













数据科学家和数据分析师经常需要回答业务问题。这可能会导致更临时的分析或某种形式的模型将被应用到公司的工作流程中。
但是要执行数据科学和分析,团队首先需要访问来自多个应用程序和业务流程的高质量数据。这意味着将数据从点a移动到点b。执行此操作的一般方法是使用自动化过程,简称为提取,转换和加载或ETL。这些ETL通常会将数据加载到某种形式的数据仓库中,以便于访问。但是,ETL和数据仓库存在一个主要问题。
尽管有必要,但ETL需要大量的编码,专门知识和维护。除了这项工作对于数据科学家来说是耗时的之外,并不是所有的数据科学家都具有开发ETL的经验。很多时候,这项工作将落在数据工程团队上,这些团队忙于更大的图片项目以引入基础数据层。
这并不总是与数据科学家的需求保持一致,数据科学家的需求可能会让拥有业务所有者的企业希望快速地进行信息和分析。等到数据工程团队有时间提取新的数据源可能不是一个好选择。
这就是为什么在过去的几年中开发了几种解决方案来减少数据科学家为获取所需数据而需要进行的工作量的原因。尤其是以数据虚拟化,自动ETL和无代码/低代码解决方案的形式。
自动化的ETL和数据仓库
尽管ETL本身是一个自动化过程。他们需要大量的手动开发和维护。
这导致了Panoply之类的工具的普及,该工具提供了易于集成的自动ETL和云数据仓库,可以与许多第三方工具(如Salesforce,Google Analytics和数据库)同步。使用这些自动集成,数据科学家可以快速分析数据,而无需部署复杂的基础架构。
无需Python或EC2实例。只需单击几下。然后,在大致了解您打算引入团队中的数据类型之后,便可以拥有一个填充的数据仓库。
这些自动化的ETL系统非常易于使用,通常只需要最终用户设置数据源和目标即可。从那里可以将ETL设置为在特定时间运行。全部没有任何代码。
产品实例:
> Image provided by the author.
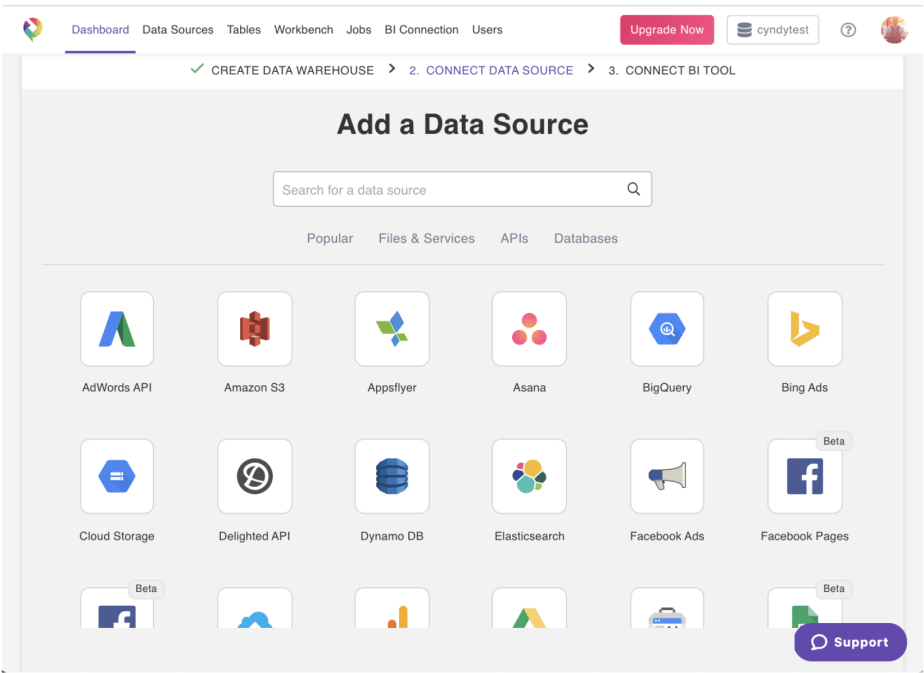
如前所述,Panoply是自动ETL和数据仓库的一个示例。
