前言
JDK5中引入了CyclicBarrier和CountDownLatch这两个并发控制类,而JDK7中引入的Phaser按照官方的说法是提供了一个功能类似但是更加灵活的实现。接下来我们带着几个问题来研究一下Phaser与(CountDownLath、CyclicBarrier)到底有哪些类似,同时带来了哪些灵活性?
- Phaser 是什么?
- Phaser 具有哪些特性?
- Phaser相对于 CyclicBarrier 和 CountDownLatch的优势?
CyclicBarrier和CountDownLatch
CyclicBarrier介绍
在使用CyclicBarrier时,需要创建一个CyclicBarrier对象,构造函数需要一个整数作为参数,这个参数是一个“目标”,在CyclicBarrier对象创建后,内部会有一个计数器,初始值为0,CyclicBarrier对象的await方法每被调用一次,这个计数器就会加1,一旦这个计数器的值达到设定的“目标”,所有被CyclicBarrier.await阻塞住的线程都会继续执行。这个目标是固定的,一旦设定便不能修改。
举一个例子,假设有5个人爬香山,他们要爬到山顶,等到5个人到齐了再同时出发下山,那么我们要在山顶设定一个“目标”,同时还有一个计数器,这个目标就是5,每一个人到山顶后,这个人就要等待,同时计数器加1,等到5个人到齐了,也就是计数器达到了这个“目标”,所有等待的人就开始下山了。 更多内容请阅读《并发编程之CyclicBarrier原理与使用》
CountDownLathch介绍
使用CountDownLatch时,需要创建一个CountDownLatch对象,构造函数也需要一个整数作为参数,可以把这个参数想象成一个倒计时器,CountDownLatch对象本身是一个发令枪,所有调用CountDownLatch.await方法的线程都会等待发令枪的指令,一旦倒计时器为0,这些线程同时开始执行,而CountDownLatch.countDown方法就是为倒计时器减1。
更多内容请阅读《并发编程之CountDownLatch原理与使用》
对比分析
CyclicBarrier和CountDownLatch的共同点都是有一个目标和一个计数器,等到计数器达到目标后,所有阻塞的线程都将继续执行。它们的不同点是CyclicBarrier.await在等待的同时还修改计数器,而CountDownLatch.await只负责等待,CountDownLatch.countDown才修改计数器。
CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
- CountDownLatch一般用于一个或多个线程,等待其他线程执行完任务后,再才执行;
- CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
- CountDownLatch 是一次性的,CyclicBarrier 是可循环利用的;
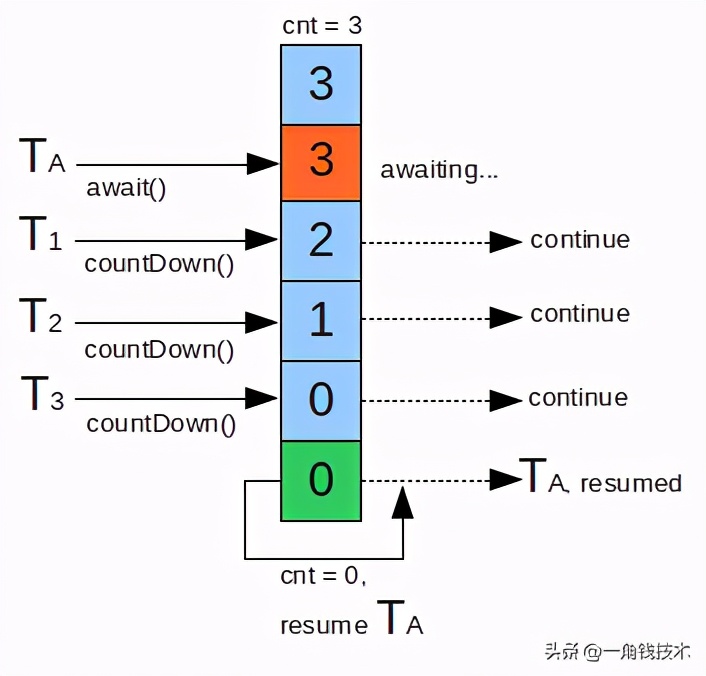
- CountDownLathch是一个计数器,线程完成一个记录一个,计数器递减,只能用一次。如下图:
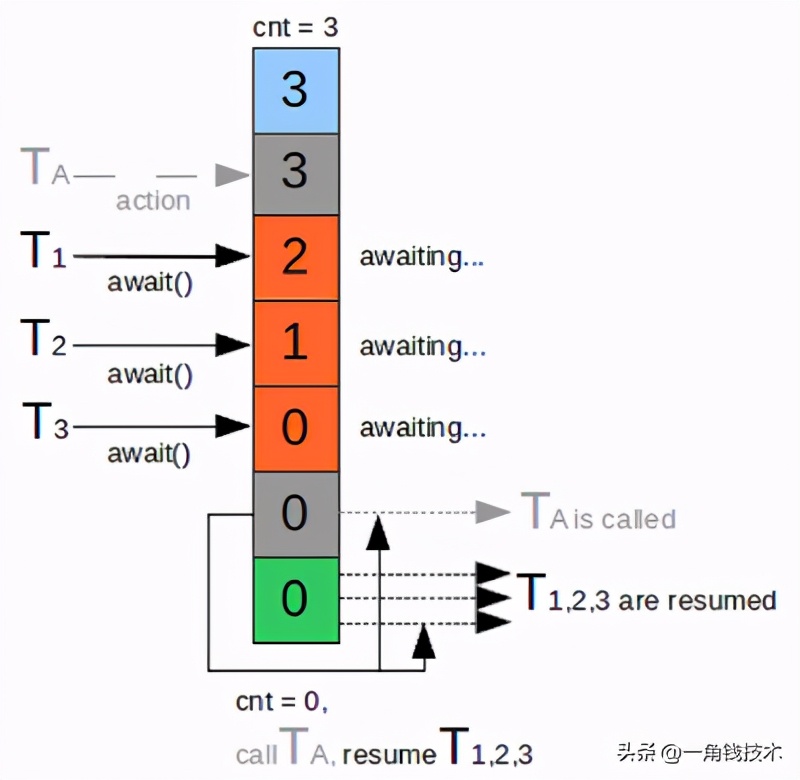
CyclicBarrier的计数器更像一个阀门,需要所有线程都到达,然后继续执行,计数器递减,提供reset功能,可以多次使用。如下图:
Phaser是什么?
Phaser,翻译为移相器(阶段),它适用于这样一种场景,一个大任务可以分为多个阶段完成,且每个阶段的任务可以多个线程并发执行,但是必须上一个阶段的任务都完成了才可以执行下一个阶段的任务。
这种场景虽然使用CyclicBarrier 或者 CountDownLatch 也可以实现,但是要复杂的多,首先,具体需要多少个阶段是可能变的,其次,每个阶段的任务数也可能会变的。相比于CyclicBarrier 和 CountDownLath ,Phaser更加灵活更加方便。
