













本文转载自微信公众号「codeasy」,作者阎华。转载本文请联系codeasy公众号。
使用了DDD(领域驱动设计)后,代码编写有什么不一样呢?这可能是程序员们在接触DDD后最关心的一个问题。这个系列文章会对一些优秀的DDD实例代码进行分析,管中窥豹,略见数斑。这是第四篇,继续以IDDD_Sample为例做分析。
今天我们说一下“读”类型的应用服务怎么设计,以及如何获得更好的性能。
模型设计时不要考虑查询
按DDD设计领域模型时,有两个很有用的原则:
- 模型对展现技术要无感知,比如展现是用WEB,还是APP端,在做模型设计时不要考虑
- 不要关心复杂查询和报表的需求
那这样领域模型设计出来后,经常受到的挑战是查询性能不好。相比于以数据为中心的设计思维,以领域对象为中心的设计思维设计出的数据存储粒度更细,冗余更少,确实不利于查询。
另外一个对查询不友好的地方在于聚合这个概念。比如我想查一个订单列表,列表中的每一行只需要订单这个聚合根的数据,不需要把每一条订单下的子实体都被查询出来,那样性能会很差。
可以使用JPA提供的懒加载来实现只加载聚合根,但是会带来更多的其它的问题,懒加载已被认为是不被推荐使用的反模式。
大部分的业务系统都是读多写少,领域模型是重要,但能提供符合性能要求的查询也很重要。DDD是怎么解决这个矛盾的呢?
模型对查询不友好怎么办
DDD推荐使用CQRS( Command Query Responsibility Segregation, 命令职责分离)这种模式来解决这个问题。
https://martinfowler.com/bliki/CQRS.html
我们来看看IDDD_Sample的 com.saasovation.collaboration.application.forum 下的应用服务,这些服务分成了两类:
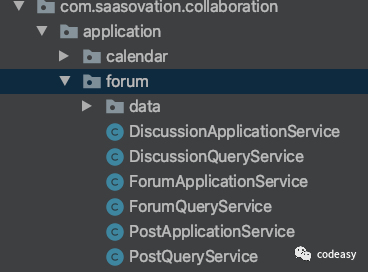
image.png
一类是 ApplicationService 一类是 QueryService 。
ApplicationService里的方法我们上篇文章里见过了,方法的入参是一个 Command 对象,返回值是一个 CommandResponse 对象。方法里通过 Repository 获取聚合根,操作聚合根后,再通过 Repository 来持久化。这就是CQRS里的“C”,即命令(Command),它会改变系统的状态。
在collaboration这个上下文的实现里,没有把入参包装成Command对象,可以参考agilepm上下文中ApplicationService的实现。IDDD_Sample为了演示各种风格,不同上下文的实现方式不太统一。也有人是把这种ApplicationService里的一个个方法变成一个个CommandHandler,可读性更好,但本质上是一样的。
CQRS里的“Q”指的是Query,顾名思义,查询不会改变系统状态的。
那分离是什么意思呢?
最粗浅的理解是把这些查询方法放到 QueryService 里,而不是放到ApplicationService 里。但这只是个表象。我们看一个Query方法是怎么写的:
- public ForumDiscussionsData forumDiscussionsDataOfId(String aTenantId, String aForumId) {
- return this.queryObject(
- ForumDiscussionsData.class,
- "select "
- + "forum.closed, forum.creator_email_address, forum.creator_identity, "
- + "forum.creator_name, forum.description, forum.exclusive_owner, forum.forum_id, "
- + "forum.moderator_email_address, forum.moderator_identity, forum.moderator_name, "
- + "forum.subject, forum.tenant_id, "
- + "disc.author_email_address as o_discussions_author_email_address, "
- + "disc.author_identity as o_discussions_author_identity, "
- + "disc.author_name as o_discussions_author_name, "
- + "disc.closed as o_discussions_closed, "
