













我们来看一个网页,大家想想使用 XPath 怎么抓取。
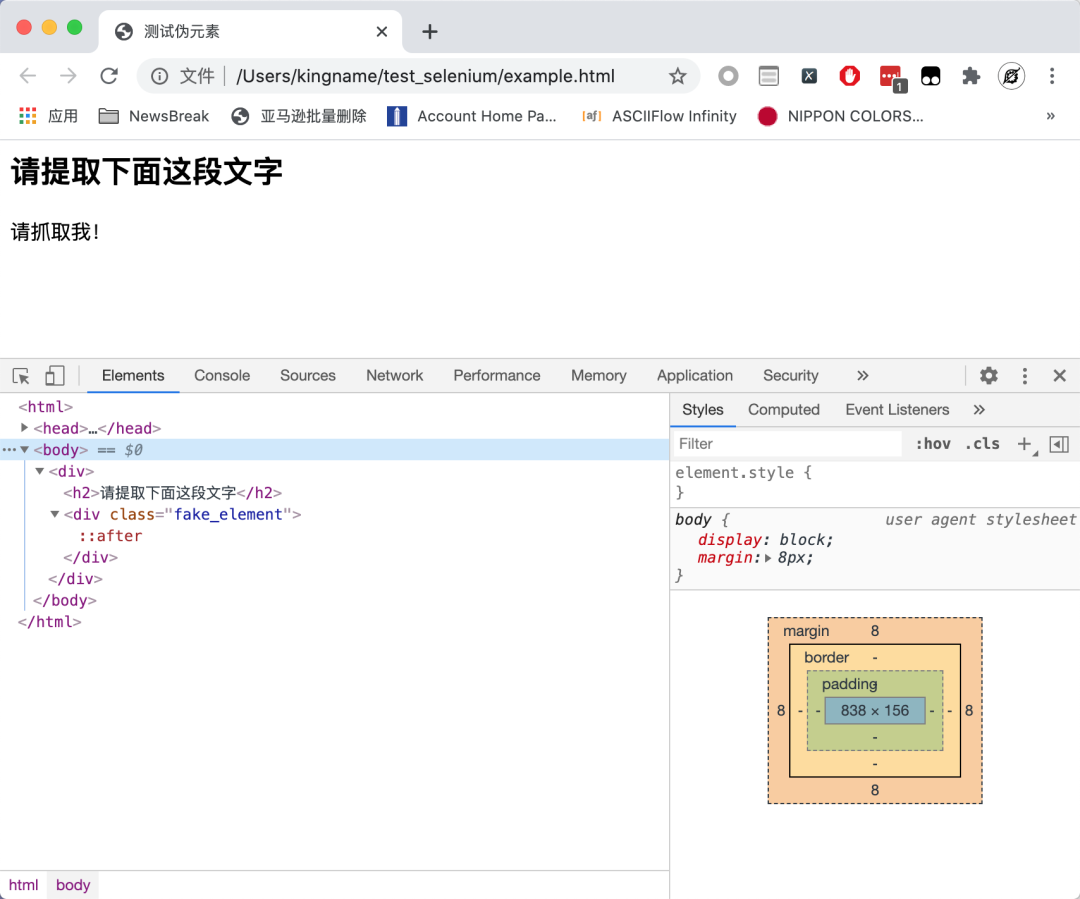
可以看到,在源代码里面没有请抓取我!这段文字。难道这个网页是异步加载?我们现在来看一下网页的请求:
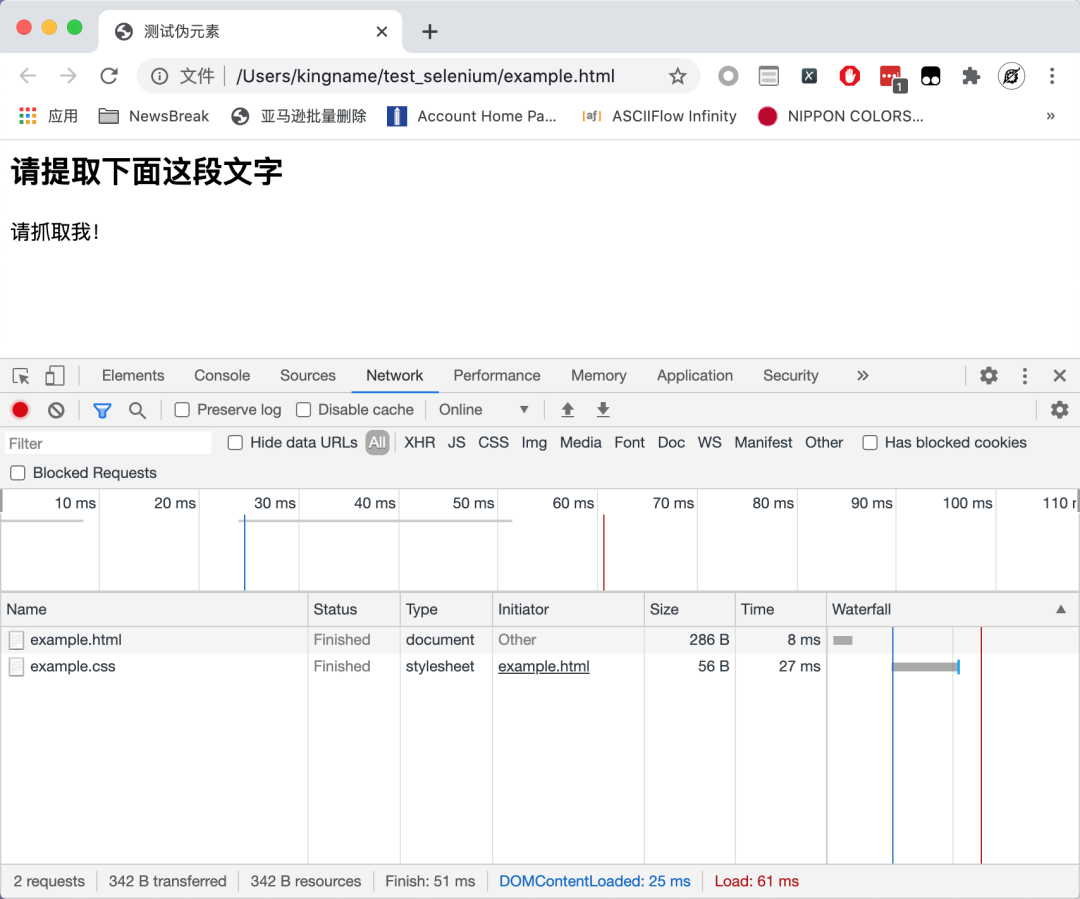
