一、Spark 介绍及生态
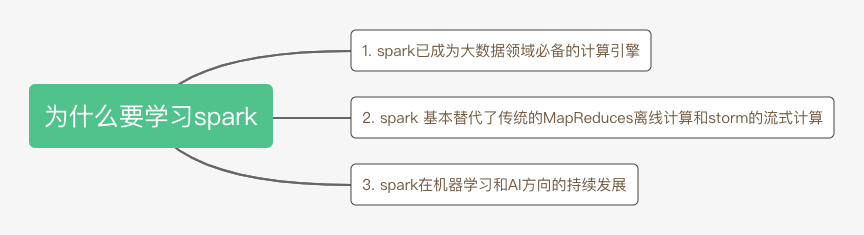
Spark是UC Berkeley AMP Lab开源的通用分布式并行计算框架,目前已成为Apache软件基金会的顶级开源项目。至于为什么我们要学习Spark,可以总结为下面三点:
1. Spark相对于hadoop的优势
(1)高性能
Spark具有hadoop MR所有的优点,hadoop MR每次计算的中间结果都会存储到HDFS的磁盘上,而Spark的中间结果可以保存在内存,在内存中进行数据处理。
(2)高容错
- 基于“血统”(Lineage)的数据恢复:spark引入了弹性分布式数据集RDD的抽象,它是分布在一组节点中的只读的数据的集合,这些集合是弹性的且是相互依赖的,如果数据集中的一部分的数据发生丢失可以根据“血统”关系进行重建。
- CheckPoint容错:RDD计算时可以通过checkpoint进行容错,checkpoint有两种检测方式:通过冗余数据和日志记录更新操作。在RDD中的doCheckPoint方法相当于通过冗余数据来缓存数据,而“血统”是通过粗粒度的记录更新操作来实现容错的。CheckPoint容错是对血统检测进行的容错辅助,避免“血统”(Lineage)过长造成的容错成本过高。
(3)spark的通用性
spark 是一个通用的大数据计算框架,相对于hadoop它提供了更丰富的使用场景。
spark相对于hadoop map reduce两种操作还提供了更为丰富的操作,分为action(collect,reduce,save…)和transformations(map,union,join,filter…),同时在各节点的通信模型中相对于hadoop的shuffle操作还有分区,控制中间结果存储,物化视图等。
2. spark 生态介绍
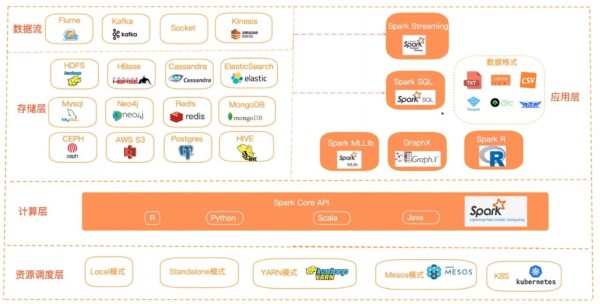
Spark支持多种编程语言,包括Java、Python、R和Scala。在计算资源调度层支持local模式,standalone模式,yarn模式以及k8s等。
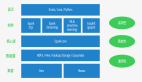
同时spark有多组件的支持应用场景,在spark core的基础上提供了spark Streaming,spark SQL,spark Mllib,spark R,GraphX等组件。
