块描述。
找到这些so模块描述后,还需要把这些描述报告给调试引擎,让调试引擎来加载用户空间的模块。
找到用户空间的栈和加载了用户空间的模块后,再观察栈回溯,便可以看到希望的曙光了。比如下面是11月21日时看到的场景:
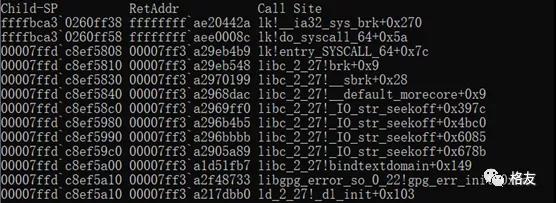
已经看到libc和著名的ld模块,这给我很大鼓励。
仔细观察上面这个栈回溯,容易看出libc中的函数名很不精确,用调试器分析,发现使用的libc符号文件缺少对栈回溯至关重要的帧信息。深究原因,让人晕倒。与Windows下的符号文件不同,Linux(以Ubuntu为例)的gcc编译时如果有-g选项,则会产生调试符号,与执行信息放在一个文件中。
包含符号信息的文件比较大,所以一般会通过所谓的strip过程产生一个消减符号的产品文件和一个用于调试的符号文件。比如使用下面这样的objcopy命令便可以产生一个专门用作调试的符号文件:
- gedu@gedu-VirtualBox:~/labs/gemalloc$ readelf --debug-dump=frames gemalloc.dbg
- section '.eh_frame' has the NOBITS type - its contents are unreliable.
用下面两条命令则可以产生一个适于发布到产品环境的不带符号版本:
- gedu@gedu-VirtualBox:~/labs/gemalloc$ cp gemalloc gemalloc.prd
- gedu@gedu-VirtualBox:~/labs/gemalloc$ objcopy --strip-debug gemalloc.prd
观察文件大小,是有明显差异的:

调试时,我们一般使用符号文件。因为大多数符号信息是放在符号文件中的。注意,这里是说大多数,并不是全部。比如帧信息,因为发生异常时做栈展开也需要,所以帧信息是放在产品文件中的。既然帧信息对于调试和正常执行都需要,按说应该两个文件都有一份,但事实上不是,至少上面截图中使用的libc符号文件里不包含帧信息,节的头仍在,但是标志位里有NOBITS标志,代表这个节的数据是不可靠的,解析时会失败。
比如,使用readelf命令来显示上面产生符号文件的帧信息,会得到如下提示:
- gedu@gedu-VirtualBox:~/labs/gemalloc$ readelf --debug-dump=frames gemalloc.dbg
- section '.eh_frame' has the NOBITS type - its contents are unreliable.
再附加个截图吧:

以下是readelf程序的有关源代码:
- if(section->sh_type == SHT_NOBITS)
- {
- /* There is no point in dumping the contents of a debugging section
- which has the NOBITS type - the bits in thefile will be random.
- This can happen when a file containing a.eh_frame section is
- stripped with the --only-keep-debug commandline option. */
- printf (_("section '%s' has the NOBITS type - its contents are unreliable.\n"),
- print_name);
- return 0;
怎么解决这个问题呢?就是要让NDB为一个模块加载两个符号文件。细节从略。
过了这一个难关后,便可以看到更好一些的栈回溯了。libc的函数名变得很精确。
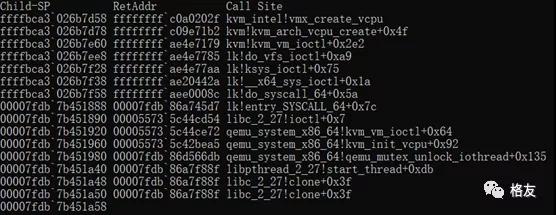