网页也没有发起任何的Ajax 请求。那么,这段文字是从哪里来的?
我们来看一下这个网页对应的 HTML:
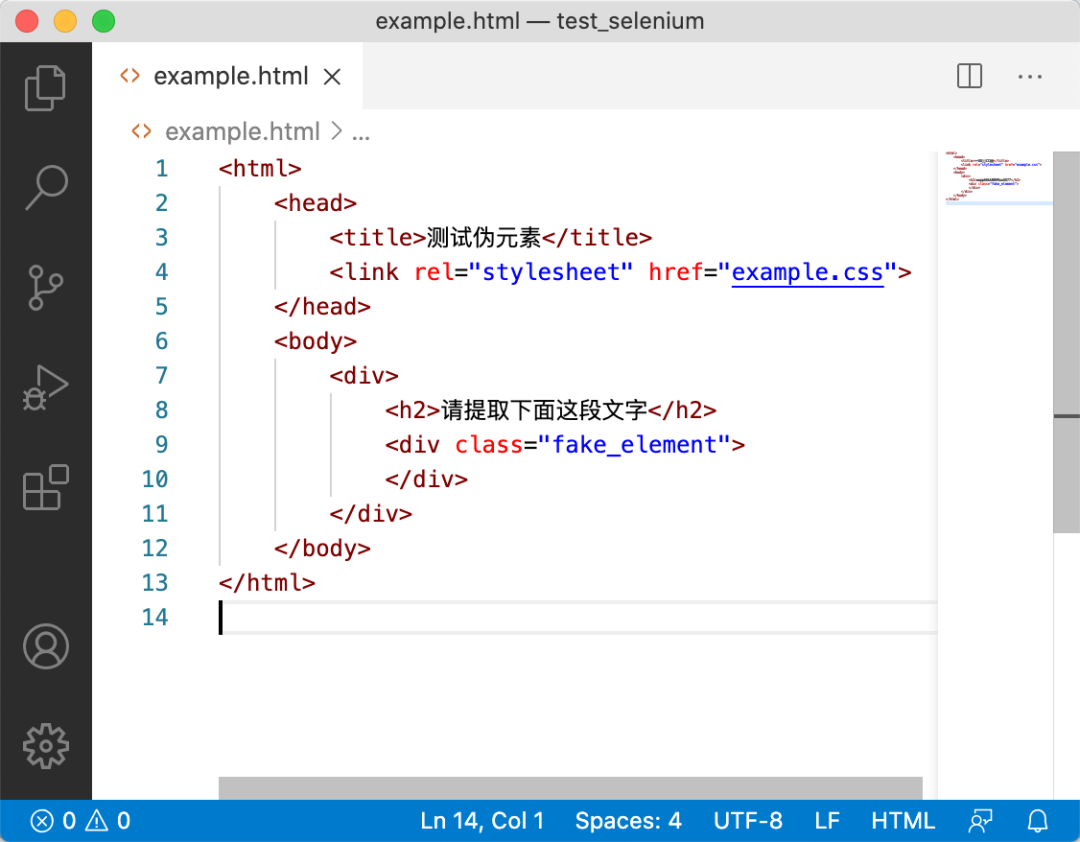
整个 HTML 里面,甚至连 JavaScript 都没有。那么这段文字是哪里来的呢?