spark Streaming用于实时流计算,spark SQL旨在将熟悉的SQL数据库查询与更复杂的基于算法的分析相结合,GraphX用于图计算,spark Mllib用于机器学习,spark R用于对R语言的数据计算。
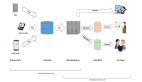
spark 支持多种的存储介质,在存储层spark支持从hdfs,hive,aws等读入和写出数据,也支持从hbase,es等大数据库中读入和写出数据,同时也支持从mysql,pg等关系型数据库中读入写出数据,在实时流计算在可以从flume,kafka等多种数据源获取数据并执行流式计算。
在数据格式上spark也支持的非常丰富,比如常见的txt,json,csv等格式。同时也支持parquet,orc,avro等格式,这几种格式在数据压缩和海量数据查询上优势也较为明显。
二、spark 原理及特点
1. spark core
Spark Core是Spark的核心,其包含如下几个部分:
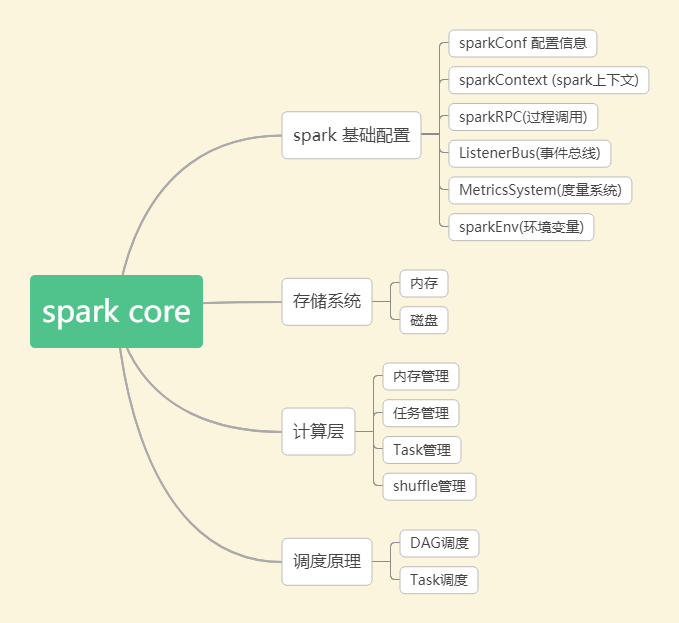
(1)spark 基础配置
sparkContext是spark应用程序的入口,spark应用程序的提交和执行离不开sparkContext,它隐藏了网络通信,分布式部署,消息通信,存储体系,计算存储等,开发人员只需要通过sparkContext等api进行开发即可。
sparkRpc 基于netty实现,分为异步和同步两种方式。事件总线主要用于sparkContext组件间的交换,它属于监听者模式,采用异步调用。度量系统主要用于系统的运行监控。
(2)spark 存储系统
它用于管理spark运行中依赖的数据存储方式和存储位置,spark的存储系统优先考虑在各节点以内存的方式存储数据,内存不足时将数据写入磁盘中,这也是spark计算性能高的重要原因。
我们可以灵活的控制数据存储在内存还是磁盘中,同时可以通过远程网络调用将结果输出到远程存储中,比如hdfs,hbase等。
(3)spark 调度系统
spark 调度系统主要由DAGScheduler和TaskScheduler组成。
DAGScheduler 主要是把一个Job根据RDD间的依赖关系,划分为多个Stage,对于划分后的每个Stage都抽象为一个或多个Task组成的任务集,并交给TaskScheduler来进行进一步的任务调度。而TaskScheduler 负责对每个具体的Task进行调度。
