一 准备数据
1. 创建表和导入一千万条数据
表和数据地址(gitee) https://gitee.com/flowerAndJava/millions_data
2. 大批量数据导入数据
a 将数据库导入服务器中(如果是windows系统,这步省略)
b 创建一个数据库
- 创建数据库(db2),表tb_sku
c 命令行登录数据库
- mysql -u 用户名 -p 密码 ;
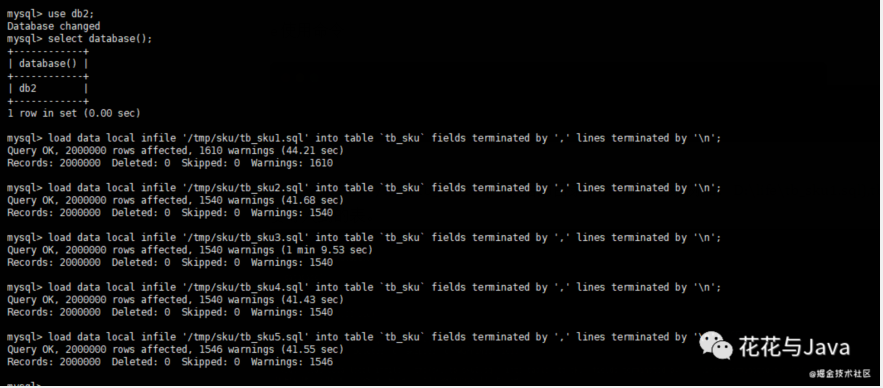
d 切换到使用的数据库
- use db2;
e 使用命令
- load data local infile '/tmp/tb_sku1.sql' into table `tb_sku` fields terminated by ',' lines terminated by '\n';
对命令解释: '/tmp/tb_sku1.sql' 数据的目录(windows目录例如:D:\life\tb_sku1.sql),tb_sku 要导入到的表。
注意: 我们之前使用insert的sql将数据导入到数据库中,但是往库中导入上千万数据会需要很久时间。
二 慢查询分析(查找执行时间长的sql)
2.1 show profiles
show profiles是mysql提供可以用来分析当前会话中语句执行的资源消耗情 况。可以用来SQL的调优测量。
2.1.1 设置MySQL支持profile
1. 查看是否支持
- select @@have_profiling
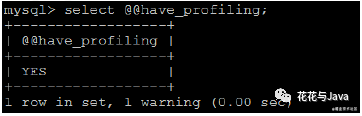
结果为YES,代表支持。
2. 查看profiling(profiling默认是关闭的)
- select @@profiling
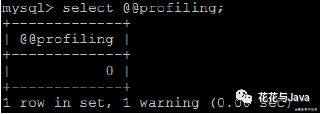
结果为0,代表没有开启3. 开启profiling
- set profiling=1;
2.1.2 show profiles的使用
1. 输入一系列查询语句
- show databases;
- use db01;
- show tables;
- select * from tb_ksu where id < 5;
- select count(*) from tb_ksu;
2. 查看没一条SQL执行时间
- show profiles; //如果执行没有反应,查看profiling是否开启了,命令为select @@profiling;
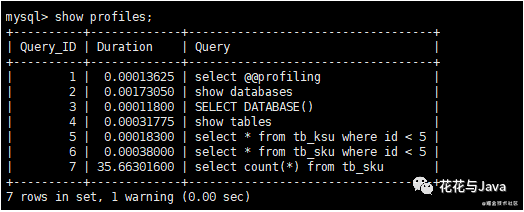
查看没每一条sql执行时间。
3. 查询每一条sql每个阶段执行时间
- select profile for query 6; //6,代表Query_ID
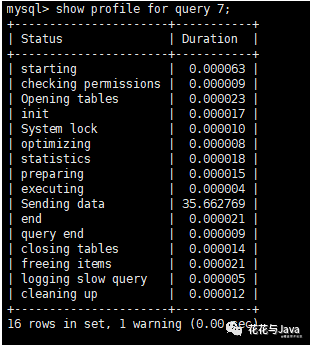
上图解释
- Sending data MySQL线程开始访问数据行并把结果返回给客户端,而不仅仅是
- 返回给客户端。在Sending data状态下,MySQL线程往往进行大量的磁盘读取
- 操作,所以在查询中最耗时的状态。
4. 查看线程在什么资源上耗费过高 (类型 all、cpu、block io 、context、switch、page faults)
- show profile cpu for query 7;
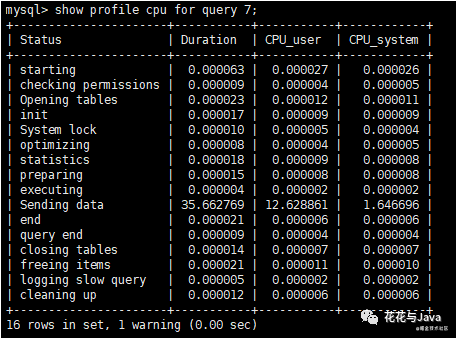
上图说明