Phaser使用方法
Phaser同时包含CyclicBarrier和CountDownLatch两个类的功能。
- Phaser的arrive方法将将计数器加1,awaitAdvance将线程阻塞,直到计数器达到目标,这两个方法与CountDownLatch的countDown和await方法相对应;
- Phaser的arriveAndAwaitAdvance方法将计数器加1的同时将线程阻塞,直到计数器达到目标后继续执行,这个方法对应CyclicBarrier的await方法。
除了包含以上两个类的功能外,Phaser还提供了更大的灵活性。CyclicBarrier和CountdownLatch在构造函数指定目标后就无法修改,而Phaser提供了register和deregister方法可以对目标进行动态修改。
下面看一个最简单的使用案例:
- package com.niuh.tools;
- import java.util.concurrent.Phaser;
- /**
- * <p>
- * Phaser示例
- * </p>
- */
- public class PhaserRunner {
- // 定义每个阶段需要执行3个小任务
- public static final int PARTIES = 3;
- // 定义需要4个阶段完成的大任务
- public static final int PHASES = 4;
- public static void main(String[] args) {
- Phaser phaser = new Phaser(PARTIES) {
- @Override
- protected boolean onAdvance(int phase, int registeredParties) {
- System.out.println("==phase: " + phase + " finished==");
- return super.onAdvance(phase, registeredParties);
- }
- };
- for (int i = 0; i < PARTIES; i++) {
- new Thread(() -> {
- for (int j = 0; j < PHASES; j++) {
- System.out.println(String.format("%s: phase: %d", Thread.currentThread().getName(), j));
- phaser.arriveAndAwaitAdvance();
- }
- }, "Thread " + i).start();
- }
- }
- }
这里我们定义个需要4个阶段完成的大任务,每个阶段需要3个小任务,针对这些小任务,我们分别起3个线程来执行这些小任务,查看输出结果为:
- Thread 2: phase: 0
- Thread 0: phase: 0
- Thread 1: phase: 0
- ==phase: 0 finished==
- Thread 2: phase: 1
- Thread 1: phase: 1
- Thread 0: phase: 1
- ==phase: 1 finished==
- Thread 1: phase: 2
- Thread 2: phase: 2
- Thread 0: phase: 2
- ==phase: 2 finished==
- Thread 1: phase: 3
- Thread 0: phase: 3
- Thread 2: phase: 3
- ==phase: 3 finished==
可以看到,每个阶段都是三个线程都完成来才进入下一个阶段。这是怎么实现的呢?