具体调度算法有FIFO,FAIR:
- FIFO调度:先进先出,这是Spark默认的调度模式。
- FAIR调度:支持将作业分组到池中,并为每个池设置不同的调度权重,任务可以按照权重来决定执行顺序。
2. spark sql
spark sql提供了基于sql的数据处理方法,使得分布式的数据集处理变的更加简单,这也是spark 广泛使用的重要原因。
目前大数据相关计算引擎一个重要的评价指标就是:是否支持sql,这样才会降低使用者的门槛。spark sql提供了两种抽象的数据集合DataFrame和DataSet。
DataFrame 是spark Sql 对结构化数据的抽象,可以简单的理解为spark中的表,相比较于RDD多了数据的表结构信息(schema).DataFrame = Data + schema
RDD是分布式对象集合,DataFrame是分布式Row的集合,提供了比RDD更丰富的算子,同时提升了数据的执行效率。
DataSet 是数据的分布式集合 ,它具有RDD强类型的优点 和Spark SQL优化后执行的优点。DataSet可以由jvm对象构建,然后使用map,filter,flatmap等操作函数操作。
3. spark streaming
这个模块主要是对流数据的处理,支持流数据的可伸缩和容错处理,可以与Flume和Kafka等已建立的数据源集成。Spark Streaming的实现,也使用RDD抽象的概念,使得在为流数据编写应用程序时更为方便。
4. spark特点
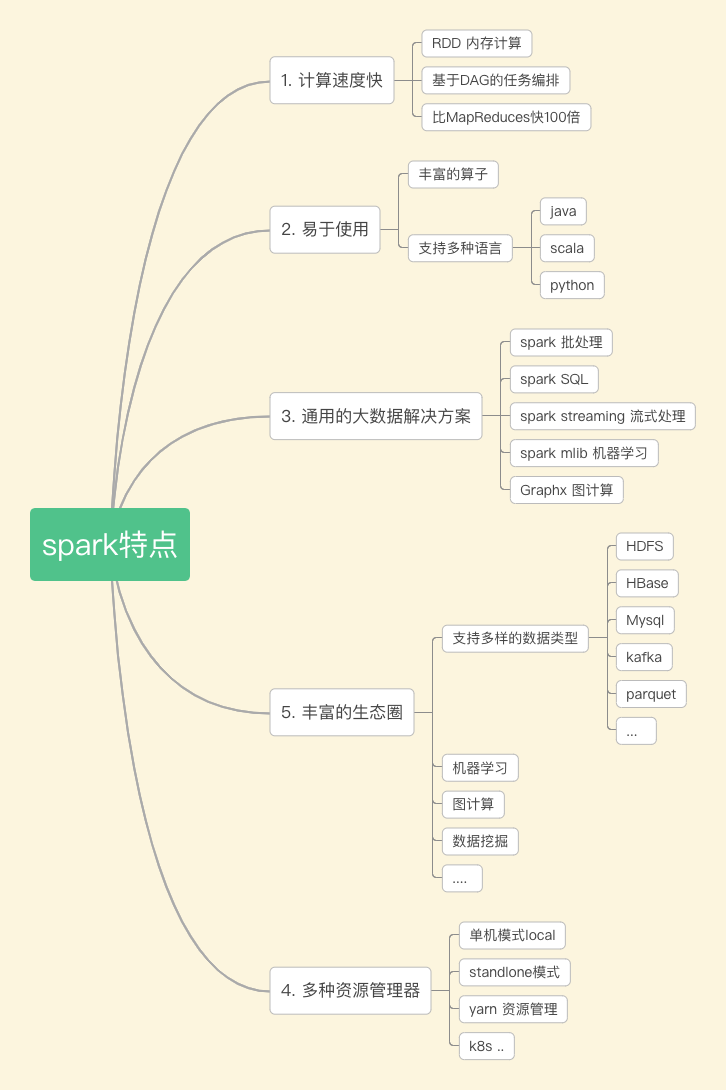
(1)spark 计算速度快
spark将每个任务构建成DAG进行计算,内部的计算过程通过弹性式分布式数据集RDD在内存在进行计算,相比于hadoop的mapreduce效率提升了100倍。
(2)易于使用
spark 提供了大量的算子,开发只需调用相关api进行实现无法关注底层的实现原理。
通用的大数据解决方案
相较于以前离线任务采用mapreduce实现,实时任务采用storm实现,目前这些都可以通过spark来实现,降低来开发的成本。同时spark 通过spark SQL降低了用户的学习使用门槛,还提供了机器学习,图计算引擎等。
(3)支持多种的资源管理模式
