前言
由于编程思想与数据库的设计模式不同,生出了一些ORM框架。核心都是将关系型数据库和数据转成对象型。当前流行的方案有Hibernate与myBatis。两者各有优劣。竞争激烈,其中一个比较重要的考虑的地方就是性能。因此笔者通过各种实验,测出两个在相同情景下的性能相关的指数,供大家参考。
测试目标
以下测试需要确定几点内容:
性能差异的场景;
性能不在同场景下差异比;
找出各架框优劣,各种情况下的表现,适用场景。
测试思路
测试总体分成:单表插入,关联插入,单表查询,多表查询。
测试分两轮,同场景下默认参数做一轮,调优做强一轮,横纵对比分析了。
测试中尽保证输入输出的一致性。
样本量尽可能大,达到10万级别以上,减少统计误差。
测试提纲
具体的场景情况下
插入测试1:10万条记录插入。
查询测试1:100万数据中单表通过id查询100000次,无关联字段。
查询测试2:100万数据中单表通过id查询100000次,输出关联对象字段。
查询测试3:100万*50万关联数据中查询100000次,两者输出相同字段。
准备
数据库:mysql 5.6
表格设计:
twitter:推特
- CREATE TABLE `twitter` (
- `id` bigint(20) NOT NULL AUTO_INCREMENT,
- `add_date` datetime DEFAULT NULL,
- `modify_date` datetime DEFAULT NULL,
- `ctx` varchar(255) NOT NULL,
- `add_user_id` bigint(20) DEFAULT NULL,
- `modify_user_id` bigint(20) DEFAULT NULL,
- PRIMARY KEY (`id`),
- KEY `UPDATE_USER_FORI` (`modify_user_id`),
- KEY `ADD_USER_FORI` (`add_user_id`),
- CONSTRAINT `ADD_USER_FORI` FOREIGN KEY (`add_user_id`) REFERENCES `user` (`id`) ON DELETE SET NULL,
- CONSTRAINT `UPDATE_USER_FORI` FOREIGN KEY (`modify_user_id`) REFERENCES `user` (`id`) ON DELETE SET NULL
- ) ENGINE=InnoDB AUTO_INCREMENT=1048561 DEFAULT CHARSET=utf8
user: 用户
- CREATE TABLE `user` (
- `id` bigint(20) NOT NULL AUTO_INCREMENT,
- `name` varchar(255) DEFAULT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB AUTO_INCREMENT=524281 DEFAULT CHARSET=utf8
测试数据准备:
表一:twitter
无数据。
表二:user
50万个随机的用户名。
随机内容推特表(material_twitter)
无id,仅有随机字符串内容,共10万条。
用于插入控推特表。
生成数据代码,关联100个用户:
- insert into twitter(ctx,add_user_id,modify_user_id,add_date,modify_date)
- SELECT name,ROUND(RAND()*100)+1,ROUND(RAND()*100)+1,'2016-12-31','2016-12-31'
- from MATERIAL
生成数据代码,关联500000个用户:
- insert into twitter(ctx,add_user_id,modify_user_id,add_date,modify_date)
- SELECT name,ROUND(RAND()*500000)+1,ROUND(RAND()*500000)+1,'2016-12-31','2016-12-31'
- from MATERIAL
实体代码
- @Entity
- @Table(name = "twitter")
- public class Twitter implements java.io.Serializable{
- private Long id;
- private Date add_date;
- private Date modify_date;
- private String ctx;
- private User add_user;
- private User modify_user;
- private String createUserName;
- @Id
- @GeneratedValue(strategy = IDENTITY)
- @Column(name = "id", unique = true, nullable = false)
- public Long getId() {
- return id;
- }
- public void setId(Long id) {
- this.id = id;
- }
- @Temporal(TemporalType.DATE)
- @Column(name = "add_date")
- public Date getAddDate() {
- return add_date;
- }
- public void setAddDate(Date add_date) {
- this.add_date = add_date;
- }
- @Temporal(TemporalType.DATE)
- @Column(name = "modify_date")
- public Date getModifyDate() {
- return modify_date;
- }
- public void setModifyDate(Date modify_date) {