有点经验的同学,可能会想到看一下这个example.css文件,其内容如下:
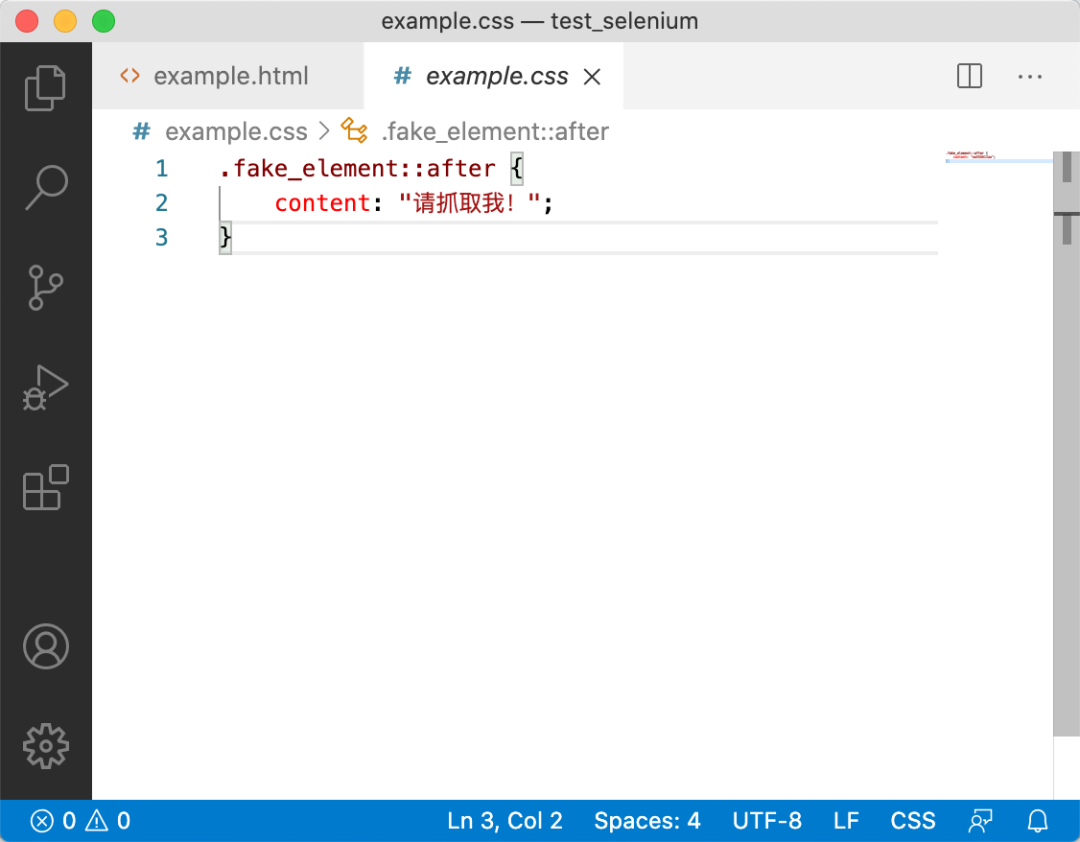
没错,文字确实在这里面。其中::after,我们称之为伪元素(Pseudo-element)[1]。
对于伪元素里面的文字,应该如何提取呢?当然,你可以使用正则表达式来提取。不过我们今天不准备讲这个。
XPath 没有办法提取伪元素,因为 XPath 只能提取 Dom 树中的内容,但是伪元素是不属于 Dom 树的,因此无法提取。要提取伪元素,需要使用 CSS 选择器。
由于网页的 HTML 与 CSS 是分开的。如果我们使用 requests 或者 Scrapy,只能单独拿到 HTML 和 CSS。单独拿到 HTML 没有任何作用,因为数据根本不在里面。单独拿到 CSS,虽然有数据,但如果不用正则表达式的话,里面的数据拿不出来。所以 BeautifulSoup4的 CSS 选择器也没有什么作用。所以我们需要把 CSS 和 HTML 放到一起来渲染,然后再使用JavaScript 的 CSS 选择器找到需要提取的内容。
首先我们来看一下,为了提取这个伪元素的值,我们需要下面这段Js 代码:
window.getComputedStyle(document.querySelector('.fake_element'),':after').getPropertyValue('content')
其中,ducument.querySelector的第一个参数.fake_element就表示值为fake_element的 class 属性。第二个参数就是伪元素:after。运行效果如下图所示:
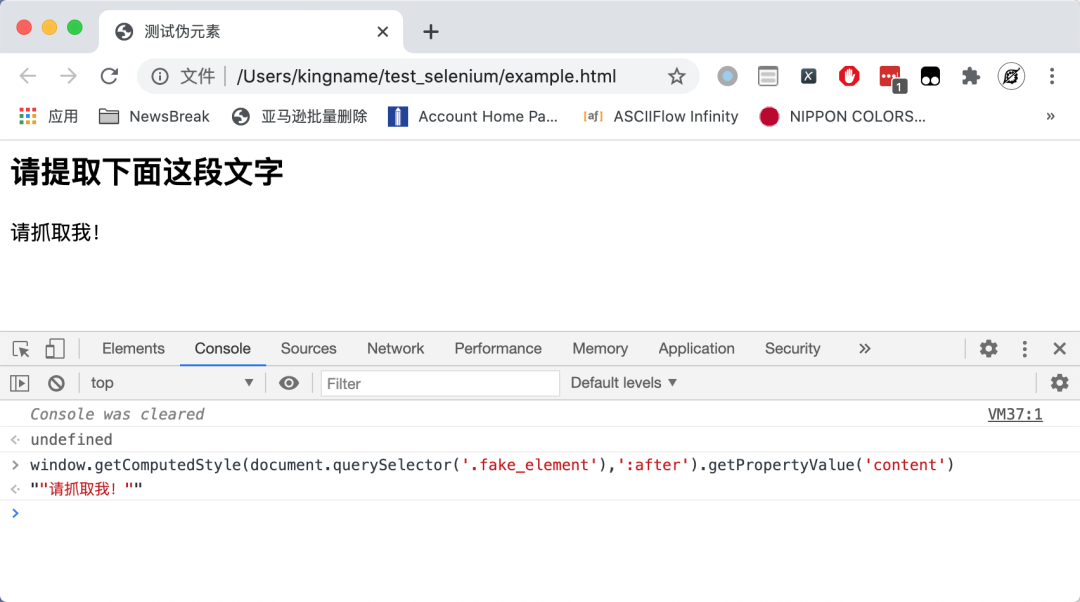
为了能够运行这段 JavaScript,我们需要使用模拟浏览器,无论是 Selenium 还是 Puppeteer 都可以。这里以 Selenium 为例。
在 Selenium 要执行 Js,需要使用driver.execute_script()方法,代码如下:
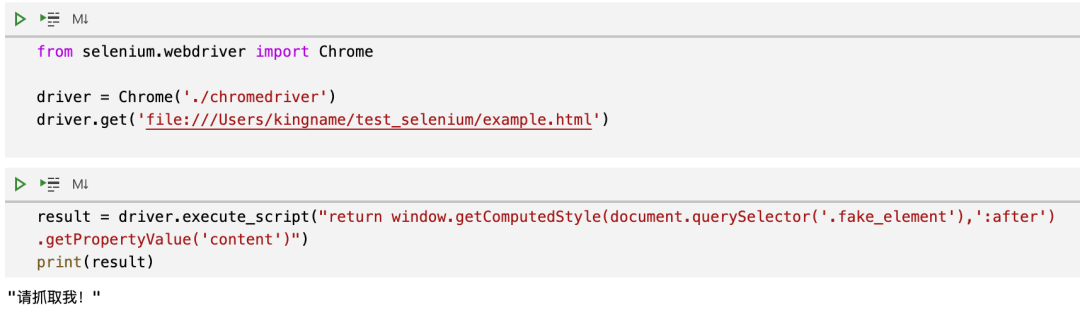
提取出来的内容最外层会包上一对双引号,拿到以后移除外侧的双引号,就是我们在网页上看到的内容了。
参考资料
[1]伪元素(Pseudo-element): https://developer.mozilla.org/zh-CN/docs/Web/CSS/Pseudo-elements
本文转载自微信公众号「未闻Code」,可以通过以下二维码关注。转载本文请联系未闻Code公众号。
