学习使用中可以采用local 模型进行任务的调试,在正式环境中又提供了standalone,yarn等模式,方便用户选择合适的资源管理模式进行适配。
(4)社区支持
spark 生态圈丰富,迭代更新快,成为大数据领域必备的计算引擎。
三、spark 运行模式及集群角色
1. spark运行模式

2. spark集群角色
下图是spark的集群角色图,主要有集群管理节点cluster manager,工作节点worker,执行器executor,驱动器driver和应用程序application 五部分组成,下面详细说明每部分的特点。
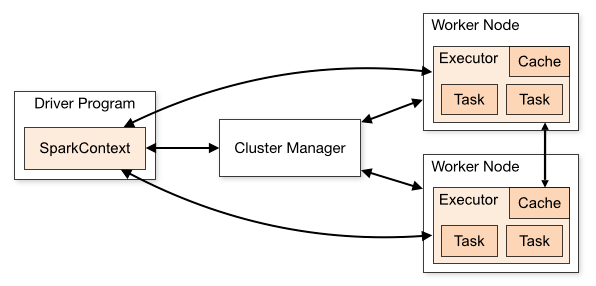
(1)Cluster Manager
集群管理器,它存在于Master进程中,主要用来对应用程序申请的资源进行管理,根据其部署模式的不同,可以分为local,standalone,yarn,mesos等模式。
(2)worker
worker是spark的工作节点,用于执行任务的提交,主要工作职责有下面四点:
- worker节点通过注册机向cluster manager汇报自身的cpu,内存等信息。
- worker 节点在spark master作用下创建并启用executor,executor是真正的计算单元。
- spark master将任务Task分配给worker节点上的executor并执行运用。
- worker节点同步资源信息和executor状态信息给cluster manager。
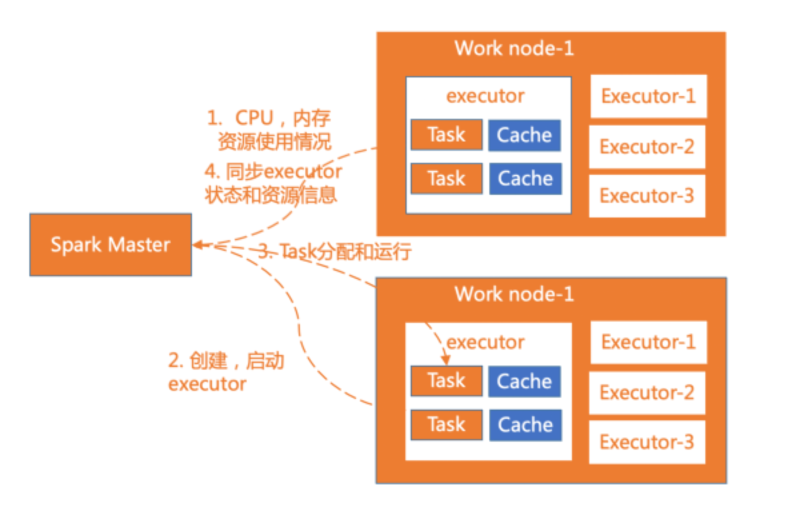
在yarn 模式下运行worker节点一般指的是NodeManager节点,standalone模式下运行一般指的是slave节点。
(3)executor
executor 是真正执行计算任务的组件,它是application运行在worker上的一个进程。这个进程负责Task的运行,它能够将数据保存在内存或磁盘存储中,也能够将结果数据返回给Driver。
(4)Application
application是Spark API 编程的应用程序,它包括实现Driver功能的代码和在程序中各个executor上要执行的代码,一个application由多个job组成。其中应用程序的入口为用户所定义的main方法。
(5)Driver