- this.modify_date = modify_date;
- }
- @Column(name = "ctx")
- public String getCtx() {
- return ctx;
- }
- public void setCtx(String ctx) {
- this.ctx = ctx;
- }
- @ManyToOne(fetch = FetchType.LAZY)
- @JoinColumn(name = "add_user_id")
- public User getAddUser() {
- return add_user;
- }
- public void setAddUser(User add_user) {
- this.add_user = add_user;
- }
- @ManyToOne(fetch = FetchType.LAZY)
- @JoinColumn(name = "modify_user_id")
- public User getModifyUser() {
- return modify_user;
- }
- public void setModifyUser(User modify_user) {
- this.modify_user = modify_user;
- }
- @Transient
- public String getCreateUserName() {
- return createUserName;
- }
- public void setCreateUserName(String createUserName) {
- this.createUserName = createUserName;
- }
- }
开始
插入测试1
代码操作:
将随机内容推特表的数据加载到内存中,然后一条条加入到推特表中,共10万条。
关键代码:
hibernate:
- Session session = factory.openSession();
- session.beginTransaction();
- Twitter t = null;
- Date now = new Date();
- for(String materialTwitter : materialTwitters){
- // System.out.println("materialTwitter="+materialTwitter);
- t = new Twitter();
- t.setCtx(materialTwitter);
- t.setAddDate(now);
- t.setModifyDate(now);
- t.setAddUser(null);
- t.setModifyUser(null);
- session.save(t);
- }
- session.getTransaction().commit();
mybatis:
- Twitter t = null;
- Date now = new Date();
- for(String materialTwitter : materialTwitters){
- // System.out.println("materialTwitter="+materialTwitter);
- t = new Twitter();
- t.setCtx(materialTwitter);
- t.setAddDate(now);
- t.setModifyDate(now);
- t.setAddUser(null);
- t.setModifyUser(null);
- msession.insert("insertTwitter", t);
- }
- msession.commit();
TwitterMapper.xml,插入代码片段:
- <insert id="insertTwitter" keyProperty="id" parameterType="org.pushio.test.show1.entity.Twitter" useGeneratedKeys="true">
- insert into twitter(ctx, add_date,modify_date) values (#{ctx},#{add_date},#{modify_date})
- </insert>
查询测试1
通过id从1递增到10万依次进行查询推特内容,仅输出微博内容。
关键代码:
hibernate:
- long cnt = 100000;
- for(long i = 1; i <= cnt; ++i){
- Twitter t = (Twitter)session.get(Twitter.class, i);
- //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName());
- }
mybatis:
- long cnt = 100000;
- for(long i = 1; i <= cnt; ++i){
- Twitter t = (Twitter)msession.selectOne("getTwitter", i);
- //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName());
- }
查询测试2
与查询测试1总体一样,增加微博的创建人名称字段,此处需要关联。
其中微博对应有10万个用户。可能一部份用户重复。这里对应的用户数可能与hibernate配懒加载的情况有影响。
此处体现了hibernate的一个方便处,可以直接通过getAddUser()可以取得user相关的字段。
然而myBatis则需要编写新的vo,因此在测试batis时则直接在Twitter实体中增加创建人员名字成员(createUserName)。
此处hibernate则会分别测试有懒加载,无懒加载。
mybatis会测有默认与有缓存两者情况。
其中mybatis的缓存机制比较难有效配置,不适用于真实业务(可能会有脏数据),在此仅供参考。
