












前言
先来看看Redis客户端和服务端的交互模型
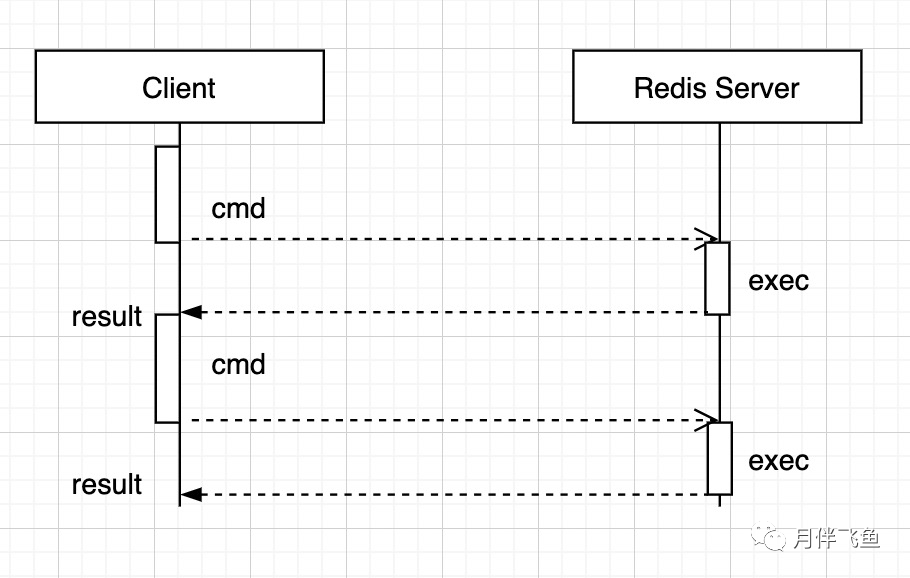
可以得出:
1.Redis是基于一个Request,一个Response的同步请求服务
2.客户端将数据包发送至服务器,然后服务器再将响应数据发送回客户端,这都需要花费一定时间的。这段时间被称为往返时间RTT(Round Trip Time)。
当一个客户端需要连续执行很多请求时,就很容易看出往返时间是影响系统性能的
例如:如果往返时间RTT是250毫秒,即使Redis服务器每秒钟能处理1000个请求,我们也只能每秒钟最多处理四个请求。
Redis提供了一种Pipeline(管道)方法可以改善上述用例的性能,下面看看。
Redis Pipeline交互模型
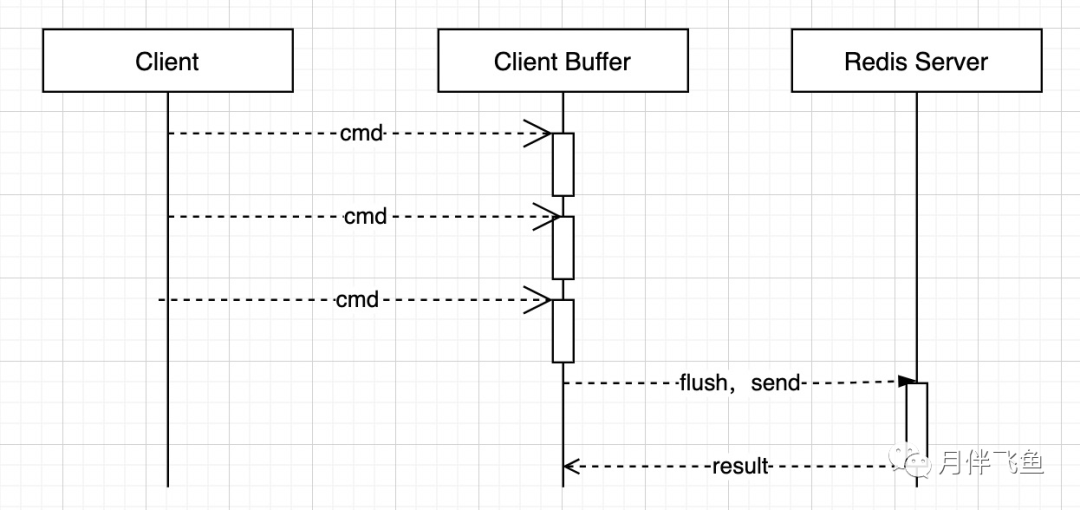
可以看到,客户端首先将执行的命令写入到缓冲区(内存)中,最后再一次性发送 Redis。
pipeline通过将一批命令进行打包,然后发送给服务器,服务器执行完按顺序打包返回,这样就减少了频繁交互往返的时间,提升了性能
基本使用
Pipeline pipeline =jedis.pipelined();
// 循环添加 1000个元素
for(int i = 0; i < 1000; i++){
pipeline.rpush("rediskey", i + "");
}
//执行
pipeline.sync()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
使用起来还是很简单的
Pipeline的本质
我们深入分析一个请求交互的流程,真实的情况是它很复杂的
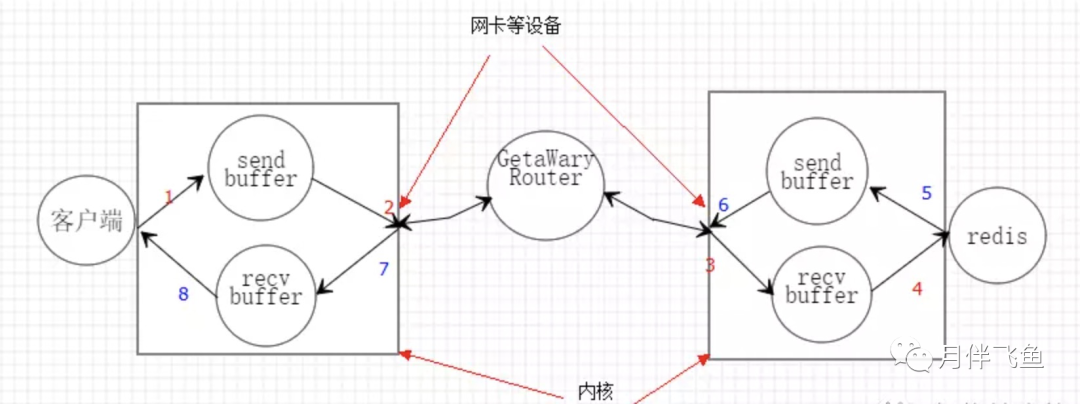
上图就是一个完整的请求交互流程图:
- 客户端调用write将消息写到操作系统内核为套接字分配的发送缓冲中send buffer
- 系统内核将缓冲区的内容发送到网卡,网卡硬件将数据通过路由送到服务器的网卡
- 服务器网卡将数据放到内核为套接字分配的接收缓冲中recive buffer
- 服务器调用read从接收缓冲中取出消息进行处理
- 服务器调用write将响应内容发送到send bffer中
- 服务器内核将缓冲区的内容通过路由发送到客户端的网卡中
- 客户端内核将网卡中的数据放到接收缓冲中recive buffer
- 客户端调用read从缓冲中读取数据
总结
我们开始以为 write 操作是要等到对方收到消息才会返回,但实际上不是这样的。
- 写操作 IO 操作的真正耗时
write 操作只负责将数据写到本地操作系统内核的发送缓冲然后就返回了。剩下的事交给操作系统内核异步将数据送到目标机器。但是如果发送缓冲满了,那么就需要等待缓冲空出空闲空间来,这个就是写操作 IO 操作的真正耗时。
- 读操作 IO 操作的真正耗时
我们开始以为 read 操作是从目标机器拉取数据,但实际上不是这样的。read 操作只负 责将数据从本地操作系统内核的接收缓冲中取出来就了事了。但是如果缓冲是空的,那么就 需要等待数据到来,这个就是读操作 IO 操作的真正耗时。