驱动器节点,它是一个运行Application中main函数并创建SparkContext的进程。application通过Driver 和Cluster Manager及executor进行通讯。它可以运行在application节点上,也可以由application提交给Cluster Manager,再由Cluster Manager安排worker进行运行。
Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调Task的调度。
(6)sparkContext
sparkContext是整个spark应用程序最关键的一个对象,是Spark所有功能的主要入口点。核心作用是初始化spark应用程序所需要的组件,同时还负责向master程序进行注册等。
3. spark其它核心概念
(1)RDD
它是Spark中最重要的一个概念,是弹性分布式数据集,是一种容错的、可以被并行操作的元素集合,是Spark对所有数据处理的一种基本抽象。可以通过一系列的算子对rdd进行操作,主要分为Transformation和Action两种操作。
- Transformation(转换):是对已有的RDD进行换行生成新的RDD,对于转换过程采用惰性计算机制,不会立即计算出结果。常用的方法有map,filter,flatmap等。
- Action(执行):对已有对RDD对数据执行计算产生结果,并将结果返回Driver或者写入到外部存储中。常用到方法有reduce,collect,saveAsTextFile等。
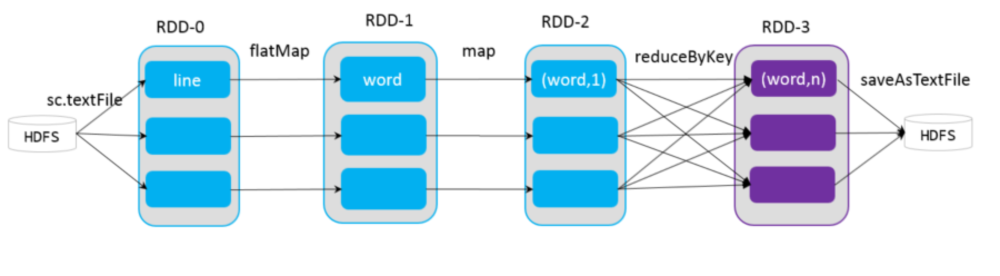
(2)DAG
DAG是一个有向无环图,在Spark中, 使用 DAG 来描述我们的计算逻辑。主要分为DAG Scheduler 和Task Scheduler。
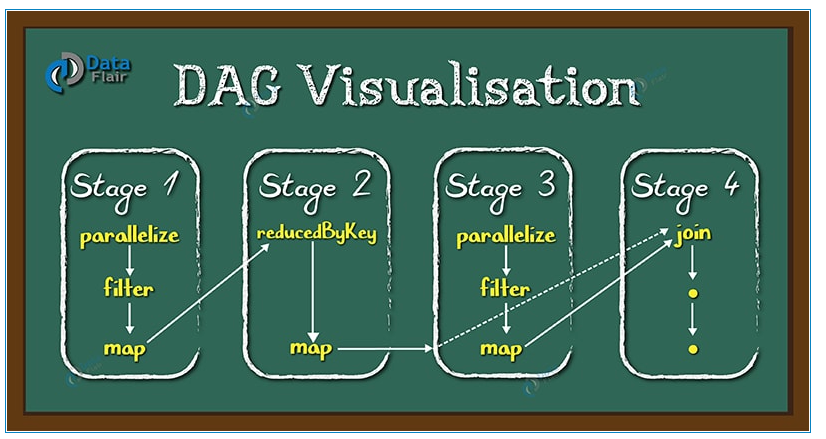
图片出自:https://blog.csdn.net/newchitu/article/details/92796302
(3)DAG Scheduler
DAG Scheduler 是面向stage的高层级的调度器,DAG Scheduler把DAG拆分为多个Task,每组Task都是一个stage,解析时是以shuffle为边界进行反向构建的,每当遇见一个shuffle,spark就会产生一个新的stage,接着以TaskSet的形式提交给底层的调度器(task scheduler),每个stage封装成一个TaskSet。DAG Scheduler需要记录RDD被存入磁盘物化等动作,同时会需要Task寻找最优等调度逻辑,以及监控因shuffle跨节点输出导致的失败。
