













本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗 。转载本文请联系小姐姐味道公众号。
监控的重要性就不必多说了吧,不要再花功夫开会讨论它的必要性了,当你线上遇到问题,就不会再怀疑监控是浪费开发成本的建设。监控让人告别了靠“猜”来维持的救火现状,它能够留下证据,来支撑我们后续的分析。
作为监控的首要目标,服务的存活性,也就是它的健康状况,成为了重中之重。SpringBoot可以通过简单的参数,来开启健康检查,并能够和主流的监控系统集成起来。
1. 监控开启
在Spring中,是使用actuator组件,来做监控等相关操作。可以在pom中加入下面的starter:
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-actuator</artifactId>
- </dependency>
对于gradle来说,加入下面这个。
- dependencies {
- compile("org.springframework.boot:spring-boot-starter-actuator")
- }
访问/actuator/health,即可获取项目的健康状况。
- {"status":"UP"}
在application.yml文件里,加入如下的内容:
- management:
- endpoint:
- health:
- show-details: always
再次访问这个接口,将输出详细的内容。包括DB的状态、磁盘状态等。可以看到,最外层的status,其实是内部各个组件状态的集合。
- {
- "status":"UP",
- "components":{
- "db":{
- "status":"UP",
- "details":{
- "database":"H2",
- "validationQuery":"isValid()"
- }
- },
- "diskSpace":{
- "status":"UP",
- "details":{
- "total":250685575168,
- "free":31373905920,
- "threshold":10485760,
- "exists":true
- }
- },
- "ping":{
- "status":"UP"
- }
- }
- }
2. 自定义Indicator
这些功能,是由Indicators来实现的(HealthIndicator)。比如下面这些:
- DataSourceHealthIndicator
- DiskSpaceHealthIndicator
- CouchbaseHealthIndicator
- MongoHealthIndicator
- RedisHealthIndicator
- CassandraHealthIndicator
如果你是用的是组件提供的starter,这些Indicator就会在/health接口进行聚合,如果你不想要监控某个组件,可以在配置中把它关闭。
- management:
- health:
- mongo:
- enabled: false
明白了这个道理,在做一些组件的时候时候,就可以通过这种方式,来提供组件自带的健康检查:只需要实现HealthIndicator接口就可以了。代码样例如下:
- @Component
- @Slf4j
- public class X implements HealthIndicator {
- @Override
- public Health health() {
- try {
- //检查组件状态异常信息
- } catch (Exception e) {
- log.warn("Failed to connect to: {}", URL);
- return Health.down()
- .withDetail("error", e.getMessage())
- .build();
- }
- return Health.up().build();
- }
- }
3. 接入监控系统
更多情况,我们是希望把业务监控的数据,使用专业的监控组件收集起来。这个在SpringBoot中,可以使用micrometer来实现。
以最流行的prometheus为例,在pom里增加下面的内容。
- <dependency>
- <groupId>io.micrometer</groupId>