- value = redis.get(key)操作耗时
对于 value = redis.get(key)这样一个简单的请求来说,write 操作几乎没有耗时,直接 写到发送缓冲就返回,而 read 就会比较耗时了,因为它要等待消息经过网络路由到目标机器 处理后的响应消息,再回送到当前的内核读缓冲才可以返回。
- 管道的真正耗时
对于管道来说,连续的 write 操作根本就没有耗时,之后第一个 read 操作会等待一个 网络的来回开销,然后所有的响应消息就都已经回送到内核的读缓冲了,后续的 read 操作 直接就可以从缓冲拿到结果,瞬间就返回了。
优缺点
Pipeline的优点:
pipeline 通过打包命令,一次性执行,可以节省连接->发送命令->返回结果这个过程所产生的往返时间,减少的I/O的调用(用户态到内核态之间的切换)次数。
Pipeline的缺点:
- pipeline 每批打包的命令不能过多,因为 pipeline 方式打包命令再发送,那么 redis 必须在处理完所有命令前先缓存起所有命令的处理结果。这样就有一个内存的消耗。
- pipeline不保证原子性,执行命令过程中,如果一个命令出现异常,也会继续执行其他命令,所以如果要求原子性的,不推荐使用 pipeline
- pipeline每次只能作用在一个Redis节点上(下面会解释原因)
适用场景
有些系统可能对可靠性要求很高,每次操作都需要立马知道这次操作是否成功,是否数据已经写进redis了,那这种场景就不适合。
有的系统,可能是批量的将数据写入redis,允许一定比例的写入失败,那么这种场景就可以使用了,比如10000条一下进入redis,可能失败了2条无所谓,后期有补偿机制就行了
比如短信群发这种场景,如果一下群发10000条,按照第一种模式去实现,那这个请求过来,要很久才能给客户端响应,这个延迟就太长了,如果客户端请求设置了超时时间5秒,那肯定就抛出异常了,而且本身群发短信要求实时性也没那么高,这时候用pipeline最好了。
使用建议
Pipeline虽然好用,但是每次Pipeline组装的命令个数不能没有节制,否则一次组装Pipeline数据量过大,一方面会增加客户端的等待时间,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成
Pipeline压力测试
Redis 自带了一个压力测试工具 redis-benchmark,使用这个工具就可以进行管道测试。
小贴士:redis-benchmark官方文档:https://redis.io/topics/benchmarks
首先我们对一个普通的 set 指令进行压测,QPS 大约 5w/s。
> redis-benchmark -t set -q
SET: 51975.05 requests per second
- 1.
- 2.
我们加入管道选项-P 参数,它表示单个管道内并行的请求数量,看下面 P=2,QPS 达到 了 9w/s。
> redis-benchmark -t set -P 2 -q
SET: 91240.88 requests per second
- 1.
- 2.