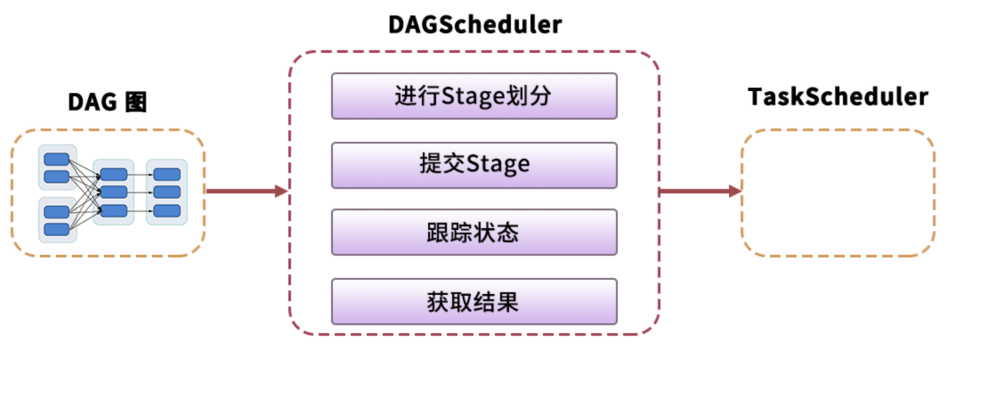
(4)Task Scheduler
Task Scheduler 负责每一个具体任务的执行。它的主要职责包括
- 任务集的调度管理;
- 状态结果跟踪;
- 物理资源调度管理;
- 任务执行;
- 获取结果。
(5)Job
job是有多个stage构建的并行的计算任务,job是由spark的action操作来触发的,在spark中一个job包含多个RDD以及作用在RDD的各种操作算子。
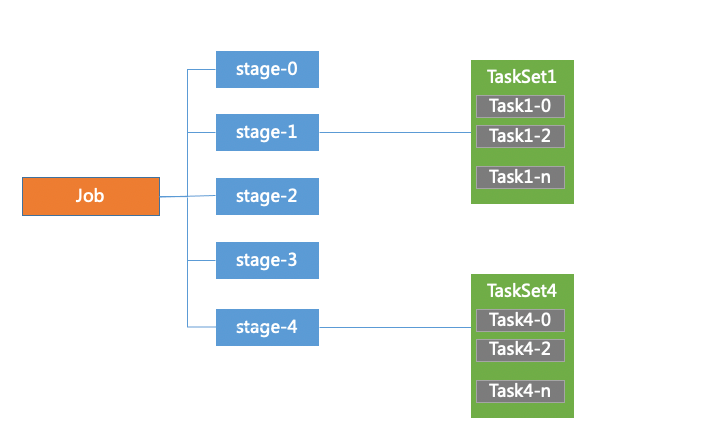
(6)stage
DAG Scheduler会把DAG切割成多个相互依赖的Stage,划分Stage的一个依据是RDD间的宽窄依赖。
在对Job中的所有操作划分Stage时,一般会按照倒序进行,即从Action开始,遇到窄依赖操作,则划分到同一个执行阶段,遇到宽依赖操作,则划分一个新的执行阶段,且新的阶段为之前阶段的parent,然后依次类推递归执行。
child Stage需要等待所有的parent Stage执行完之后才可以执行,这时Stage之间根据依赖关系构成了一个大粒度的DAG。在一个Stage内,所有的操作以串行的Pipeline的方式,由一组Task完成计算。
(7)TaskSet Task
TaskSet 可以理解为一种任务,对应一个stage,是Task组成的任务集。一个TaskSet中的所有Task没有shuffle依赖可以并行计算。
Task是spark中最独立的计算单元,由Driver Manager发送到executer执行,通常情况一个task处理spark RDD一个partition。Task分为ShuffleMapTask和ResultTask两种,位于最后一个Stage的Task为ResultTask,其他阶段的属于ShuffleMapTask。
四、spark作业运行流程
1. spark作业运行流程
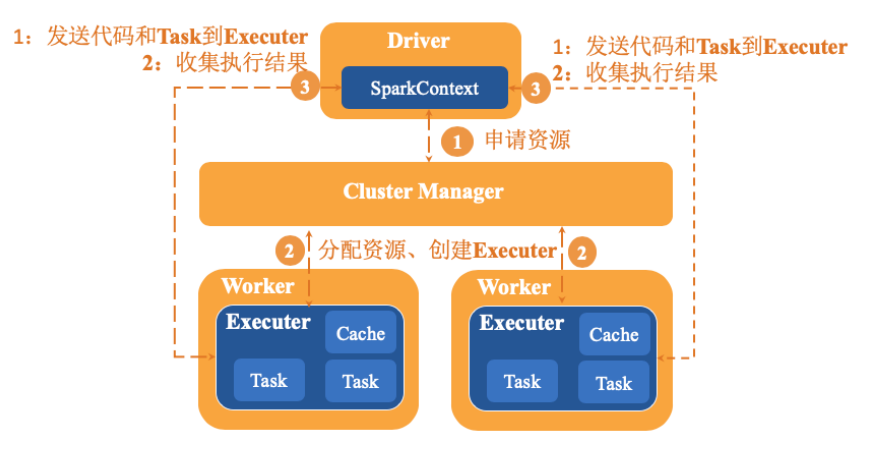
spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建sparkContext的对象与集群进行交互。具体运行流程如下:
- sparkContext向cluster Manager申请CPU,内存等计算资源。
- cluster Manager分配应用程序执行所需要的资源,在worker节点创建executor。
- sparkContext将程序代码和task任务发送到executor上进行执行,代码可以是编译成的jar包或者python文件等。接着sparkContext会收集结果到Driver端。
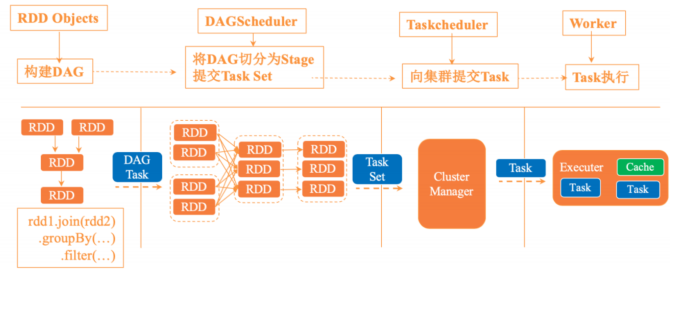
2. spark RDD迭代过程
- sparkContext创建RDD对象,计算RDD间的依赖关系,并组成一个DAG有向无环图。
- DAGScheduler将DAG划分为多个stage,并将stage对应的TaskSet提交到集群的管理中心,stage的划分依据是RDD中的宽窄依赖,spark遇见宽依赖就会划分为一个stage,每个stage中包含来一个或多个task任务,避免多个stage之间消息传递产生的系统开销。
- taskScheduler 通过集群管理中心为每一个task申请资源并将task提交到worker的节点上进行执行。
- worker上的executor执行具体的任务。
3. yarn资源管理器介绍
spark 程序一般是运行在集群上的,spark on yarn是工作或生产上用的非常多的一种运行模式。
没有yarn模式前,每个分布式框架都要跑在一个集群上面,比如说Hadoop要跑在一个集群上,Spark用集群的时候跑在standalone上。这样的话整个集群的资源的利用率低,且管理起来比较麻烦。
yarn是分布式资源管理和任务管理管理,主要由ResourceManager,NodeManager和ApplicationMaster三个模块组成。
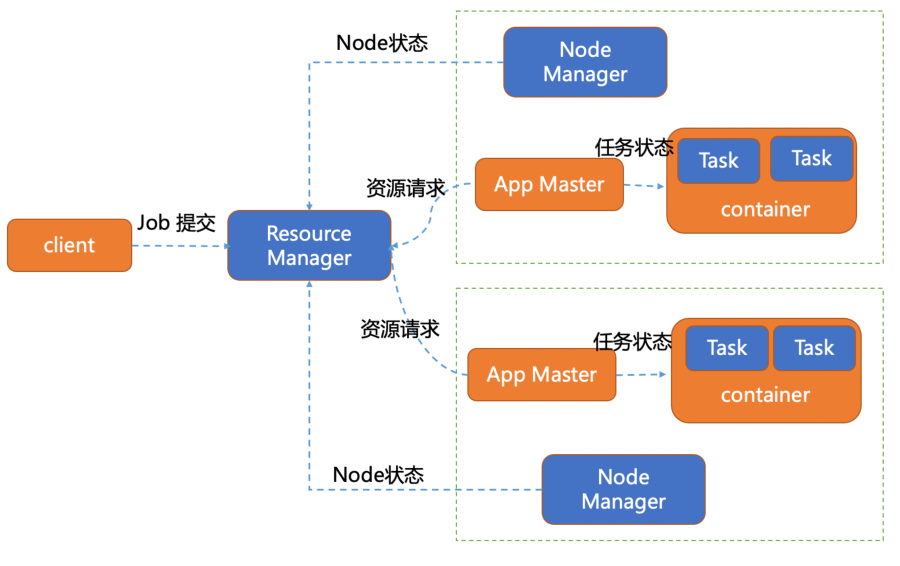
ResourceManager 主要负责集群的资源管理,监控和分配。对于所有的应用它有绝对的控制权和资源管理权限。
NodeManager 负责节点的维护,执行和监控task运行状况。会通过心跳的方式向ResourceManager汇报自己的资源使用情况。
