目标检测
目前大部分的目标检测算法都是独立地检测图像中的目标,如果模型能学到目标之间的关系显然对于检测效果提升会有很大的帮助,因此作者希望在检测过程中可以通过利用图像中object之间的相互关系或图像上下文来优化检测效果,这种关系既包括相对位置关系也包括图像特征关系。 关于object的相对位置关系的利用是一个非常有意思的点,尤其是能够实现相对位置关系的attention非常不错的点子。
具体的做法借鉴了attention机制(Attention is all you need)的启发,作者提出一个模块: object relation module来描述目标之间的关系,从而以attention的形式附加到原来的特征上,最后进行回归和分类,另外一个亮点是同时将这种attention机制引入NMS操作中,不仅实现了真正意义上的end-to-end训练,而且对于原本的检测网络也有提升。
值得注意的是:object relation module和网络结构的耦合度非常低,同时输出的维度和输入的维度相同,因此可以非常方便地插入到其他网络结构中,而且可以叠加插入。
作者主要放在两个全连接层后面和NMS模块,如下图中的红色虚线框所示。 在下图中作者将目前目标检测算法分为4步:
- 特征提取主网络
- 得 到ROI及特征
- 基于ROI做边界框回归和目标分类
- NMS处理,去除重复框
从作者的分步情况和源码可以清晰地看出,这篇文章主要是基于Faster RCNN系列算法引入object relation module。

基本框架
提出的Relation Module是对[“Attention Is All You Need”]中提出的“Scaled Dot-Product Attention”模块的改造,其主要作用是建立目标检测任务中不同目标之间的关系,以提高目标检测任务的准确率。
本文使用的是Faster RCNN框架,如下图所示,假设Faster RCNN的RPN模块筛选出N个候选区,在这里就默认每个候选区为一个目标,对每个目标提出其几何特征和形状特征。 其中几何特征通过候选区的边框的坐标进行计算,而形状特征的来源为:Faster RCNN提取出候选框后,需要对每个候选框进行ROI pool 然后经过两个全连接层生成最终的目标类别预测,而在这里形状特征即为中间全连接层的输出,为1维向量。 然后通过目标关系模块建立任意两个目标之间的关系。

在attention is all you need这篇文章中介绍了一个基本的attention模块:scaled dot-product attention,如下所示:

假设输入中有N个目标,那么N个目标的两种特征集合如下所示,f A 是常规的图像特征,f G 是位置特征。

简单的来说公式2中的WV对应上面公式中的V,公式2中的wmn对应上面公式中的softmax()。
归一化操作:

上面公式中的两个变量wG和wA分别表示目标的位置特征权重(geometric weight)和图像特征权重(appearance weight),后面通过如下公式分别得到。


为了使其适应于平移和尺度变换,使用了一个4维的相对几何特征。

综上,可以用下面的Algorithm 1来概括前面提到的公式算法,源码中的实现基本上和Algorithm 1相同。


左图是整体上的attention模块和图像特征fA的融合;右图是attention模块的详细构建过程。
接下来我们说说怎么应用在目标检测算法中了。
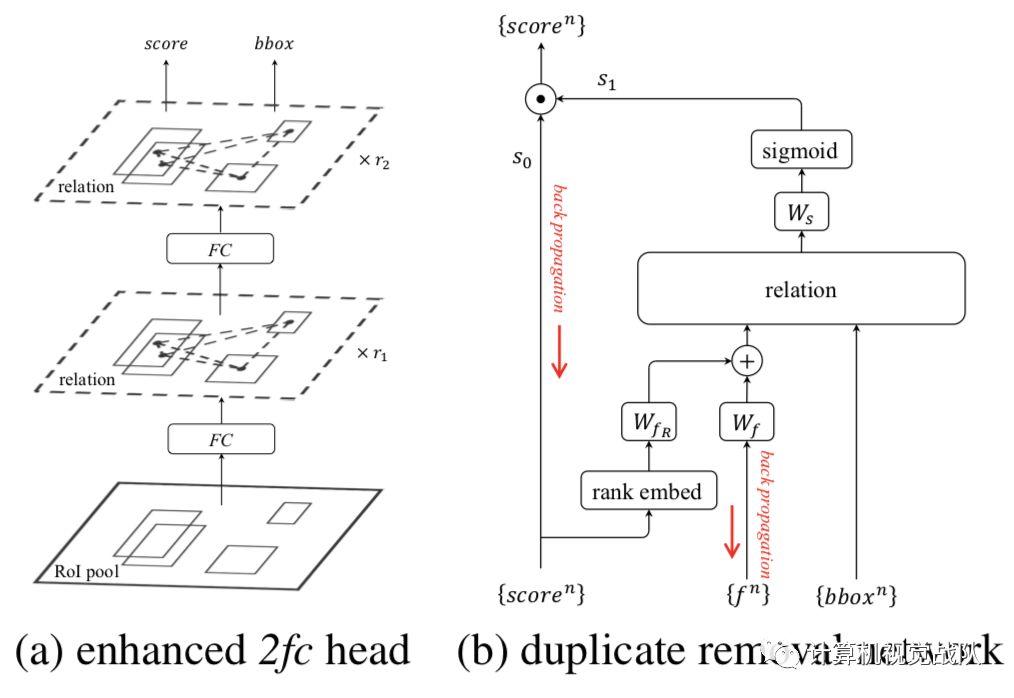
上图是object relation module插入目标检测算法的示意图,左图是插入两个全连接层的情况,在全连接层之后会基于提取到的特征和roi的坐标构建attention,然后将attention加到特征中传递给下一个全连接层,再重复一次后就开始做框的坐标回归和分类。 右图是插入NMS模块的情况,图像特征通过预测框得分的高低顺序和预测框特征的融合得到,然后将该融合特征与预测框坐标作为relation模块的输入得到attention结果,最后将NMS当作是一个二分类过程,并基于relation模块输出特征计算分类概率。
实验

Table1主要做了3个验证:
- 验证引入位置特征(geometric feature)的有效性
- 验证关系特征数量的影响
- 验证relation module在两个全连接层中的数量的影响

表2主要是验证RM效果提升是否是因为参数量增加带来的


关于在不同算法上引入RM的效果
论文地址: https://arxiv.org/pdf/1711.11575.pdf
源码:h ttps://github.com/msracver/Relation-Networks-for-Object-Detection