Phaser原理猜测
结合AQS的原理,大概猜测一下Phaser的实现原理:
- 首先,需要存储当前阶段phase、当前阶段的任务数(参与者)parties、未完成参与者的数量,这三个变量我们可以放在一个变量state中存储。
- 其次,需要一个队列存储先完成的参与者,当最后一个参与者完成任务时,需要唤醒队列中的参与者。
结合上面的案例带入:初始时当前阶段为0,参与者为3个,未完成参与者数为3;
- 第一个线程执行到 phaser.arriveAndAwaitAdvance(); 时进入队列;
- 第二个线程执行到 phaser.arriveAndAwaitadvance(); 时进入队列;
- 第三个线程执行到 phaser.arriveAndAwaitadvance(); 时先执行这个阶段的总结 onAdvance(), 再唤醒签名两个线程继续执行下一个阶段的任务。
基于这样的一个思路,整体能说的通,至于是不是这样?让我们一起来看源码吧。
Phaser源码分析
主要API
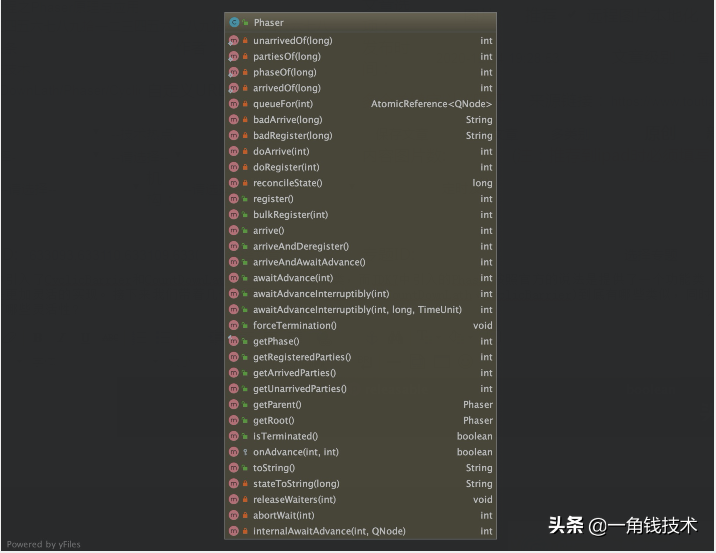
- register(),增加一个参与者,需要同时增加parties和unarrived两个数值,也就是state中的16位和低16位
- onAdvance(int phase, int registeredParties),当前阶段所有线程完成时,会调用OnAdvance()
- bulkRegister(int parties),指定参与者数目注册到Phaser中,同时增加parties和unarrived两个数值
- arrive(),作用使parties值加1,并且不在屏障处等待,直接运行下面的代码
- awaitAdvance(int phase),如果传入的参数与当前阶段一致,这个方法会将当前线程置于休眠,直到这个阶段的参与者都完成运行。如果传入的阶段参数与当前阶段不一致,立即返回
- arriveAndAwaitAdvance(),当前线程当前阶段执行完毕,等待其它线程完成当前阶段
- arriveAndDeregister(),当一个线程调用来此方法时,parties将减1,并且通知这个线程已经完成来当前预警,不会参加到下一个阶段中,因此Phaser对象在开始下一个阶段时不会等待这个线程。
- awaitAdvanceInterruptibly(int phase),这个方法跟awaitAdvance(int phase)一样,不同之处是,如果这个方法中休眠的线程被中断,它将抛出InterruptedException异常。
- getPhase(),当前阶段
- getRegisteredParties(),总数
- getArrivedParties(),到达总数
- getUnarrivedParties(),未到达总数
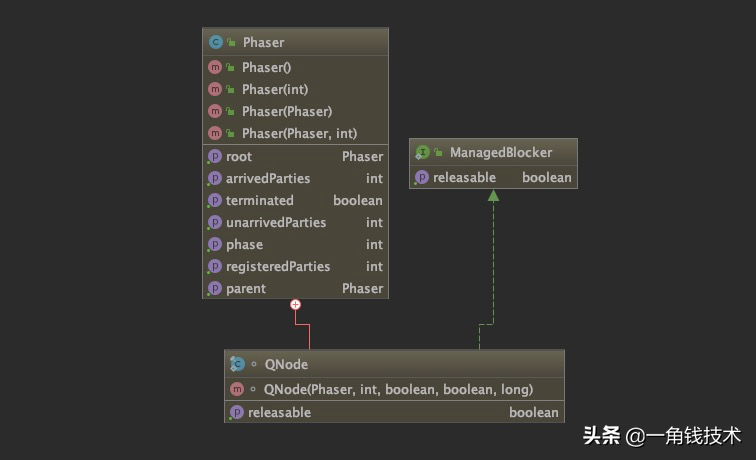
内部类QNode
QNode用来跟踪当前线程的信息的。QNode被组织成单向链表的形式。用来管理是否阻塞或者被中断。
QNode继承自ForkJoinPool.ManagedBlocker。ForkJoinPool来管理是否阻塞和中断状态。这里只需要重写isReleasable和block。
- isReleaseable用于判断是否释放当前节点。
- block用于阻塞。
- static final class QNode implements ForkJoinPool.ManagedBlocker {
- final Phaser phaser;
- final int phase;
- final boolean interruptible;
- final boolean timed;
- boolean wasInterrupted;
- long nanos;
- final long deadline;
- volatile Thread thread; // nulled to cancel wait
- QNode next;
- QNode(Phaser phaser, int phase, boolean interruptible,
- boolean timed, long nanos) {
- this.phaser = phaser;
- this.phase = phase;
- this.interruptible = interruptible;
- this.nanos = nanos;
- this.timed = timed;
- this.deadline = timed ? System.nanoTime() + nanos : 0L;
- thread = Thread.currentThread();
- }
- public boolean isReleasable() {
- if (thread == null)
- return true;
- if (phaser.getPhase() != phase) {
- thread = null;
- return true;
- }
- if (Thread.interrupted())
- wasInterrupted = true;
- if (wasInterrupted && interruptible) {
- thread = null;
- return true;
- }
- if (timed) {