再看看 P=3,QPS 达到了 10w/s。
SET: 102354.15 requests per second
- 1.
其他问题
为什么pipeline只能作用在一个Redis节点上,即集群模式下不能使用pipeline?
我们知道,Redis 集群的键空间被分割为 16384 个槽(slot),每个主节点都负责处理 16384 个哈希槽的其中一部分。
具体的redis命令,会根据key计算出一个槽位(slot),然后根据槽位去特定的节点redis上执行操作。如下所示:
master1(slave1): 0~5460
master2(slave2):5461~10922
master3(slave3):10923~16383
- 1.
- 2.
- 3.
集群有三个master节点组成,其中master1分配了 0~5460的槽位,master2分配了 5461~10922的槽位,master3分配了 10923~16383的槽位。
一次pipeline会批量执行多个命令,那么每个命令都需要根据key运算一个槽位(CRC16.getSlot(key)),然后根据槽位去特定的节点上执行命令,也就是说一次pipeline操作会使用多个节点的redis连接,而目前是无法支持的
小贴士:不了解Redis集群知识的,可以参考:https://redis.io/topics/cluster-tutorial
pipeline和mget、mset等批量操作区别?
mget,mset也是类似 pipeline,将多个命令一次执行,一次发送出去,节省网络时间。
对比如下:
mset,mget操作在Redis队列中是一个原子操作,pipeline不是原子操作
mset,mget操作一个命令对应多个键值对,而pipeline是多条命令
mset,mget是服务端实现,而pipeline是服务端和客户端共同完成
pipeline和事务区别?
pipeline关注的是RTT时间,而事务关注的是一致性
- pipeline是一次请求,服务端顺序执行,一次返回,事务多次请求(MULTI命令+其他n个命令+EXEC命令,所以至少是2次请求),服务端顺序执行,一次返回。
- 集群模式下,使用pipeline时,slot槽必须是对的,不然服务端会返回redirecred to slot xxx的错误;同时不建议使用事务,因为假设一个事务中的命令即在Master A上执行,也在Master B执行,A成功了,B因为某种原因失败了,这样数据就不一致了,这个有点类似于分布式事务,无法保证绝对一致性。
Pipeline对命令数量是否有限制?
没有限制,但是打包的命令不能过多,对内存的消耗就越大。
Pipeline打包执行多少命令合适?
查询 Redis 官方文档,根据官方文档的解释,推荐是以 10k 每批 (注意:这个是一个参考值,请根据自身实际业务情况调整)。
Pipeline批量执行的时候,是否导致其他应用无法再进行读写?
Redis 采用多路I/O复用模型,非阻塞IO,所以Pipeline批量写入的时候,一定范围内不影响其他的读操作。
本文转载自微信公众号「月伴飞鱼」,可以通过以下二维码关注。转载本文请联系月伴飞鱼公众号。日常加油站



