可以在Panoply GUI中设置整个摄取,您可以在其中选择源和目的地并自动摄取数据。因为Panoply带有内置的数据仓库,所以它会自动存储数据的副本,可以使用任何所需的BI或分析工具来查询数据的副本,而不必担心会危害操作或生产。以这种方式访问数据基础结构对于希望使事情简单但仍可以访问整个组织中几乎实时数据的用户来说是有意义的。
反过来,这使数据科学家能够回答临时问题,而无需等待BI团队将其带入数据仓库的四个星期。
优点:
- 易于学习和实施
- 专注于云
- 易于扩展
缺点:
- 自动化的数据仓库和ETL本身无法管理复杂的逻辑
- 更复杂的转换可能需要添加无代码/低代码ETL工具
无代码/低代码
无代码/低代码距离自动ETL几步之遥。这些类型的ETL工具具有更多的拖放方法。这意味着可以拖放一些设置转换和数据操作功能。其他类似的解决方案可能更多是基于GUI的,它允许用户指定源,目的地和转换。此外,这些无代码/低代码解决方案中的许多解决方案都允许最终用户查看是否需要编码并对其进行编辑。
对于没有代码经验的用户,这是一个很好的解决方案。无代码/低代码数据,科学家就可以开发语法有限的ETL,从而创建一些相当复杂的数据管道。无需建立大量复杂的基础架构来管理数据管道何时运行以及它们所依赖的内容。用户只需要从高层次上了解他们的数据在哪里,他们想去哪里以及什么时候要去那里。
缺点:
- 代码中的可定制性有限
- 每个工具都不相同,因此开发人员必须在下一份工作中重新学习ETL
- 无代码/低代码可能太容易了,并导致糟糕的高级设计
优点:
- 技术上没有编码经验
- 易于集成到许多受欢迎的第三方
- 许多是基于云的解决方案
产品实例:
> Image source: aws.amazon.com
此类别中有很多产品。有类似AWS Glue,Stitch和FiveTran的产品。
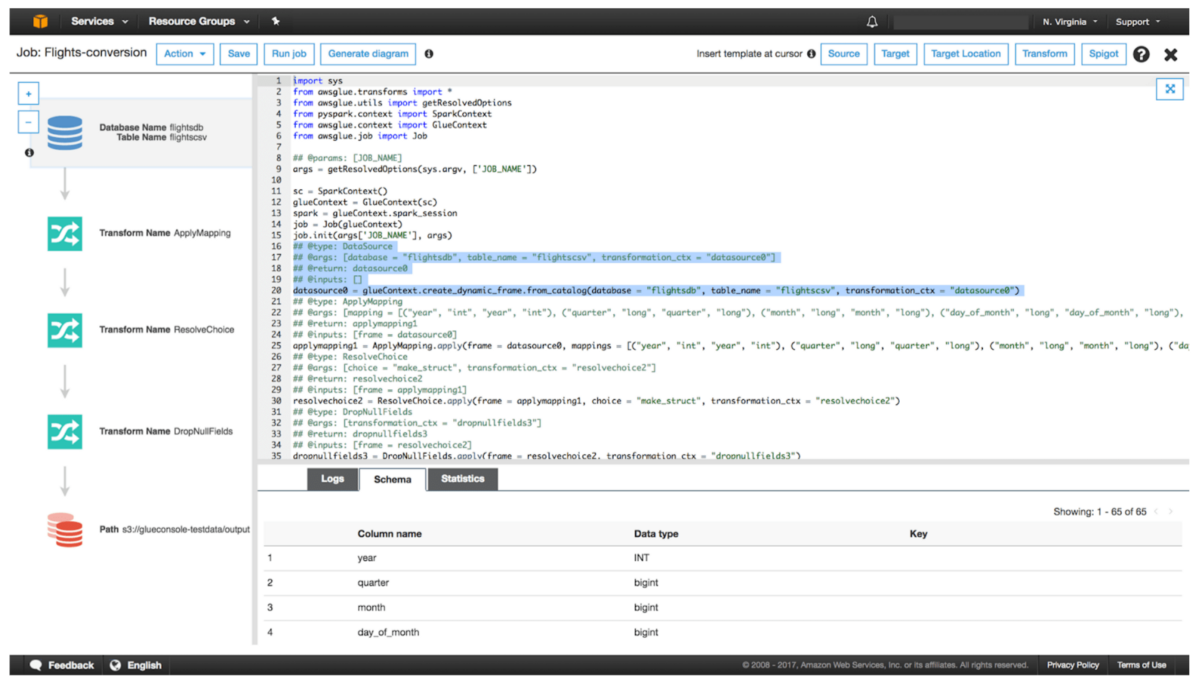
AWS Glue是基于云的现代ETL解决方案的一个很好的例子。这使开发人员只需单击几下即可设置作业,并设置参数。这可以使数据科学家无需太多代码即可移动和转换数据。