- if (nanos > 0L) {
- nanos = deadline - System.nanoTime();
- }
- if (nanos <= 0L) {
- thread = null;
- return true;
- }
- }
- return false;
- }
- public boolean block() {
- if (isReleasable())
- return true;
- else if (!timed)
- LockSupport.park(this);
- else if (nanos > 0L)
- LockSupport.parkNanos(this, nanos);
- return isReleasable();
- }
- }
整体代码比较简单。要注意的是在isReleasable中使用了thread=null来使得避免解锁任务。使用方法类似于internalAwaitAdvance中的用法。先完成的参与者放入队列中的节点,这里我们只需要关注 thread 和 next两个属性即可,很明显这是一个单链表,存储这入队的线程。
主要属性
- /*
- * unarrived -- 还没有抵达屏障的参与者的个数 (bits 0-15)
- * parties -- 需要等待的参与者的个数 (bits 16-31)
- * phase -- 屏障所处的阶段 (bits 32-62)
- * terminated -- 屏障的结束标记 (bit 63 / sign)
- */
- // 状态变量,用于存储当前阶段phase、参与者数parties、未完成的参与者数unarrived_count
- private volatile long state;
- // 最多可以有多少个参与者,即每个阶段最多有多少个任务
- private static final int MAX_PARTIES = 0xffff;
- // 最多可以有多少阶段
- private static final int MAX_PHASE = Integer.MAX_VALUE;
- // 参与者数量的偏移量
- private static final int PARTIES_SHIFT = 16;
- // 当前阶段的偏移量
- private static final int PHASE_SHIFT = 32;
- // 未完成的参与者数的掩码,低16位
- private static final int UNARRIVED_MASK = 0xffff; // to mask ints
- // 参与者数,中间16位
- private static final long PARTIES_MASK = 0xffff0000L; // to mask longs
- // counts的掩码,counts等于参与者数和未完成的参与者数的 '|' 操作
- private static final long COUNTS_MASK = 0xffffffffL;
- private static final long TERMINATION_BIT = 1L << 63;
- // 一次一个参与者完成
- private static final int ONE_ARRIVAL = 1;
- // 增加减少参与者时使用
- private static final int ONE_PARTY = 1 << PARTIES_SHIFT;
- // 减少参与者时使用
- private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY;
- // 没有参与者使用
- private static final int EMPTY = 1;
- // 用于求未完成参与者数量
- private static int unarrivedOf(long s) {
- int counts = (int)s;
- return (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
- }
- // 用于求参与者数量(中间16位),注意int的为止
- private static int partiesOf(long s) {
- return (int)s >>> PARTIES_SHIFT;
- }
- // 用于求阶段数(高32位),注意int的位置
- private static int phaseOf(long s) {
- return (int)(s >>> PHASE_SHIFT);
- }
- // 已完成参与者数量
- private static int arrivedOf(long s) {
- int counts = (int)s;
- return (counts == EMPTY) ? 0 :
- (counts >>> PARTIES_SHIFT) - (counts & UNARRIVED_MASK);
- }
- /**
- * The parent of this phaser, or null if none
- */
- private final Phaser parent;
- /**
- * The root of phaser tree. Equals this if not in a tree.