- + "disc.discussion_id as o_discussions_discussion_id, "
- + "disc.exclusive_owner as o_discussions_exclusive_owner, "
- + "disc.forum_id as o_discussions_forum_id, "
- + "disc.subject as o_discussions_subject, "
- + "disc.tenant_id as o_discussions_tenant_id "
- + "from tbl_vw_forum as forum left outer join tbl_vw_discussion as disc "
- + " on forum.forum_id = disc.forum_id "
- + "where (forum.tenant_id = ? and forum.forum_id = ?)",
- new JoinOn("forum_id", "o_discussions_forum_id"),
- aTenantId,
- aForumId);
- }
来自 ForumQueryService
我们发现这个查询服务里即没有使用领域对象也没使用 Repository ,甚至 join 的两个表是代表两个聚合根的数据!在Query方法里可以直接查询数据库去返回一个查询显示用的DTO,这可以看做是分离的第一个意思,即Query里可以不使用领域对象和 Repository 。
我觉得可以不使用,意味着也可以使用
第二个意思是数据存储的分离。最简单的方式是处理 Command 的 ApplicationService/CommandHandler 访问的是主库,而 QueryService 访问的是从库。
在复杂一点,ApplicationService 可以访问MySQL,而 QueryService 可以访问Elasticsearch这种NoSQL,这时候需要做数据的同步。触发数据同步,可以监听领域事件来实现,也可以使用canal这种框架监听binlog来实现。除了专门为查询而设计的NoSQL本身有更好的查询性能,同时,我们在数据结构设计上也可以专门为查询来做优化,比如把多个关联聚合的数据放到一起。
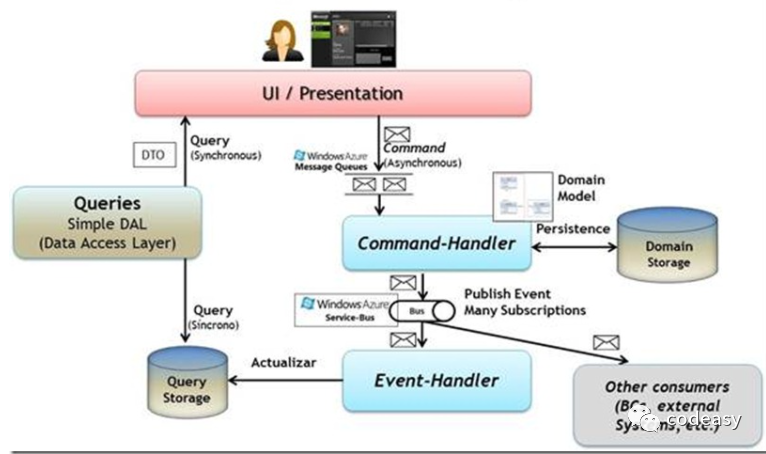
image.png
其实,IDDD_Sample的例子中的 collaboration 这个上下文就是这么实现的——领域对象的存储使用的是LevelDB,查询用的是MySQL。
这种方式我很多年前就看到一个团队在用,他们也把Service分为WriteServcie和ReadService两种,但是并没有叫CQRS这个名字,也没有总结为一种模式,而是凭着经验这么做了。
事件溯源和CQRS
和CQRS经常一起出现的一种模式是事件溯源(Event Sourcing)。事件溯源是一种更“前卫”的模式,它不存储对象的状态,相反,存储影响其状态的所有事件。
需要查询对象的当前状态时,只要把所有事件回放一遍就能得到。但是,这种回放太昂贵了,所以可以保留一份对象的最新快照,这就需要和CQRS模式结合。
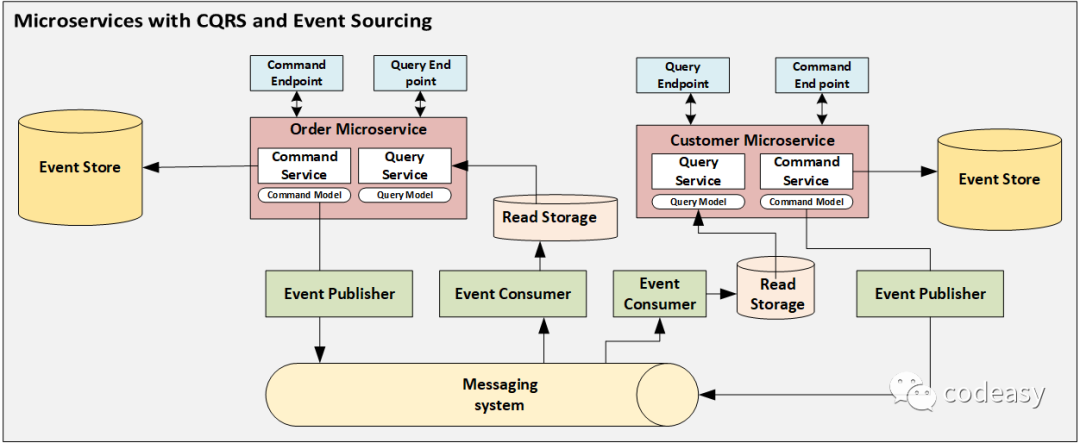
image.png
IDDD_Sample例子中的 collaboration 这个上下文实际上使用的就是事件溯源。我们看它的 Repository 实现,存储的是事件而不是实体本身:
事件溯源加上CQRS很“酷”,但一般不建议使用,实现的成本太高。
- public class EventStoreForumRepository
- extends EventStoreProvider
- implements ForumRepository {
- @Override
- public void save(Forum aForum) {
- EventStreamId eventId =
- new EventStreamId(
- aForum.tenant().id(),
- aForum.forumId().id(),
- aForum.mutatedVersion());
- this.eventStore().appendWith(eventId, aForum.mutatingEvents());
- }
- }
即使是只使用CQRS这一模式,也建议循序渐进,从简单开始,最基本的,把QueryService 和 ApplicationService 分开,且在设计领域模型时不要受 QueryService 设计的影响。


