仔细观察上面的结果,美中不足的是最后三行,有两行重复clone函数,最后一行没有给出函数名,也没有显示出代表root的返回地址为0特征。
他山之石可以攻玉。使用gdb来做对比较实验,看到的是:
- (gdb) bt
- #0 thread_func (arg=0x9) at gemalloc.c:289
- #1 0x00007ffff68216ba in start_thread(arg=0x7fffc6ffd700)
- at pthread_create.c:333
- #2 0x00007ffff655741d in clone ()
- at../sysdeps/unix/sysv/linux/x86_64/clone.S:109
看来clone函数确实是线程的起点。gdb成功在起点处停车。可是ndb没有。
给调试器上调试器,调试NDB。仔细跟踪负责解析符号的ndw模块。
跟踪发现,ndw可以顺利找到clone函数的帧信息,即:
- 000146e80000000000000014 00000000 CIE
- Version: 1
- Augmentation: "zR"
- Code alignment factor: 1
- Data alignment factor: -8
- Return address column: 16
- Augmentation data: 1b
- DW_CFA_def_cfa: r7 (rsp) ofs 8
- DW_CFA_offset: r16 (rip) at cfa-8
DW_CFA_undefined:r16 (rip)
上面的DW_XX是DWARF标准里定义的栈回溯指令,可以理解为脚本语言。NDW内部的解释器顺利执行了前两条语句:
- DW_CFA_def_cfa: r7 (rsp) ofs 8
- DW_CFA_offset: r16 (rip) at cfa-8
但是在执行第三条语句时,懵圈了。
DW_CFA_undefined:r16 (rip)
我在跟踪这条语句对应的解释器代码时,以为遇到了不认识的指令,推测是版本兼容导致的。
反复跟踪和思索了很久,我终于领悟到了,这个undefined并不是我最初想的那样。它的含义不是说它是一条未定义的指令,而是要把它的操作数,也就是后面的rip寄存器设置为“未定义”状态。
某种程度来说,栈回溯就是在回滚寄存器的状态,而这个
DW_CFA_undefined:r16 (rip)
就是要把rip寄存器的状态回滚到“未定义状态”。也就是让它进入一个不知道为何值的状态。
在NDW的老代码中,对于这个情况,会把rip回滚到它的当前值(也就是不回滚),于是就出现了上面的clone函数的父函数还是clone函数的现象。
阅读libc中clone函数的源代码,可以找到这个DW_CFA_undefined指令的来源,是某位同行故意手工加入的。
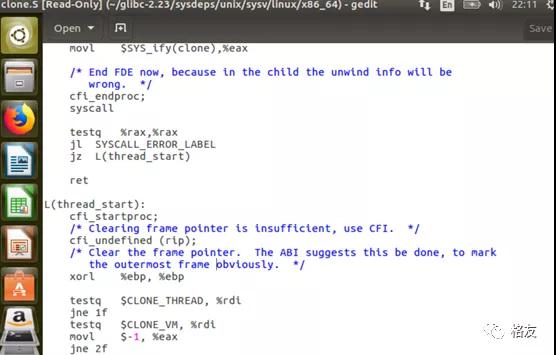
代码中的注释很有意思:故意加了这个undefined来标记到了最外层的栈帧,非常明显地!其实不加就挺好的。Anyway,也是用心良苦。
闭目思索,这里用的undefined也非常具有哲学意味。很多时候我们在寻找源头,可是最终的源头到底在哪里呢?我们找到的源头也未必就是真的源头。真的源头常常是未知的,也就是undefined。比如2020年的新冠病毒,人类能找到真的源头么?至少到今天,还是undefined。
如此想来,这种在线程源头标记为undefined的方法还真是意义非凡。
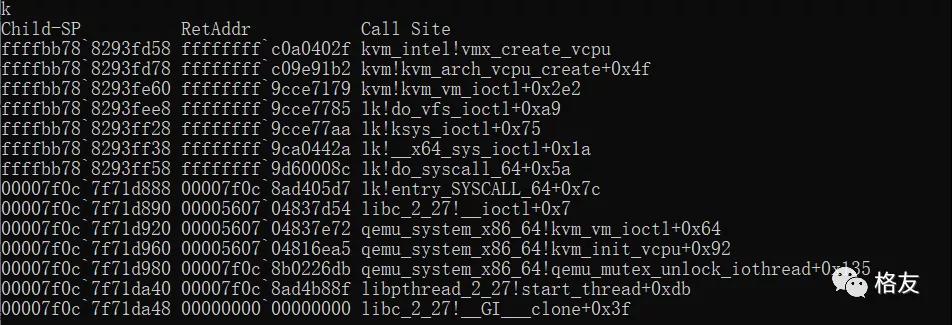
找到根源之后,我直接把这种undefined的回滚处理成回滚到0,问题便解决了,梦寐以求的完美栈回溯出现在眼前。
本文转载自微信公众号「格友」,可以通过以下二维码关注。转载本文请联系格友公众号。
