测试时,对推特关联的用户数做了两种情况,一种是推特共关联了100个用户,也就是不同的推特也就是在100个用户内,这里的关联关系随机生成。
另外一种是推特共关联了50万个用户,基本上50个用户的信息都会被查询出来。
在上文“准备”中可以看到关联数据生成方式。
关键代码:
hibernate:
- long cnt = 100000;
- for(long i = 1; i <= cnt; ++i){
- Twitter t = (Twitter)session.get(Twitter.class, i);
- t.getAddUser().getName();//加载相应字段
- //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName());
- }
急懒加载配置更改处,Twitter.java:
- @ManyToOne(fetch = FetchType.EAGER)//急加载
- //@ManyToOne(fetch = FetchType.LAZY)//懒加载
- @JoinColumn(name = "add_user_id")
- public User getAddUser() {
- return add_user;
- }
mybatis:
- for(long i = 1; i <= cnt; ++i){
- Twitter t = (Twitter)msession.selectOne("getTwitterHasUser", i);
- //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getCreateUserName());
- }
TwitterMapper.xml配置:
- <select id="getTwitterHasUser" parameterType="long"
- resultType="org.pushio.test.show1.entity.Twitter">
- select twitter.*,user.name as creteUserName from twitter,user
- where twitter.id=#{id}
- AND twitter.add_user_id=user.id
- </select>
测试结果
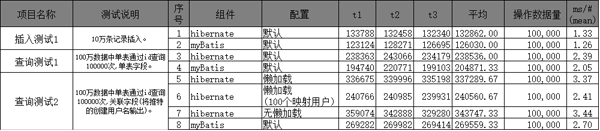
测试分析
测试分成了插入,单表查询,关联查询。关联查询中hibernate分成三种情况进行配置。其中在关联字段查询中,hibernate在两种情况下,性能差异比较大。都是在懒加载的情况下,如果推特对应的用户比较多时,则性能会比仅映射100个用户的情况要差很多。
换而言之,如果用户数量少(关联的总用户数)时,也就是会重复查询同一个用户的情况下,则不需要对用户表做太多的查询。其中通过查询文档后,证明使用懒加载时,对象会以id为key做缓存,也就是查询了100个用户后,后续的用户信息使用了缓存,使性能有根本性的提高。甚至要比myBatis更高。
如果是关联50万用户的情况下,则hibernate需要去查询50万次用户信息,并组装这50万个用户,此时性能要比myBatis性能要差,不过差异不算大,小于1ms,表示可以接受。其中hibernate非懒加载情况下与myBatis性能差异也是相对其他测试较大,平均值小于1ms。
这个差异的原因主要在于,myBatis加载的字段很干净,没有太多多余的字段,直接映身入关联中。反观hibernate则将整个表的字都会加载到对象中,其中还包括关联的user字段。
hibernate这种情况下有好有坏,要看具体的场景,对于管理平台,需要展现的信息较多,并发要求不高时,hibernate比较有优势。
然而在一些小活动,互联网网站,高并发情况下,hibernate的方案太不太适合,myBatis+VO则是首选。
测试总结
总体初观,myBatis在所有情况下,特别是插入与单表查询,都会微微优于hibernate。不过差异情况并不明显,可以基本忽略差异。差异比较大的是关联查询时,hibernate为了保证POJO的数据完整性,需要将关联的数据加载,需要额外地查询更多的数据。这里hibernate并没有提供相应的灵活性。
关联时一个差异比较大的地方则是懒加载特性。其中hibernate可以特别地利用POJO完整性来进行缓存,可以在一级与二级缓存上保存对象,如果对单一个对象查询比较多的话,会有很明显的性能效益。以后关于单对象关联时,可以通过懒加载加二级缓存的方式来提升性能。
最后,数据查询的性能与orm框架关无太大的关系,因为orm主要帮助开发人员将关系数据转化成对象型数据模型,对代码的深析上来看,hibernate设计得比较重量级,对开发来说可以算是重新开发了一个数据库,不让开发去过多关心数据库的特性,直接在hibernate基础上进行开发,执行上分为了sql生成,数据封装等过程,这里花了大量的时间。
然而myBatis则比直接,主要是做关联与输出字段之间的一个映射。其中sql基本是已经写好,直接做替换则可,不需要像hibernate那样去动态生成整条sql语句。
好在hibernate在这阶段已经优化得比较好,没有比myBatis在性能上差异太多,但是在开发效率上,可扩展性上相对myBatis来说好太多。最后的最后,关于myBatis缓存,hibernate查询缓等,后续会再专门做一篇测试。
关于缓存配置
myBatis相对Hibernate 等封装较为严密的ORM 实现而言,因为hibernate对数据对象的操作实现了较为严密的封装,可以保证其作用范围内的缓存同步,而ibatis 提供的是半封闭的封装实现,因此对缓存的操作难以做到完全的自动化同步。以上的缓存配置测试仅为性能上的分析,没有加入可用性上的情况,因为myBatis直接配置缓存的话,可能会出现脏数据。
在关联查询数据的情况下,hiberntae的懒加载配二级缓存是个比较好的方案(无脏数据),也是与myBatis相比有比较明显的优势。此情景下,性能与myBatis持平。
在真实情况下,myBatis可能不会在这个地方上配置缓存,会出现脏数据的情况,因而很有可能在此hibernate性能会更好。