- */
- private final Phaser root;
- // 用于存储已经=完成参与者所在的线程,根据当前阶段的奇偶性选择不同的队列
- private final AtomicReference<QNode> evenQ;
- private final AtomicReference<QNode> oddQ;
主要属性位 state 和 evenQ 及 oddQ
- state,volatile的long来表示状态变量,高32位存储当前阶段phase,中间16位存储参与者的数量,低16位存储未完成参与者的数量。
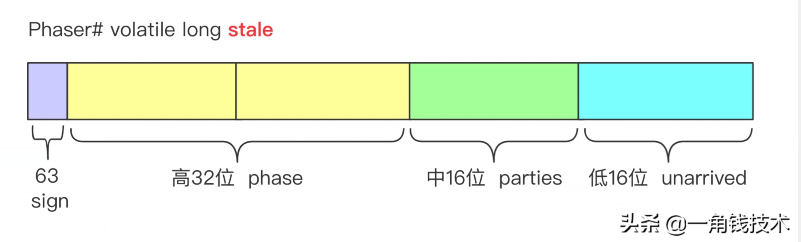
- unarrived -- 还没有抵达屏障的参与者的个数 (bits 0-15)
- parties -- 需要等待的参与者的个数 (bits 16-31)
- phase -- 屏障所处的阶段 (bits 32-62)
- terminated -- 屏障的结束标记 (bit 63 / sign)
如果是空状态,也就是没有子阶段注册的初始阶段。这里用一个EMPTY状态表示,也就是0个子阶段和一个未到达阶段。
所有的状态变化都是通过CAS操作执行的,唯一例外是注册一个子相移器(sub-Phaser),用于构成树的,也就是Phaser的父Phaser非空。这个子相移器的分阶段是通过一个内置锁来设置。
- evenQ 和 oddQ,是根据phaser的奇偶状态来设置的,用来存储等待的线程。为了避免竞争,这里使用了Phaser的数值奇偶来存储,此外对于子相移器,它与其根相移器使用同一个evenQ或者oddQ,以加速释放。
构造方法
- public Phaser() {
- this(null, 0);
- }
- public Phaser(int parties) {
- this(null, parties);
- }
- public Phaser(Phaser parent) {
- this(parent, 0);
- }
- public Phaser(Phaser parent, int parties) {
- if (parties >>> PARTIES_SHIFT != 0)
- throw new IllegalArgumentException("Illegal number of parties");
- int phase = 0;
- this.parent = parent;
- if (parent != null) { // 父phaser不为空
- final Phaser root = parent.root;
- this.root = root; // 指向root phaser
- this.evenQ = root.evenQ; // 两个栈,整个phaser链只有一份
- this.oddQ = root.oddQ;
- if (parties != 0)
- phase = parent.doRegister(1); // 向父phaser注册当前线程
- }
- else {
- this.root = this; // 否则,自己是root phaser
- this.evenQ = new AtomicReference<QNode>(); // 负责创建两个栈(QNode链)
- this.oddQ = new AtomicReference<QNode>();
- }
- // 状态变量state的存储分为三段
- this.state = (parties == 0) ? (long)EMPTY :
- ((long)phase << PHASE_SHIFT) |
- ((long)parties << PARTIES_SHIFT) |
- ((long)parties);
- }
构造函数中还有一个parent和root,这是用来构造多层级阶段的,用于构成树的。
重点还是还是看state的赋值方式,高32位存储当前阶段phase,中间16位存储参与者的数量,低16位存储未完成参与者的数量。
主要方法
下面我们一起来看看几个主要方法的源码,重点是三个private的核心方法:doArrive、doRegister、reconcileState
register方法
增加一个参与者,需要同时增加parties和unarrived两个数值,也就是state中的16位和低16位(中间16位存储参与者的数量,低16位存储未完成参与者的数量)
- public int register() {
- return doRegister(1);
- }
这里主要调用的是doRegister方法,我们往下看。
doRegister方法
- private int doRegister(int registrations) {
- // adjustment to state
- // state应该加的值,注意这里是相当于同时增加parties和unarrived
- long adjust = ((long)registrations << PARTIES_SHIFT) | registrations; //计算出需要调整的量
- final Phaser parent = this.parent; //查看可能存在的相移器
- int phase;
- for (;;) {
- // state的值
- long s = (parent == null) ? state : reconcileState(); // reconcileState()方法是调整当前phaser的状态与root的一致
- // state的低32未,也就是parties和unarrived的值
- int counts = (int)s;
- // parties的值
- int parties = counts >>> PARTIES_SHIFT;
- // unarrived的值
- int unarrived = counts & UNARRIVED_MASK;
- // 检查是否溢出
- if (registrations > MAX_PARTIES - parties) //如果需要注册的数量超过运行注册的最大值,则抛出异常状态异常
- throw new IllegalStateException(badRegister(s));
- // 当前阶段phase
- phase = (int)(s >>> PHASE_SHIFT);
- if (phase < 0) //如果当前状态为终止状态则跳出循环直接退出
- break;
- // 不是第一个参与者
- if (counts != EMPTY) { // not 1st registration //如果当前状态不是第一次注册线程
- if (parent == null || reconcileState() == s) { //如果当相移器的父相移器为空,则直接信息CAS,如果当前相移器部位空则调用reconcileState处理,这个稍后再看。reconcileState这里主要为了防止出现同步性错误。
- // unarrived等于0说明当前阶段正在执行onAdvance()方法,等待其执行完毕
- if (unarrived == 0) // wait out advance
- root.internalAwaitAdvance(phase, null);
- // 否则就修改state的值,增加adjust,如果成功就跳出循环
- else if (UNSAFE.compareAndSwapLong(this, stateOffset,
- s, s + adjust))
- break;
- }
- }
- // 是第一个参与者,当前状态是第一次注册。如果如果当前相移器没有父相移器。则直接进行CAS
- else if (parent == null) { // 1st root registration
- // 计算state的值
- long next = ((long)phase << PHASE_SHIFT) | adjust;
- // 修改state的值,如果成功就跳出循环
- if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))
- break;
- }
- else { // 如果当前是第一次设置,并且该相移器被组织在一个树中则需要考虑一下,则需要使用内置锁来进如
- // 多层级阶段的处理方式
- synchronized (this) { // 1st sub registration
- if (state == s) { // recheck under lock 这里有可能发生竞争。所以这里还需要检查一下,如果失败则需退出同步区重新尝试进入。
- phase = parent.doRegister(1); // 调用其父相移器的注册方法
- if (phase < 0)
- break;
- // finish registration whenever parent registration
- // succeeded, even when racing with termination,
- // since these are part of the same "transaction".