2.2 慢查询日志
慢查询日志记录了所有执行时间超过参数(long_query_time)设置值并且扫描 记录数不少于min_examined_row_limit,的所有SQL日志。long_query_time默 认为10秒,最小为0,精度可以到微秒。
2.2.1 设置慢查询日志
1. 修改配置文件(慢查询日志默认关闭的) 修改配置文件命令 vi /etc/my.cnf 然后在配置文件最下方加入下面配置
- # 该参数用来控制慢查询日志是否开启,可取值:1和0,1代表开启,0代表关闭
- slow_query_log=1
- #该参数用来指定慢查询日志的文件名
- slow_query_log_file=slow_query.log
- #该选项用来配置查询的时间限制, 超过这个时间将认为是慢查询, 将进行日志记录, 默认10s
- long_query_time=10
2. 重启mysql服务
- service mysqld restart
备注 如果执行命令报如下错误

请使用命令 systemctl restart mysqld.service
3. 查看慢查询日志目录
- cd /var/lib/mysql
2.2.2 日志读取
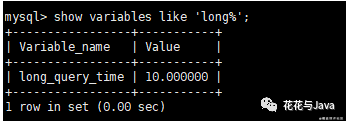
1. 查询long_query_time的值
- show variables like 'long%';
2. 执行查询操作
- select * from tb_sku where id = '100000030074'\G;
- select * from tb_sku where name like '%HuaWei手机Meta87384 Pro%'\G;
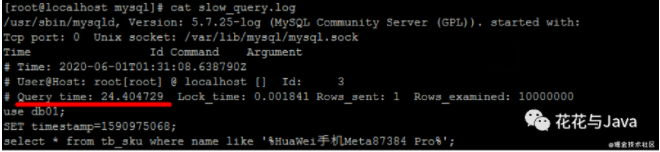
3. 查询慢查询日志
a 使用cat
b 如果慢查询日志很多,借助借助于mysql自带的mysqldumpslow工具,进行分类汇总

三 explain执行计划、索引使用和SQL优化(对某个sql进行分析)
通过以上步骤查询到效率低的SQL语句后,可以通过EXPLAIN命令获取Mysql如 何执行Select语句信息,包含select语句执行过程中表如何连接和连接的顺 序。
3.1 执行explain命令,进行分析
- explain select * from tb_sku where id = '100000030074';

- explain select * from tb_sku where name like '%HuaWei 手机Meta87384 Pro%';

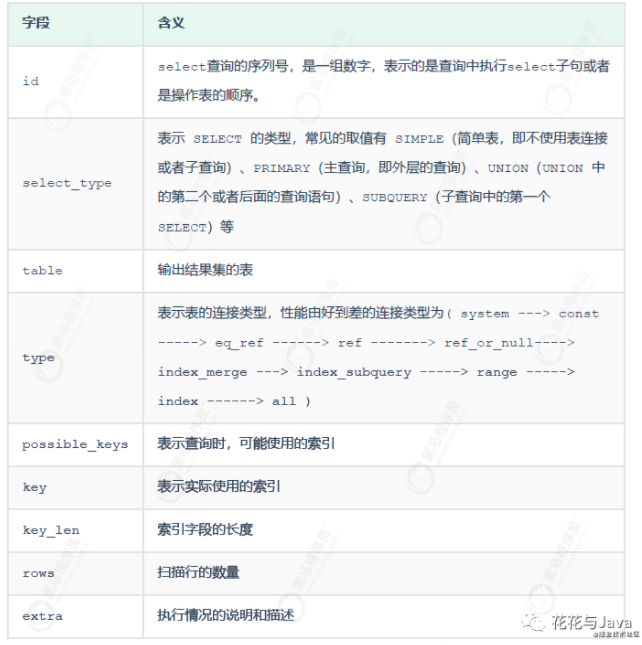
执行计划字段解释
3.2 对字段取值解释
1. id
- A. id 相同表示加载表的顺序是从上到下。
- B. id 不同id值越大,优先级越高,越先被执行。
- C. id 有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,越先执行。
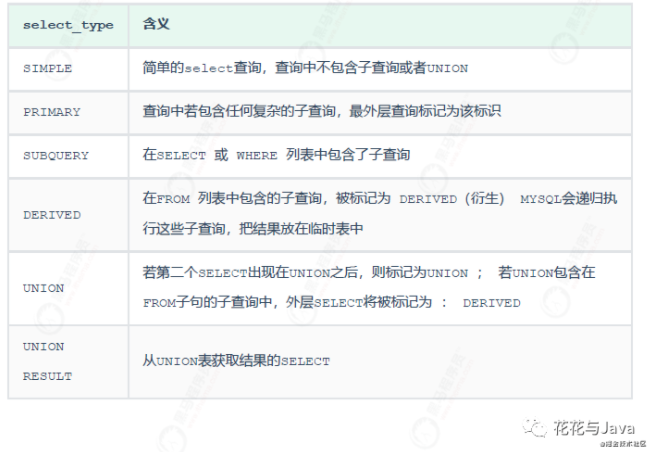
2. select_type
3. type

结果由好到坏
- NULL > system > const > eq_ref > ref > fulltext > ref_or_null > index_merge >unique_subquery > index_subquery > range > index > ALL
- system > const > eq_ref > ref > range > index > ALL
4. key
- A. possible_keys : 显示可能应用在这张表的索引, 一个或多个。
- B. key : 实际使用的索引, 如果为NULL, 则没有使用索引。
- C. key_len : 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。
5. rows
- 扫描行的数量。
6. filtered
- 这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例。