作为AWS一部分的Glue可以轻松地与其他服务集成,例如S3,RDS和Redshift。这使得在AWS上开发数据管道变得非常容易和直观。但是,AWS Glue有一个主要警告。与许多其他无代码/低代码选项不同,它是为在AWS上运行而开发的。这意味着,如果您突然决定切换到其他云提供商,则可能仅从Glue切换到其他解决方案就不得不花费大量时间和金钱。
最后,这是您的团队在开发ETL之前应考虑的重要考虑因素。
数据虚拟化
数据虚拟化是一种允许用户访问来自多个数据源,数据结构和第三方提供程序的数据的方法。它实质上创建了一个单层,无论使用哪种技术存储底层数据,最终用户都将可以通过单点访问它。
总体而言,当您的团队需要快速访问数据时,数据虚拟化具有许多优势。以下是一些数据虚拟化如何使您的团队受益的示例。
优点:
- 允许数据科学家混合来自多个数据库的数据
- 管理安全性和访问管理
- 实时或近实时数据
缺点:
- 高学习曲线
- 需要管理员来管理
- 仍然需要用户考虑设计和数据流
产品实例:
> Image provided by the author.
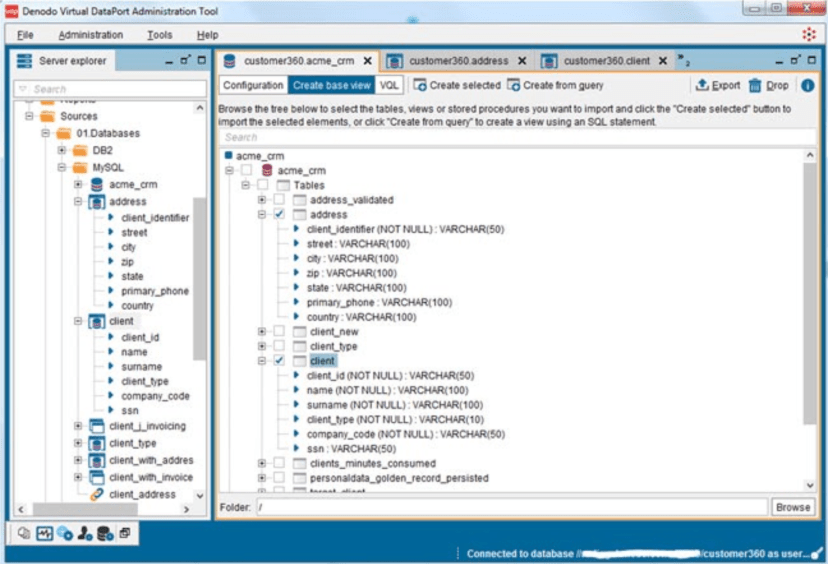
Denodo是最著名的数据虚拟化提供商之一。总体而言,该产品可以说是最成熟,功能最丰富的产品。
Denodo致力于帮助用户从本质上通过一项服务访问其数据,这使得它受到众多客户的欢迎。从医疗保健提供者到金融行业,都依赖Denodo来减轻BI开发人员和数据科学家的压力,因为它减少了创建尽可能多的数据仓库的必要性。
总体而言,这三个选项可以帮助您的团队分析数据,而无需花费很多精力来开发复杂的ETL。
结论
对于数据科学家和机器学习工程师而言,管理,混合和移动数据将继续是一项必不可少的任务。但是,开发这些管道及其相应的数据仓库的过程无需像过去那样花费很长时间。
通过自动集成系统或通过其他方法(例如无代码/低代码和数据虚拟化)来开发ETL,有很多不错的选择。如果您的团队希望减少数据工程师的工作量,则有很多选择。您的团队可能还需要组建一支新的数据科学团队,该团队需要立即将数据反馈给他们,然后使用Panoply之类的解决方案可能是个不错的选择。