- while (!UNSAFE.compareAndSwapLong
- (this, stateOffset, s,
- ((long)phase << PHASE_SHIFT) | adjust)) {
- s = state;
- phase = (int)(root.state >>> PHASE_SHIFT);
- // assert (int)s == EMPTY;
- }
- break;
- }
- }
- }
- }
- return phase;
- }
增加一个参与者的总体的逻辑为:
- 增加一个参与者,需要同时增加parties和unarrived两个数值,也就是state中的16位和低16位;
- 如果是第一个参与者,则尝试原子更新state的值,如果成功了就退出;
- 如果不是第一个参与者,则检查是不是在执行onAdvance() , 如果是等待onAdvance() 执行完成,如果否则尝试原子更新state的值,直到成功退出;
- 等待onAdvance() 完成是采用先自旋后进入队列排队的方式等待,减少线程上下文切换;
arriveAndAwaitAdvance()方法
当前线程当前阶段执行完毕,等待其他线程完成当前阶段。 如果当前线程是该阶段最后一个到达的,则当前线程会执行onAdvance()方法,并唤醒其它线程进入下一个阶段。
- public int arriveAndAwaitAdvance() {
- // Specialization of doArrive+awaitAdvance eliminating some reads/paths
- final Phaser root = this.root;
- for (;;) {
- // state的值
- long s = (root == this) ? state : reconcileState();
- // 当前阶段
- int phase = (int)(s >>> PHASE_SHIFT);
- if (phase < 0)
- return phase;
- // parties 和 unarrived的值
- int counts = (int)s;
- // unarrived的值(state的低16位)
- int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
- if (unarrived <= 0)
- throw new IllegalStateException(badArrive(s));
- // 修改state的值
- if (UNSAFE.compareAndSwapLong(this, stateOffset, s,
- s -= ONE_ARRIVAL)) {
- // 如果不是最后一个到达的,则调用internalAwaitAdvance()方法自旋或进入队列等待
- if (unarrived > 1)
- // 这里是直接返回了,internalAwaitAdvance()方法的源码见register()方法解析
- return root.internalAwaitAdvance(phase, null);
- // 到这里说明是最后一个到达的参与者
- if (root != this)
- return parent.arriveAndAwaitAdvance();
- // n 只保留了state中parties的部分,也就是中16位
- long n = s & PARTIES_MASK; // base of next state
- // parties的值,即下一次需要到达的参与者数量
- int nextUnarrived = (int)n >>> PARTIES_SHIFT;
- // 执行onAdvance()方法,返回true表示下一阶段参与者数量为0了,也就是结束了
- if (onAdvance(phase, nextUnarrived))
- n |= TERMINATION_BIT;
- else if (nextUnarrived == 0)
- n |= EMPTY;
- else
- n |= nextUnarrived; // n加上unarrived的值
- // 下阶段等待当前阶段加1
- int nextPhase = (phase + 1) & MAX_PHASE;
- // n 加上下一个阶段的值
- n |= (long)nextPhase << PHASE_SHIFT;
- // 修改state的值为n
- if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n))
- return (int)(state >>> PHASE_SHIFT); // terminated
- // 唤醒其它参与者并进入下一个阶段
- releaseWaiters(phase);
- // 返回下一阶段的值
- return nextPhase;
- }
- }
- }
arriveAndAwaitAdvance的大致逻辑为:
- 修改state中unarrived部分的值减1;
- 如果不是最后一个到达,则调用internalAwaitAdvance() 方法自旋或排队等待;
- 如果是最后一个到达的,则调用onAdvance() 方法,然后修改state的值为下一阶段对应的值,并唤醒其它等待的线程;
- 返回下一阶段俄值。
internalAwaitAdvance方法
internalAwaitAdvance方法。实际上Phaser中阻塞都是通过这个语句实现的。这个语句必须通过根相移器调用。换句话说所有的阻塞都是在根相移器阻塞的。
输入参数中phase是需要阻塞的阶段。node是用来跟踪可能中断的阻塞节点。
- // 等待onAdvance()方法执行完毕
- // 原理是先自旋一定次数,如果进入下一个阶段,这个方法直接返回了,
- // 如果自旋一定次数还没有进入下一个阶段,则当前线程入队列,等待onAdvance()执行完成唤醒