- <artifactId>micrometer-registry-prometheus</artifactId>
- </dependency>
当然,我们也要在yaml里配置一些内容。它现在看起来长这个样子:
- management:
- endpoints:
- web:
- exposure:
- include: health,info,prometheus
- endpoint:
- health:
- show-details: always
这时候,访问/actuator/prometheus,即可获取prometheus格式的监控数据。
类似于下面这种:
- jvm_memory_used_bytes{area="heap",id="PS Survivor Space",} 0.0
- jvm_memory_used_bytes{area="heap",id="PS Old Gen",} 2.9444904E7
- jvm_memory_used_bytes{area="heap",id="PS Eden Space",} 6.829E7
- jvm_memory_used_bytes{area="nonheap",id="Metaspace",} 5.917196E7
- jvm_memory_used_bytes{area="nonheap",id="Code Cache",} 1.0929088E7
- jvm_memory_used_bytes{area="nonheap",id="Compressed Class Space",} 8420512.0
在prometheus的target页面,可以看到下面的信息:

最终在Grafana里,长的更加妖艳一些。
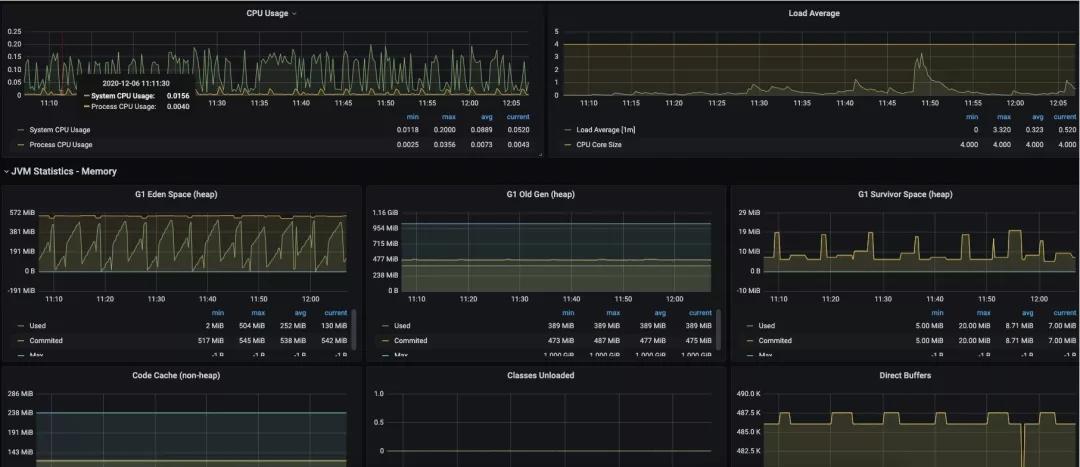
那它都能监控一些什么东西呢?我们来看一下:
- 服务节点基本信息,包括内存CPU网络IO等
- JVM堆栈信息
- JVM GC信息,STW信息
- 默认HikariCP的连接池信息
- HTTP请求接口信息(最大耗时,QPS最高)
- Tomcat容器监控
- Logback日志打印监控(各级别条数)
- ...其他
可以看到,只需要暴露这么一个接口,就可以对项目中的组件,进行比较全面的掌控。
4. 与容器配合
最后一点,由于SpringBoot服务,经常会发布到一些容器中,比如docker。这个时候,就要用到probes配置(kube有相同的概念)。probes是探测的意思,用来区分Liveness和Readiness两种状态。
最终的配置如下:
- management:
- health:
- probes:
- enabled: true
- endpoints:
- web:
- exposure:
- include: health,info,prometheus
- endpoint:
- health:
- show-details: always
这时候,我们将在浏览器的接口中获取两个分组,展示如下:
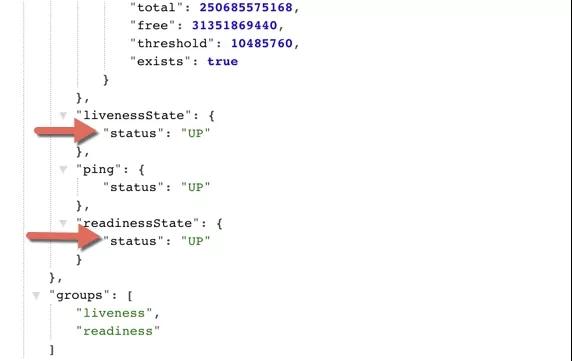
- http://localhost:8080/actuator/health/liveness
- http://localhost:8080/actuator/health/readiness
这两个链接,前者用于判断容器是否应该重启;后者判断服务是否可用,如果可用,将开始接受外部的请求。
End
对于规模比较小的SpringBoot应用来说,使用SpringBootAdmin一类的监控,就已经足够了。但如果你的企业是集中式部署,节点多且变化频繁,一个统一的监控建设平台是非常必要的。
除了Prometheus,SpringBoot的Metrics还支持以下组件:
- AppOptics
- Atlas
- Datadog
- Dynatrace
- Elastic
- Ganglia
- Graphite
- Humio
- Influx
- JMX
- KairosDB
- New Relic
- Prometheus
- SignalFx
- Simple (in-memory)
- Stackdriver
- StatsD
- Wavefront
你熟悉的组件,有没有它的身影呢?
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
