yarn资源管理器的每个节点都运行着一个NodeManager,是ResourceManager的代理。如果主节点的ResourceManager宕机后,会连接ResourceManager的备用节点。
ApplicationMaster 负责具体应用程序的调度和资源的协调,它会与ResourceManager协商进行资源申请。ResourceManager以container容器的形式将资源分配给application进行运行。同时负责任务的启停。
container 是资源的抽象,它封装着每个节点上的资源信息(cpu,内存,磁盘,网络等),yarn将任务分配到container上运行,同时该任务只能使用container描述的资源,达到各个任务间资源的隔离。
4. spark程序在yarn上执行流程
spark on yarn分为两种模式yarn-client模式,和yarn—cluster模式,一般线上采用的是yarn-cluster模式。
(1)yarn-client模式
driver在客户端本地执行,这种模式可以使得spark application和客户端进行交互,因为driver在客户端可以通过webUI访问driver的状态。同时Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加。
(2)yarn-cluster模式
Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台NodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
下图是yarn-cluster运行模式:
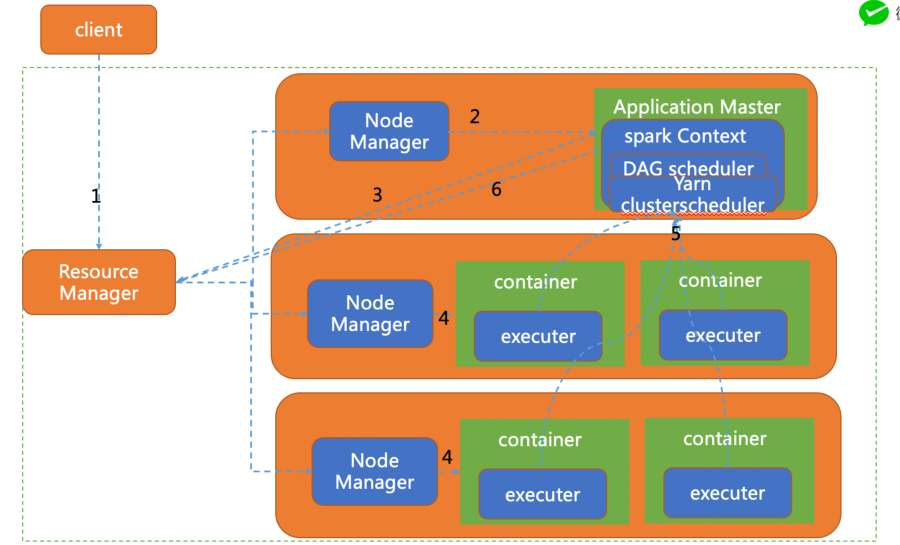
client 向yarn提交应用程序,包含ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等。
ApplicationMaster程序启动ApplicationMaster的命令、需要在Executor中运行的程序等。
ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态。
ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,启动Task。
Task向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。