- private int internalAwaitAdvance(int phase, QNode node) {
- // assert root == this;
- // 保证队列为空
- releaseWaiters(phase-1); // ensure old queue clean
- boolean queued = false; // true when node is enqueued
- int lastUnarrived = 0; // to increase spins upon change
- // 自旋的次数
- int spins = SPINS_PER_ARRIVAL;
- long s;
- int p;
- // 检查当前阶段是否变化,如果变化了说明进入下一个阶段了,这时候就没有必要自旋了
- while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) {
- // 如果node为空,注册的时候传入的为空
- if (node == null) { // spinning in noninterruptible mode
- // 未完成的参与者数量
- int unarrived = (int)s & UNARRIVED_MASK;
- // unarrived 有变化,增加自旋次数
- if (unarrived != lastUnarrived &&
- (lastUnarrived = unarrived) < NCPU)
- spins += SPINS_PER_ARRIVAL;
- boolean interrupted = Thread.interrupted();
- // 自旋次数万了,则新建一个节点
- if (interrupted || --spins < 0) { // need node to record intr
- node = new QNode(this, phase, false, false, 0L);
- node.wasInterrupted = interrupted;
- }
- } else if (node.isReleasable()) // done or aborted
- break;
- else if (!queued) { // push onto queue
- // 节点入队列
- AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
- QNode q = node.next = head.get();
- if ((q == null || q.phase == phase) &&
- (int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
- queued = head.compareAndSet(q, node);
- } else {
- try {
- // 当前线程进入阻塞状态,跟调用LockSupport.park()一样,等待被唤醒。
- ForkJoinPool.managedBlock(node);
- } catch (InterruptedException ie) {
- node.wasInterrupted = true;
- }
- }
- }
- // 到这里说明节点所在线程已经被唤醒了
- if (node != null) {
- // 置空节点中的线程
- if (node.thread != null)
- node.thread = null; // 被唤醒后,置空thread引用,避免再次unpark
- if (node.wasInterrupted && !node.interruptible) // 不可中断模式下,传递中断
- Thread.currentThread().interrupt();
- if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
- return abortWait(phase); // 依旧没有进入到下一个状态,清除那些由于超时或中断不再等待下一阶段的结点
- }
- // 唤醒阻塞的线程
- releaseWaiters(phase);
- return p;
- }
doArrive方法
doArrive是用来完成任务完成后到达的操作的
- private int doArrive(boolean deregister) {
- int adj = deregister ? ONE_ARRIVAL|ONE_PARTY : ONE_ARRIVAL;//通过传入参数判断有哪些参数需要减1。
- final Phaser root = this.root;
- for (;;) {
- long s = (root == this) ? state : reconcileState();//获取当前状态,以及并解析当前参数。
- int phase = (int)(s >>> PHASE_SHIFT);
- int counts = (int)s;
- int unarrived = (counts & UNARRIVED_MASK) - 1;
- if (phase < 0)//phase为负说明出现特殊情况则将phase返回。
- return phase;
- else if (counts == EMPTY || unarrived < 0) {//如果状态为空或者未到达线程为负,则逻辑上不应该存在线程到达,
- if (root == this || reconcileState() == s)//如果root为this则说明状态出错抛出异常,但是如果该相移器还有父相移器,则还有可能出现相位传播的延迟,这里交给reconcileState来判断,如果依然出现非法状态则抛出异常。reconcileState后面会说到。
- throw new IllegalStateException(badArrive(s));
- }
- else if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s-=adj)) {//完成条件判断后,尝试CAS设置当前状态。
- if (unarrived == 0) {//如果当前到达是该阶段最后一个到达的程序则需要进入下一个阶段。
- long n = s & PARTIES_MASK; // base of next state//保留子阶段数值。
- int nextUnarrived = (int)n >>> PARTIES_SHIFT;//设置下一个阶段你的数值。
- if (root != this)//如果当前phaser有根节点则调用父节点的根节点。
- return parent.doArrive(nextUnarrived == 0);
- if (onAdvance(phase, nextUnarrived))//判断是否可以补进当前节点,实际上这个函数判断是就是nextUnarrived是否是0如果是0则不应该补进,如果不应该补进则返回真,这时候就将phaser终止。这里之所以还专门用一个onAdvance实际上是提供一个hook方法,为后续的实现提供方便。
- n |= TERMINATION_BIT;
- else if (nextUnarrived == 0)//如果不应该终止,而且nextUnarrived又为0,则需要专门设置一个空状态。理由之前说过。
- n |= EMPTY;
- else//当然更普遍的情况下还是只是设置一下下一个阶段未到达线程数量。
- n |= nextUnarrived;
- n |= (long)((phase + 1) & MAX_PHASE) << PHASE_SHIFT;//构造一个新的state变量。并使用CAS的方式去设置他。
- UNSAFE.compareAndSwapLong(this, stateOffset, s, n);
- releaseWaiters(phase);//释放所有等的节点。
- }
- return phase;//返回phase数字
- }
- }
- }
此方法,与arriveAndAwaitAdvance()类似,但不阻塞,可能会有注销操作。
Phaser原理总结
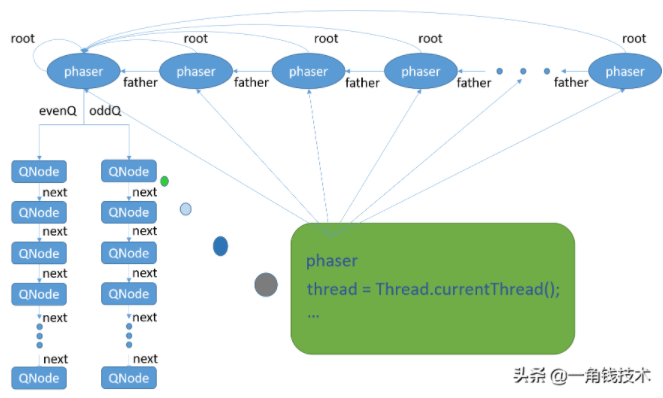
如上图所示,phaser,支持phaser树(图中,简化为phaser链表模式,独子单传,后文也称phaser链)模式,分摊并发的压力。每个phaser结点的father指针指向前一个phaser结点,最前头的结点成为root结点,其father指针指向null, 每一个结点的root指针指向root结点,root结点的root指针指向它自己。
只有root结点的evenQ和oddQ分别指向两个QNode链表。每个QNode结点包含有phaser和thread等关键属性,其中,thread指向当前线程,phaser指向当前线程所注册的phaser。
这两个链表里的线程所对应的phase(阶段)要么都为奇数,要么都为偶数,相邻阶段的两组线程一定在不同的链表里面,这样在新老阶段更迭时,操作的是不同的链表,不会错乱。整个phaser链,共用这两个QNode链。
而且,线程也只会在root结点上被封装进QNode结点入栈(QNode链,入栈,FIFO,后文有时也叫入队,不影响功能),每个phaser在初始时(被第一个线程注册时)以当前线程向其父phaser注册的方式与其父phaser建立联系,当此phaser上的线程都到达了,再以当前线程(最后一个抵达的线程)通知其父phaser,自己这边OK了,每个phaser都以同样的方式通知其父phaser,最后到达root phaser,开始唤醒睡在栈里(QNode链表)的线程,准备进入下一阶段。
phaser的关键属性state,是一个64位的long类型数据,划分为4个域:
- unarrived -- 还没有抵达屏障的参与者的个数 (bits 0-15)
- parties -- 需要等待的参与者的个数 (bits 16-31)
- phase -- 屏障所处的阶段 (bits 32-62)
- terminated -- 屏障的结束标记 (bit 63 / sign)
特别地,初始时,state的值为1,称为EMPTY,也即是unarrived = 1,其余都为0,这是一个标记,表示此phaser还没有线程来注册过,EMPTY = 1,而不是0,是因为0有特殊的含义,可能表示所有的线程都到达屏障了,此时unarrived也为0(而不是初始状态),正常来讲,parties表示总的注册的线程的个数,大于等于unarrived,初始时,parties = 0,而unarrived = 1,更易于辨别。
总结
Phaser
- Phaser适用于多阶段多任务的场景,每个阶段的任务都可以控制的很细;
- Phaser内部使用state变量及队列实现整个逻辑;
- state的高32位存储当前阶段phase,中16位存储当前阶段参与者(任务)的数量parties,低16位存储未完成参与者的数量unarrived;
- 队列会根据当前阶段的奇偶性选择不同的队列;
- 当不是最后一个参与者到达时,会自旋或者进入队列排队来等待所有参与者完成任务;
- 当最后一个参与者完成任务时,会唤醒队列中的线程并进入下一阶段。
Phaser相对于CyclicBarrier和CountDownLatch的优势?
优势主要有两点:
Phaser可以完成多阶段,而一个CyclicBarrier 或者CountDownLatch一般只能控制一到两个阶段的任务;
Phaser每个阶段的任务数量可以控制,而一个CyclicBarrier 或者 CountDownLatch任务数量一旦确定不可修改。
多阶段协同,示意图如下:
参考
https://my.oschina.net/u/4329339/blog/3961164
PS:这里有一个技术交流群(扣扣群:1158819530),方便大家一起交流,持续学习,共同进步,有需要的可以加一下。